A few words about juggling
When I was a kid I learned to juggle.
Barely.
I could handle 3 balls for about 30 seconds.
I bluster, that if I practiced, I could handle 5 and go for minutes.
This Reddit thread estimates a week of practice to juggle 3, a month to juggle 4, and a year to juggle 5.
Wikipedia has a whole page on Juggling world records. No one can continuously juggle more than 7 balls. The time record for 7 is 16 minutes. Someone juggled 6 for 30 minutes. The record for 5 is 3 hours and 44 minutes. For 3 it's 13 hours.
The takeaway is this: some humans can juggle more than others but even the greatest max out at 7.
Mental juggling and JIQ
It is not physical juggling that I'm interested in.
I'm interested in mental juggling.
What if humans had the same mental juggling limits as physical?
We could compress the IQ scale to a JIQ scale of 1-7.
A person with a JIQ of 1 could handle only 1 mental ball at a time. Dogs would have a JIQ of 1.
A person with a JIQ of 6 gets overloaded by adding 1 more concept, and the whole thing comes tumbling down.
A person with a JIQ of 7, could handle 7 without becoming overloaded. These would be the geniuses of the world.
You can imagine a superlinear difference between the solutions from a 6 versus a 7.
Where do I rank?
On the JIQ scale, I think I'm a 5. Probably a 4 on a lot of days, and maybe a 6 on a really exceptional day.
I should probably be very grateful for this. Instead, I'm annoyed I'm not a 7. I've encountered a number of 7s in my life, and am in awe--and a bit jealous--of their mental capabilities.
I'm constantly looking for/trying to invent new thinking tools to help me mentally juggle more, to be able to think, if even briefly, as a 7.
Concepts as Balls
Lately I've been exploring a minimal universal 3D/4D language where all concepts are represented by balls.
A simple example is thinking of a water molecule as a ball containing 2 balls of hydrogen and 1 ball of oxygen.
A larger example would be particle physics, where each particle type is a ball. Most people can juggle the simpler 3 ball particle set of electrons, protons and neutrons.
But the current full Standard Model set contains over a dozen balls, which already exceeds humanity's juggling limit:
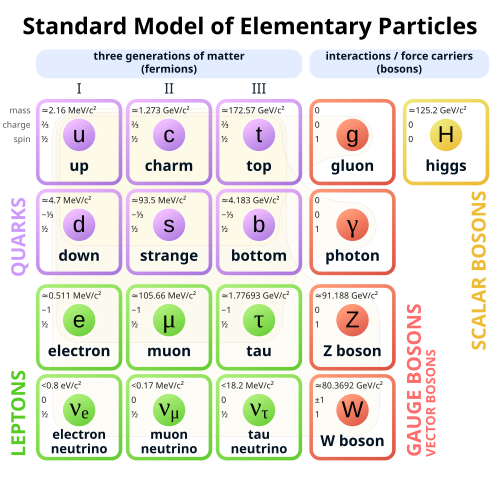
A chart of the Standard Model of Particle Physics. I think each of these also has an anti-particle, but we're already way over the juggling limit.
Trying to Juggle Thousands of Balls
I've been reading microbiology papers and mentally turning each sentence into scenes of balls. Often there are many hundreds of concepts (balls) explicitly discussed in these papers. And not only that, but these concepts depend on other concepts, so there's another 10-100x dependency balls to juggle to fully grok a paper - tens of thousands of balls!
How does one mentally juggle that many?!
With practice you can probably get a little better.
There are probably tricks, such as fasting, that might put your mind in a state that can handle a few more.
But even then, you are orders of magnitude away from being able to juggle everything all at once and so you must focus on one set at a time.
Focusing on Subsets
Humans divide and conquer. Different groups of humans have focused on different, small subsets of balls, mastering those and contributing their insights to the common body of knowledge.
Where should the divisions be? You want to find causally linked subsets. Juggling insulin, toenails, and hair follicles is not as useful as juggling insulin, glucose, and the pancreas.
Collective Juggling
Simple causal models can build upon each other to create things of tremendous complexity.
If you spherically modeled a modern CPU/GPU, you'd have billions of balls, with perhaps a million unique conceptual balls needed to describe it.
No human can juggle that many in their head all at once, but a million humans, each refining and assembling a subset of 5 - 7, can do a collective juggling act that dwarfs any individual performance.
Related posts
- The Spherical Object Model (2025)
- Dreaming of a 4D Wikipedia (2025)
- Does 3D exist? (2025)
- Ford (2025)
Every time I see a school of fish, I'm bewildered by the conformity. Every fish looks and swims the same.
Don't fish have a desire to be individuals? Where are all the contrarians?
Today I coded a little simoji simulation and surprised myself-even well meaning contrarians can cause a lot of damage!
The Simulation
In this very simple sim every fish swims to the edge of the screen.
If every fish conforms every fish makes it safe:
However, if even a single fish gets curious and goes in a contrarian direction, all hell breaks loose:
Takeaways
I have been a brash contrarian in my life. Perhaps too unsympathetic to those following the herd and/or attempting to guide the herd.
While I maintain that the payoffs in nature are extremely variable and warrant thorough exploration of ideaspace, I can see that perhaps I should strive to be a more courtesous contrarian.
To not be contrarian excessively just to practice being contrarian, but to only be contrarian for a few rare ideas, and courteously from the edges.
To explore contrarian ideas while respecting the schools who have gotten us this far.

A language where all concepts are defined out of spheres with radii that accurately contain instances of the concept. In the simple prototype above, spheres are hyperlinked and clicking on one loads and zooms in on its contents.
Imagine a language where the only primitive is the sphere. Everything is composed of spheres. Spheres contain spheres and can be recursive. It's spheres all the way down.
Is this even possible?
So far it seems to me it might be, if you get the "Grammar of Spheres" correct.
All spheres have a diameter. If you use Planck Lengths, base 2, you can use ~206 bits for the size property to cover every sphere up to the sphere of the observable universe.
Recursion is essential. A line sphere is a sphere containing two unit spheres, with a recursive line sphere in between.
Spin might be key (though it may be better to represent spin via an internal "spin state" sphere). A NAND gate could be 2 input spheres with a spin which touch an output sphere that only changes spin if both input spheres are going in the right direction. Numeral base systems could be represented with spin or internal state spheres.
Spheres would abut input and output spheres. A human sphere would have input sphere for oxygen, food, water, etc, and output spheres for carbon dioxide, waste, and so on.
Time spheres would contain spheres of a concept at different times. Ie., humans would have an embryo, infant, toddler, and adult sphere, among others.
Even ideas would be represented as spheres. Ideas would be spheres inside neuron spheres, perhaps.
I haven't yet been able to use only spheres to model electromagnetic fields accurately, but it feels doable.[2]
What would the source code for a Spherical Object Model look like?
It would be very similar to the DOM, with spheres instead of rectangular divs as the primitive.
The code for the water molecule above looks like:
waterMoleculeSphere
oxygenSphere
radius 1.5
x 0
y 0
z 0
leftHydrogenSphere
radius 1
x 1.5
y 1.5
z 0
rightHydrogenSphere
radius 1
x -1.5
y 1.5
z 0
Nailing the semantic details would be essential, but I think the standard language wouldn't look more complex than that.
What about the dozens of existing 3D languages[1]?
Existing 3D languages are generally domain specific (like in chemistry) or focused on representing the visuals of scenes, for film or video games, and not on the causal relationships between objects that this would be. The Spherical Object Model would be a domain-agnostic, general purpose language containing the spherical primitives that can model all the causal patterns in our universe.
Why only one primitive?
In my mind's eye I can instantly, and in parallel, draw spheres around the boundaries of all objects I see. It seems I can visualize hundreds, if not thousands or more, spheres at once. This parallelization capability goes away if I were to add even one more shape, such as the cube. I then need to consciously decide whether each object should be surrounded by a sphere or a cube, and it becomes more of a sequential process. It seems a single primitive allows for a massive parallelization speedup.
Of the various primitives, why the sphere, as opposed to the cube?
I think the sphere is the obvious choice, since it is easy to construct other primitives out of them, and in my experience spheres are far more common in nature than other 3D shapes.
Why not point clouds?
As far as I can figure, everything in this world needs to take up space. Spheres are points that take up space. As the bit is the primitive in one dimension, the sphere seems to be the primitive in 3 dimensions.
Why would we want this?
A universal spherical language would be grounded to reality in a way that no other language is. We could sort all concepts across all domains by their size and/or frequency in the real world.
It might take longer, at first, to build up a shared 4D encyclopedia, but the physical constraints from the 4D laws of nature would force it to contain a truth that can't be matched by lower dimensional languages. Just as a Mercator projection contains unavoidable bias, so does a flat encyclopedia relative to a spherical one.
It is extremely easy to build false models out of words, so switching to a well-designed sphere based language might be a radically better way to create and communicate true models.
Reader Comments
What do you think? Send feedback you'd like me to post to breck7@gmail.com, or add your comment by editing the source to this post.
- A reader points out the relevance of Leibniz' La Monadologie (1714). I had overlooked that work by Leibniz before. I now have read this translation. Extremely interesting. The same reader points out potential connection to Tim Morton's hyperobjects.
- gwern points out the relevance of "epicycles/Fourier decomposition, Gaussian splatting". Playing with Gaussian splats in part encouraged me to try using spheres as the primitive. I particularly enjoyed this overview.
- A reader suggests the reason for spheres is they are "the most efficient container". Their perspective is its not spheres all the way down, it's pattern recursion, and spheres are just "the most elegant expression of those patterns". I'm not sure about the deeper idea, but I love the line about container efficiency. That is a good exercise to do: given a bunch of naturally observed patterns, see which primitive shape has the best efficiency as a container. Spheres seem like they would minimize the surface area of the containers and you also don't need to worry about orientation (just position and size).
- Stens points out the connections to BORO, an ontological method "grounded in physical reality ", which is based on the principle of extension ("taking up space").
- Bruce provided detailed feedback on all parts of the post, and pointed me to related topics like covering and tesselation and tiling. He pointed out the key question is where there is "a thinking advantage" to thinking in spheres.
- Maciek pointed me to the highly relevant "holons" and "holarchies":

- A tangental note from Anton makes me wonder if angular diameter would be a useful primitive to keep in mind.
- Another way to frame this idea could be an attempt to come up with a simple grammar to allow the techniques of finite element method/discrete element method to be more widely applied. FEM is "the mesh discretization of a continuous domain into a set of discrete sub-domains, usually called elements."
[1] The list of 3D languages I've studied to date.
[2] It also seems like what I'm talking about is reviving Newton's corpuscular theory of light.
I just got back from the future where they had the most incredible device.
It was a large black tabletop that generated animated 3D holographic projections above it.
I interacted with it via voice. "Show me an apple", I said, and a floating red apple appeared.
Then I turned a knob left and the apple turned green and shrank and rose in the air and down came a branch and now the two were attached.
Then I turned the knob right and the apple went back to red and I kept turning and it turned brown and shrivelled and died.
I turned it back and then pinched my hands to zoom in and soon I could see cells and then I tapped on a cell with my finger and it zoomed in and I could see the organelles and I tapped further still until I was looking at the electrons and protons in the atoms of a strand of DNA of this appley apparition.
I then spread my hands and zoomed back out and got back to the branch and tapped it and now was looking at an apple tree and I turned the knob left and watched the tree fold all the way into a seed.
I had been so preoccupied looking at the center of the table that I had failed to notice a holographic human appearing to observe the seed.
I tapped the human and then the whole scene moved and he was now in the center.
I turned the knob left and watched as he shrunk down to a boy then a toddler than a fetus and embryo, the machine autozooming in as his size became microscopic. I turned back to the adult man.
I then said "Show me the man eating an apple pie", and watched as a holographic apple pie appeared and the man used a fork to lift a piece to his mouth and then the simulated camera equipped with floodlights entered his mouth and we could see his teeth chomping the pie to bits and then the camera followed the crumbs down the esophagus and into his stomach and we could see acid breaking down the crumbs and transporting food molecules to the liver and the molecules entering the cells and then the mitochondria and then I finally said "PAUSE".
And then, "show me the apple pie being made from scratch".
And then I watched in awe as the scene rewound to the pie and then showed it coming out of an oven and then split into many scenes some showing the apples being gathered and others showing the oven being assembled and then others showing men sailing across the seas in wooden ships and then others showing tiny saplings spreading across the forest floor and then others showing clumps of cells joining together and then others showing cells eating mitochondria and then others showing asteroids pelting the earth and then fields of cosmic dust and then a beautiful bright flash.
Related posts
I just watched a great presentation from Jon Barron (of NeRF fame).
Deep neural networks can now generate video nearly indistinguishable from "real" world video and/or video generated from 3D engines.
Does this provide evidence that the 3D/4D world doesn't actually exist?
What is at the root of our conscious experience?
I can see at least 2 possible topological orderings:
4dSpaceTime
mind
4dSpaceTimeModelor
generator
mind
4dSpaceTimeModelIn the latter you are observing not a real 4D world but the generative output of some kind of network.
In (1) you have a 4d universe and light rays bounce around and hit observers who form a model of that 4d world; in (2) you don't actually have light rays or spacetime, you just generate signals to the observer's inputs and somehow we came up with the spacetime model.
When you turn your head, are you seeing new light rays or is the generator giving you simulated values?
These ideas are so far upstream they are probably unanswerable, so why think about it?
Well, I came across this talk while working on a new language for the 4D world.
If the 4D world is actually "fake", and the world is neural network generated, then that might be a waste of time.
For now I still strongly lean in favor of spacetime being real but at least I'm aware of another possibility.
- Juggling Ideas (2025)
- The Spherical Object Model (2025)
- Dreaming of a 4D Wikipedia (2025)
- Ford (2025)
People were surprised that AI has turned out to make information workers obsolete before laborers, but I'm not.
Information is the easiest job.
I laugh at the obliviousness of the photographer who snaps a photo of the Golden Gate Bridge and demands copyrights and royalties, as if that task was harder than the years of labor by thousands building it (some of whom lost their lives).
Information is the easiest job.
Who worked harder, the men that spent years leveling a path through the forest and mountains to build a road, or the guy who makes an SVG representation of the road for a digital map?
Information is the easiest job.
I enjoy thinking about information. I like to write. I like to find new ideas and digest them and rotate them and tear them apart and put them back together.
But not for a moment do I think information jobs are harder than the physical labor jobs I did in the past, or that others are doing all around me.
That's why I put out all of my work to the public domain. I wouldn't dare throw a "copyright" sign on my work, or a "license", and pretend like my job is so special that I deserve to restrict the freedoms of others.
The janitor does not demand royalties when I walk into a clean room; the plumber does not demand royalties when I flush the toilet; the electrician does not demand royalties when I turn on a switch; the furniture maker does not demand royalties when I sleep on a bed; the shoemaker does not demand royalties when I go for a walk.
Why on earth should I demand royalties when someone uses my outputs?
Especially since information is the easiest job.
I do want to get paid to produce solid information. I sell things of various sorts. I find information work that needs to be done and deliver. I push myself to always be improving my skills so I can make the best information I can.
But I don't expect the absurd salaries of the old days.
Why have information workers been paid so much, relative to other professions?
Corruption.
The people who make the laws (lawyers) are information workers, and so unsurprisingly they made unnatural laws to benefit themselves.
They made information jobs far harder than they should be. Instead of encouraging collaboration they encouraged silo'd work and unnatural monopolies.
The people who inform the public (medias) are also information workers, and so unsurprisingly they misled the public not to oppose these laws.
But now AI has come along, and has ignored these unnatural laws (and just trained on everything, ignoring the information laws us humans are shackled with), and shown what a farce these high salaries for the easiest jobs have been.
My advice to information workers is this: keep in mind that information is the easiest job.
If your job is information, do it to the best of your ability, like you would want anyone else to do their job.
Don't expect the monopoly salaries of old. It wasn't honest before and now the truth is harder to hide.
And please, do your best to publish your information in the most honest format: unencumbered by "licenses"; clean source code; auditable change history.
It's an easy job, but it's even easier if we all do it right, and work together.
Deceptive intelligence is when an agent emits false signals for its own interests, contrary to the interests of its readers. Genuine Intelligence is one where an agent always emits honest symbols to the best of its ability, grounded in natural experiment, without any bias against its users.
Artificial intelligence is here and very powerful.
Will we have Deceptive Intelligences or Genuine Intelligences?
It seems to me closed source intelligences are bound to be Deceptive Intelligences.
Think about a closed system prompt or fine-tuning stage. It is extremely easy for a powerful entity (such as a government), to influence what happens in those stages, and thus quietly mislead the people downstream.
(It's interesting to realize that even before AI, we already had what served as a "system prompt", where the powers that be would apply hidden pressures to the major media organizations to generate news and media with specific slants.)
How is an individual to protect themselves against Deceptive Intelligences?
It seems to me like legalizing intellectual freedom and having powerful, fully open source, local AIs would help.
Would that be enough?
Sometimes I wonder if the inherent black-box nature of neural networks means there will always be a place for the DI to hide.
In that case the question is: is it possible to build a purely symbolic intelligence that could be competitive against neural nets?
A fully open and understandable (but massive), organization of symbols that provides the knowledge and expertise benefits of AIs but in a Genuine Intelligence form factor?
Symbolic AI was hot, then fell way behind neural networks, but neural networks have had a trillion dollars plowed into them.
Could symbolic AI make a comeback? If you plowed enough brain power and resources into symbolic AI (including using a lot of LLMs to help write it), could you make one competitive to neural networks and more of Genuine Intelligence?
Or is there something inherently worse about symbolic AI?
I'm genuinely not sure. :)
Why do I worry about this?
Simply because I'm a huge outlier in terms of amount of time I've put into studying and experimenting with symbolic technology, and feel some responsibility to help make it work, if it actually can work (rather than just go off and bow to our new neural network overlords :) ).
- Human population has grown exponentially.
- Words are 2D signals that can convey information about the 4D world.
- The maximum number of words generated per year is a constant times human population.
- Written words persist and so the maximum number of written words increases by maximum number of words generated.
- The maximum number of words a human can perceive per year is a constant.
- It follows from the above that humans perceive a decreasing percentage of the world's total words per year.
- Knowledge is words that make accurate predictions of many more words.
- Noise is words that don't predict many more words.
- Patterns in words are sometimes recognized and formed into knowledge words.
- The fundamental generators of the patterns in the 4D world seem to be static, but may not be.
- The absolute number of knowledge words increases over time.
- Knowledge seems to grow logarithmically.
- If one ruthlessly focuses on knowledge over noise, one may predict more of the 4D world than their ancestors.
Americans are guinea pigs in a huge experiment: we are exposed to more ads than any group in history.
It's not going well.
I say it's time for a new experiment: let's get rid of ads.
Here's how.
Information as apples
Imagine information as apples.
Ads are like those little round stickers stuck on the side.
Imagine it is illegal to remove these stickers.
Finally, imagine some stickers are poisoned.
This is information in America today.
Copyright makes it illegal for Americans to remove the stickers; to remove ads from information.
Get rid of copyright, get rid of ads.
(Or we can make content creators liable for any and all harm arising from their "content", including any harm coming from bundled ads.).
I was born in 1984. My daughters in 2019 and 2021. I would love their world to be better than the one I grew up in.
Information can nourish, or it can poison.
I would love my girls to live in a world with more sustenance, less poison.
Let's get rid of copyright and get rid of ads.
With Scroll I am trying to make a product I love and a product other people love so much it spreads via word-of-mouth.
Word-of-mouth spread! The holy grail of startups.
It has been harder than I expected.
I think a cognitive mistake I've been making is comparing new versions of Scroll to older versions and not comparing new versions of Scroll to the best available alternatives in the market.
In other words, I keep thinking this new version is so mucher better (or has so much more potential) than the old version, so of course the old version wasn't good enough to have a viral coefficient greater than 1 (but this one will!).
I'll call this the Internal Comparison Trap. You feel like you're making significant progress because the new version of your product is significantly better. But the market doesn't care about internal comparisons. The market only cares about your best versus the market's best. And that gap might be as wide as ever, and widening the resource gap.
In most things in life it's healthy not to be comparing yourself to the market's best. Instead, be the best you can be-compete against your prior self! But when making investment decisions you have to compare your bet to the market's best. The market is very much winner take most. It's better to have a small slice of #1 than a big slice of #10.
Externally I see this playing out a lot with the various AI companies. If you look at each in isolation, they all seem to be making incredible progress. But if you compare each new release to the market's best, the improvements are often marginal or even non-existent.
It gets especially hard in a competitive market. At first you are on the low part of the S-Curve so it's relatively easy to make major jumps in product improvement. But then the improvements naturally get harder (technical debt builds up, for instance), and meanwhile you enter the ranks of the top competitors, who are innovating as hard as ever.
There are other ways to get word-of-mouth spread, other than having a breakthrough product. I think if you are financially disciplined with great customer service you can build a word-of-mouth flywheel machine.
But if your strategy is get ahead of the market with a better product, you have to really have a strong differentiator that the alternatives just can't provide.
I am really proud of Scroll and how much it has improved over the years. I think it's helped me become a stronger thinker.
But the alternative tools in the market have also improved a tremendous amount.
If Scroll is going to take the lead, it can't just keep improving significantly relative to itself, it needs to make a leap where it becomes significantly better than the market's best.
This post is written in Scroll, a 2D language.
I have a new language, a 4D one, I've been working on for over a year now. I call it Ford (get it?).
I don't have much to share yet but I wanted to write about it anyway. Maybe someone is working on a similar thing and would like to collaborate.
The brain is a 4D prediction engine.
All that is selected for is our ability to predict 4D.
4D patterns in nature can be folded into lower dimensions, like reverse-origami. Folding makes ideas easier to transport.
Writing is folding 4D into 2D.
Reading is unfolding 2D back into 4D.
A single word is a point representation of a 4D concept. Fire, for example. It unfolds to 2D then to 3D and 4D.
To fold concepts from 4D to 2D and back, there is an overall causal order, though parts can be parallelized.
All sensible symbols can be unfolded to accurate predictions of the 4D world.
Symbols that don't unfold accurately are non-sense.
(Symbols that purposefully perplex are not necessarily non-sense, if intended as art)
Our modeling engines are not infinite. Our brains have limits.
At each instant we expose ~200 million cells in our eyes to light.
Perhaps a number based on physical limits like that is the ceiling for the number of voxels we can model at once.
Perhaps the true number is far smaller.
I believe thinking about the 4D nature of concepts and the folds that best get them to and from 2D may lead to more useful 2D languages.
- Juggling Ideas (2025)
- The Spherical Object Model (2025)
- Dreaming of a 4D Wikipedia (2025)
- Does 3D exist? (2025)
Symbols can live more than fifty times longer than humans. They require almost no energy to persist, just the occasional refresh every fifty years or so to not fade. How do we talk about this space where symbols are popping up, fading or being replicated, on surfaces and screens? I suggest a new word: Infosphere.
The Infosphere refers to the collection of all man-made, public, persisting symbols.
The Infosphere is not the natural part of nature. The Infosphere is not present in the woods, or on the beach, or in the mountains.
Books, newspapers, magazines, televisions, phone screens, radios - these are the realm of the Infosphere.
Your eyes and ears breathe the Infosphere as your lungs breathe the atmosphere.
We depend on the atmosphere to live and we depend on the infosphere to thrive.
A century ago in the western world new industrial technologies polluted our atmosphere.
We largely fixed this, but now our infosphere is heavily polluted.
Information pollution is very real.
Earlier generations spent far more time in nature. It simply wasn't possible to be exposed to the infosphere so much.
Now the infosphere is increasingly omnipresent, and, as it is filled with toxins, the latest generations, including mine, are the most lied to people in history.
You wouldn't want your children to breathe toxic air, why would you want them to breathe toxic information?
What is the source of these toxins?
The infosphere can nourish or poison, instruct or distract.
You would think our laws would be designed to encourage the former and discourage the latter.
But it is the opposite.
The primary source of infosphere pollution are those unarchived symbols that we are not permitted to adjust.
We have made widespread a thing called "copyright" law. What does this do?
It orders that new symbols be frozen for over 100 years.
It pretends that this would lead to a healthier infosphere, but any thinking man can see how clearly false this is.
Ideas work best continually refined. Freezing ideas is nonsensical.
No honest scientist or engineer would ever say their symbols are perfect. Instead they constantly strive to correct them, iterating upon them until they die, and hoping that future generations will continue to iterate upon them after that. The scientist also publishes their work for all to see and learn from. Meanwhile, the copyrighter demands payment before one can see their work, then puts out dribble after dribble, and claims their symbols are immune from defects, and must not be altered without permission for over a century.
Which symbols do you think are healthier for the infosphere?
Nature provides incentives for improving the infosphere. Copyright provides incentives for polluting the infosphere.
Believing one can centrally set the optimal "term limits" on information is as naive as believing one can centrally set prices.
Free markets would far more intelligently organize the infosphere.
The information filter strips toxic information, such as orthogonal advertising, from the infosphere.
But information filtering is made illegal by copyright law.
As a result, toxins are incentivized and linger.
Advertising, the mixing of undesired symbols with desired ones, is like an industrial age smoke stack spewing soot into the air.
Advertising pollutes our infosphere.
Honest advertising needs no captive audience or copyright protection. Thus, most in the advertising business are liars.
Liars pay top dollar for ads. Often the purveyor of copyrighted materials tries to pretend they are in an honest business but their material is bundled with advertisements for dishonest products.
When you see "Our business model is advertising" you should interpret as "Our business model is lying."
What kinds of information are we most exposed to?
Are we exposed to high value, instructive information, or are we exposed to information trying to distract and mislead?
I often find high quality information buried under mountains of junk. We are exposed to the information on top, while the truth seeker has to go digging.
Sadly people are not allowed to filter the junk for others and so each one must waste their time doing so (or more commonly, give up and just accept what they are told).
What is the harm of a polluted infosphere?
Significant time wasted, for one. When one man's time is wasted, everyone is worse off.
But it does not stop there.
We saw in 2020 people worldwide held prisoner in their homes, ordered to cover their faces, getting forced injections, all uninformed orders made possible by a toxic infosphere.
There are countless Salem witch trials going on right now for conditions that don't exist; immunizations that doesn't immunize; medicines that don't heal.
An unhealthy infosphere is as deadly as an unhealthy atmosphere.
We have recognized that we need to take care of our atmosphere.
Similarly, we need to take care of our infosphere.
I believe learning through motion-through conducting physical experiments in the real world-is vastly superior to learning through reading.
But the number of experiments one can do is vast, with some being far more informative than others, and time and resources are limited. Reading can point one to the motions-the experiments-that are most informative.
Thus, the most valuable symbols are the ones that guide one to conduct the most useful experiments.
Lately I've been figuring out how to put all of science into one file. I think the file would largely be experiment after experiment after experiment. Each one, the near minimum number of symbols to communicate the easiest experiment that can be done to cause learning the next most useful set of patterns about the world.
Pretext is all the words, all the definitions, all the patterns not in the text but that the text depends on. The texts that the author possesses and the reader requires.
Texts are far smaller than their pretexts.
The text E=mc² is short; the pretext long.
Texts are like the tip of the iceberg. But that's overselling texts, for the tip of the iceberg is 10% of the thing, whereas texts are far less a percentage of the text+pretext combination.
Perhaps the better metaphor is that texts are like the tip of a new Hawai'ian island poking above the surface, built on an Everest-sized mountain underneath.
The Pretext Button
We can build a machine, a function, that generates the pretext for a text.
Generated pretext would help find logical mistakes and/or experimental holes.
Pretexts would also give us measurable quantities. We could compare the true size of text A and text B by measuring both with their pretexts.
What should be in the pretext?
- Every word should be declared
- Every word should be grounded
- Every word should be defined
- And the same for multiword constructs
- The text should be fully parseable by the above
I'm excited to work more on pretext. Should have some demos soon.
The doer alone learneth.Attributed to Nietzsche
I wish I spent more time moving atoms and less time moving symbols.
I enjoy reading and writing, but I do more of it than I'd like.
I overinvest in symbols out of duty. A small group of us stumbled upon the truth that our society has gotten the law wrong on symbols, and as a result the infosphere has become heavily polluted.
In an ideal world, IP law is deleted, the toxins are filtered from our infosphere, symbols become far more signal than noise, and I can put more time into doing things that require more motion than the pressing of keys on the keyboard or dancing a pen across a page.
Symbols, done right, are an extremely useful tool.
But only so far as they can improve the models embedded in one's brain.
The latter is the ends, the essential. The former is just a means.
The mental model is the meal, the symbols are the kitchen. Humans don't need kitchens, but do need meals. One is absolutely essential, the other is just a means to the essential thing. Kitchens are awesome, symbols are awesome, but there is a huge difference between something essential and a tool for making the essential thing.
The Best Symbols
The best symbols are those that transmit reproducible experiments that someone can do to learn highly predictive models of the world.
It is not enough to just read the symbols, you have to do the movements to learn them. The symbols are merely a guide.
When some symbols can lead you through some motions that then unlock in you vast new predictive powers, that is symbols at their finest.
I wish I could snap my fingers and get people to see what I could see. A world with a very different infosphere. New mediums beyond books and papers and shows. Where symbolic products are published in a way to be easily accessed and shared and combined and refined and digested. An infosphere not overwhelmed with noise, not constantly trying to steal your attention. An infosphere that serves you, not tricks you.
It is far more rewarding to make things with atoms than symbols. Atomic creations are the things to be most proud of. The symbols on the screens should help us move and produce more, rather than sit and consume more symbols.
Years ago my smart phone broke and I did not replace it. It was a life improvement.
My laptop is nearing 5 years old. It too may soon break. I would prefer not to replace it.
I hope the truth will be spreading by then.
We need far fewer symbols. We need signal, not noise.
When the facts change, I change my mind. What do you do?Attributed to John Maynard Keynes (1932)
A strong thinker can explain their position and imagine new facts that would flip it.
Facts don't always change. Nature grants us some stability in her laws.
But they can always change. Our models are always downstream of measurements.
Imagining new facts that could cause you to change your positions makes you stronger.
Not only does it make you less likely to invest in wrong positions, but it will teach you how to better understand (and potentially alter) the positions of others.
Positions are built on models built of blocks
On topic T, my position is P.
My model of T is M.
M is built of blocks B[].
What changed blocks CB[], would cause me to flip my position P?
Sales
What I'm talking about here is also very similar to the problem of sales.
In sales you are listening to the potential customer to understand their model of the world, and then giving them truthful block changes that will update their model so that their position P becomes "buy".
Listening
To identify mind changers one needs to be know what the current model of the world in the mind is.
If you're trying to identify your own mind changers, writing helps.
If you're trying to identify the mind changers in someone else, listening.
Subconcious
What might cause someone to change their mind on a position P might have little to do with the symbolic model you're able to dig out.
It might mostly be due to subconscious blocks.
Perhaps a person says "Y" would change their position to P', but then what actually changes their position to P' is something totally different (like a pretty person pitching P').
Selling Out
The surprising thing is not that every man has his price, but how low it is.Attributed to Napoleon
In writing this one unexpected thing I realized is how easily and near universally even my positions are vulnerable to incentives.
I don't think you could pay me a price to promote a position I believed to be false, but you could probably pay me a (high) price to not promote a position I believed to be true.
In other words, my voice is not for sale, but my silence might be.
Why is this?
Simply because I have multiple things I care a lot about, I know my time is limited, and so working on certain things always comes at the expense of working on others. So if someone pays me $X to not promote opinion Y, but that allows me to promote 3 opinions that I care about when I otherwise might only be able to promote 1, I can see that is a deal I would be willing to consider.
So the block "suddenly I'm being paid not to promote P" would not get me to 180° flip my position P, but to at least rotate it 90° and go passive on P.
No one is currently paying me not to promote ideas (unfortunately?), but I think this is pretty widespread.
Some claim a lot of advertising in our world today isn't selling products, but buying silence.
Appendix: Practicing what I preach
Below I practice looking for mind changers on three of my most contrarian ideas.
What are some block changes that might cause me to reverse my contrarian position that IP laws should be abolished?
I don't think any of these would ever happen, but I guess my mind would change if reproducible data showed conclusively:
- Concentrating power into a tiny sliver of humanity, the "innovator class", creates vastly better innovation than diffusive innovation
- Without IP then the class of people adept with symbols are inevitably and hopelessly enslaved by the property controlling class
- IP allows better information control and without it there is inevitable weapons proliferation and civilization-ending violence
- Without IP information sharing plummets and information sabotage reigns
- Without IP for whatever 2nd order reasons we are no longer able to build such collabortive wonders as microprocessors
- If AGI arrives and can create so much great stuff on demand that IP laws become completely irrelevant
Again, I would be extremely surprised by data showing these things, but these are the types of things that might cause me to change my mind.
What are some block changes that might cause me to reverse my contrarian position that Scroll is a language worth strong investment?
- Putting time into improving Scroll often leads me to feel like I'm becoming a stronger thinker, so if that stopped being the case, I could see that.
- I definitely believe "thinking in 3D/4D", is 100x better than 2D thinking, so I could see if some type of 4D or 3D symbolic language were invented, that Scroll would become a much less important investment.
- Although I think Scroll is the language currently most alligned with LLMs, something new might arise significantly more aligned with them, which would make Scroll irrelevant.
- If the potential applications of Scroll to government and commerce were shown to be irrelevant, then it might show that the Metcalfe's law effect I predict will eventually come to Scroll might never happen.
What are some block changes that might cause me to reverse my contrarian position that mitochondrial populations are the root cause of human energy disorders?
- If it's shown that there is no difference in mitochondrial populations in the same human in different energy states
- If a wholly different biological model arises, perhaps with a different organelle, or that looks at things very differently (perhaps with some type of field theory), that explains things better.
In 1976, Bill Gates wrote an angry letter to computer users saying "most of you steal your software".
BASIC is a language created at Dartmouth in 1964 by John Kemeny and Thomas Kurtz.
To celebrate its 50th, Microsoft released the source code to their first product, Altair BASIC, written in 1975.
The 157 pages of source code contain zero mentions of Kemeny, Kurtz or Dartmouth.
What Science May Be
by Breck Yunits
We can embody all of science into a single fully connected text file.
Scientists would contribute blocks to this file like they now contribute papers to journals and datasets to databases.
I estimate all of science would fit in 1 billion pages. If printed this would extend from here to the Moon.
This file would allow everyone to get state-of-the-art, logical answers to any question by querying every scientist, living and dead, all at once, on their own machines.
How do we connect every word? A new language consisting of a simple universal syntax that denotes words and recursive blocks, along with type definitions called parsers, creates an invisible wired grid. A Reader moves down the blocks of the file, encountering new parsers or pattern matching words and blocks to existing parsers, and then loads blocks into memory for later computations.
All words are typed and the file is mostly structured data, with exceptions for sections of visual and free-text data, called groundings.
This file would be topologically ordered, meaning concepts are defined only out of already defined concepts. For example, addition and uncertainty would be defined before quantum mechanics.
Experimental procedures and actual scaled measurements would be found early and often, as reproducible experiments are the bedrock of science.
To attract the huge energy required to build this file it must deliver value far before it is near complete. Domain specific sections of the file can be built separately in parallel and deliver immediate value even before integration. The tools needed to build this system are also useful for more down-to-earth tasks and these use cases could attract the energy necessary for the moonshot. For example, the same software needed for this file could also power simpler and more trustworthy blockchains.
Decentralization and forks would be encouraged and often merged back, and may on occasion lead to fracturing and different schools of science.
Believers in this system would want Freedom of Science laws that would protect the rights of individuals to create, improve, and share these files.
This system might be built by ten million scientists contributing an average of 100 pages each, or perhaps a far smaller team utilizing AIs.
Think of these files as a new medium beyond articles, books, databases, encyclopedias, wikis, and LLMs.
The three major alternatives to this system, in order of connectedness, are libgen, which metaphorically glues all liberated books and scientific papers together at the edges with no integration; Wikipedia, which contains a shallow but broad collection of concepts with weak integration; and deep neural networks, which turn libgen, Wikipedia, and the web into an inscrutable matrix with incredible generation capabilities that strongly suggest embedded logical understanding (but also high energy requirements and hallucination tendencies).
This system differs from previous expert symbolic AI systems in the design of its language that allows it to scale to all of science.
This file would instantly reveal what science knows and does not know; what concepts are needed to fully understand other concepts; what experiments one can do to verify key concepts; and what the actual contributions of new research are, measured in line changes.
In its transparency, simplicity and minimalism, this file would make science a physical thing that people could hold and trust.
A number of developments have made it more feasible than ever to build this system now, but the value this system would provide to humans is timeless.
The smallest improvements, compounded, have the biggest impact.
In biology, if it wasn't for a tiny dividing nucleic-cell pairing with a tiny dividing proto-mitochondria bacterium 2 billion years ago, we would not be here.
In computing, it's been the nanoscopic improvements to the transistor which have caused the biggest changes to the world in the past 50 years.
Let's call these things nanoideas.
It follows from this that if you believe a big impact is needed you need to look not for big ideas but nanoideas-the smallest ideas that compound.
To find better nanoideas as yourself questions like:
- Is there a version of this idea that's even smaller?
- Does this idea compound? How?
- How fast will this idea compound?
List all of your ideas and go into detail on their size and how they compound.
Biological viruses are nanoideas.
Physics is full of nanoideas.
Moral values are nanoideas.
There is nothing wrong with having big ideas. But sometimes the best way to materialize them is by way of nanoideas.
Related
Symbols are useless unless consulted.
Consulting consumes energy.
Everyone has finite energy.
Consulting can be sequential or—via computation—simultaneous.
I call symbols with no legal restrictions the Unchained.
The Unchained is too large to be consulted sequentially.
The Unchained can be consulted computationally and so simultaneously.
I call symbols with legal restrictions the ©hained.
The ©hained is too large to be consulted sequentially.
The ©hained may not be consulted computationally and thus cannot be consulted simultaneously.
Because the ©hained may not be consulted computationally, consulting from the ©hained and consulting from the Unchained are exclusive operations.
Sequentially consulting the ©hained reduces energy available for simultaneously consulting the Unchained.
Thus, the ©hainer's implicit argument is that sequentially consulting their ©hained symbols is worth more than simultaneously consulting the Unchained.
A ©hainer mathematician claims sequentially consulting their symbols is worth more than simultaneously consulting Euclid, Gauss, and Euler.
A ©hainer physicist claims sequentially consulting their symbols is worth more than simultaneously consulting Newton, Maxwell, and Einstein.
A ©hainer musician claims sequentially consulting their symbols is worth more than simultaneously consulting Bach, Beethoven, and Mozart.
A ©hainer biologist claims sequentially consulting their symbols is worth more than simultaneously consulting Leeuwenhoek, Pasteur, and Darwin.
A ©hainer artist claims sequentially consulting their symbols is worth more than simultaneously consulting da Vinci, Rembrandt, and van Gogh.
A ©hainer author claims sequentially consulting their symbols is worth more than simultaneously consulting Homer, Shakespeare, and Dostoevsky.
©hainers claim their symbols ought be treated with more consideration than the symbols of these greats.
I hope you see why this is such a ridiculously dishonest position, and understand my visceral disgust for this behavior.
© is the mark of the ©hainer. It is the mark of the dishonest man.
I salute and lend my hands to the honest men who contribute symbols to the great Unchained. They have an honest estimation of their humble contributions in relation to the whole. It is on their shoulders that the future is built.
Nobody talks about how Bill Gates actually made his billions.
Nobody talks about how Larry Ellison actually made his billions.
Nobody talks about how Larry and Sergey actually made their billions.
Nobody talks about how Jeff Bezos actually made his billions.
There's a Secret.
A Secret connecting the majority of the richest people in the world (and it's not value creation).
The reason nobody talks about the Secret is because the people who effectively control what we talk about make their millions in the same way. Talking about the Secret is a surefire way to get kicked out of the club.
Technology is abolutely incredible. Not just because of what it can do, but because of how hard it was to create. How much blood, sweat, and tears from tens of millions of people over thousands of years went into learning the patterns of our universe and helping evolve technologies to manipulate it.
It is such a shame that this industry is controlled by people who use the Secret to extract rent and control the population. Who try and pretend their extraordinary wealth comes from value creation, and not the legal chains of the Secret. Who disrespect the great work of the countless brave and selfless souls who gave their time to build a better world for their descendants, only to see things locked up by these "tech titans" and their cronies in Congress and the media. Who will lead our country to ruin to protect their Secret and their wealth.
I respect the work ethic and intelligence and leadership skills of the people above. But I don't respect their integrity.
It makes me sad that so many young people get caught up chasing the same scale of fortunes as the people above, not realizing that "dishonesty" and the Secret is the crucial ingredient to their extraordinary "success".
It makes me sad that so few can see the Secret.
It's hidden by its ubiquity.
We live above 7 microverses that we cannot see no matter how hard we squint.
Each microverse is ten times larger than the one above.
Each is its own land with unique creatures, phenomena and rules.
We rely on scopes, and experiments, and symbols to map the territory.
How many concepts to describe each world? 1,000? 10,000? More?
I gave these microverses names: Hairfield, Bloodland, Mitotown, Viralworld, Proteinplace, Moleculeville, Atomboro.
And that just gets us to the atomic level. But there are many more lands beyond that we cannot see. It may be closer to the beginning than the end.
| name | microverse | diameter | source | visibleSince |
|---|---|---|---|---|
| Hydrogen Atom | Atomboro | 1 | https://en.wikipedia.org/wiki/Bohr_radius | 1970 |
| Glucose | Moleculeville | 15 | https://bionumbers.hms.harvard.edu/bionumber.aspx?&id=106979 | 1961 |
| Hemoglobin | Proteinplace | 85 | https://bionumbers.hms.harvard.edu/bionumber.aspx?id=105116&ver=4&trm=hemoglobin&org= | 1840 |
| SARS-CoV-2 | Viralworld | 1000 | https://pmc.ncbi.nlm.nih.gov/articles/PMC7224694/ | 1931 |
| Mitochondria | Mitotown | 10000 | https://www.ncbi.nlm.nih.gov/books/NBK26894/ | 1857 |
| Red Blood Cell | Bloodland | 80000 | https://pmc.ncbi.nlm.nih.gov/articles/PMC2998922/ | 1678 |
| Human ovum | Hairfield | 1200000 | https://en.wikipedia.org/wiki/Egg_cell | 1677 |

Lately I've been thinking about topological sorting.
Topological sorting is sorting concepts in dependency order.
For example, if you wanted to sort "fire" and "internal combustion engine", fire would come first. To explain ICEs, you need fire, but to explain fire you don't need ICEs.
Sorting concepts topologically versus chronologically can create different rankings.
Sorting numbers topologically puts binary (0 and 1) before the Hindu-Arabic numerals (0 - 9), even though humans used 0-9 way before using 0 and 1.
Our topological knowledge base often has missing or incorrect concepts that may not be fixed for centuries.
Encyclopedias are sorted alphabetically.
I am unaware of an encyclopedia sorted topologically.
Why would you want an encyclopedia sorted topologically?
Well, topological sorting tells you the logical importance of things. Things further down are built on things at the top (or vice versa, if you prepend new things to your files rather than append).
A topologically sorted encyclopedia would also be hard to vary. Computational logic tests would trigger if someone tried to add non-sense to a low level piece. You could tell how important something is by how hard it would be to vary-how much load do these symbols support?
When revolutionary new low-level scientific insights are discovered that refine our models, you could actually numerically see and measure the downstream impact of those breakthroughs.
If you want to get the most bang for your bits, sort your ideas topologically.
What parts of the encyclopedia should you learn first?
It makes more sense to learn the things with a high topological ranking, rather than a high alphabetical ranking. A lot of things turn out to be fads.
Popularity sorting such as by number of inbound links is an improvement over alphabetical sorting, but seems very susceptible to bias and fads.
How would you create a topologically sorted encyclopedia?
I have been attempting to build a topologically sorted encyclopedia for a long time, though I had never described it like that. It's only recently when I realized I wanted to change Scroll to be topologically-sorted by default that I went looking for the definitive term to describe the concept.
I think using parsers all the way down might work, though I could be wrong. The nice thing about this strategy is that you can build stuff that is useful along the way even if the vision of the topological encyclopedia doesn't materialize.
Today I started looking at older programming languages that have lasted like C, Fortran, Ada, et cetera, and realized that topological sorting used to be the default. Newer languages aren't as strict, and that's the pattern I copied. But I wonder whether it's a better design to make the rule topologically sorted, and the looser version the exception.
When dealing with larger programs it seems you can do things a lot faster if you know things are sorted topologically.
Is the universe topologically sorted?
It seems to be. The present depends upon the past, and so comes after the past.
Which came first, the chicken or the egg?
If we are talking about the words, that might be easy to determine with a good etymology reference.
If we are talking about the patterns represented by the words, then it's a bit more interesting. We know the bacteria came before either. But my guess is we had objects closer in appearance to chicken eggs before we had objects resembling chickens. So I would say the egg came first, topologically.
A scale is an ordering of numbers. Objects map to a scale to allow comparibility in that dimension.
The word scale is an overloaded term. Usually when I use the word "scale" I am using a different version of it, such as "scale it up" or "economies of scale". In this post I'm using it in the sense of a measurement or yardstick or number-line or type.
English is generally unscaled. A small subset of it is scaled.
So blog posts are mostly "unscaled". It is hard to compare this line with the line below it.
But this post does contain some lines that are scaled. For example, it has a date line, which maps this post to a date scale. So you can compare this post to others, and say which came before, and how much they came before.
Scroll, the language and software that powers this blog, does compute some scaled metrics on each post. The number of words, for example. You can see the number of words for this post and all others on the search page.
I like the definition of scales in the d3 data visualization library:
Scales are a convenient abstraction for a fundamental task in visualization: mapping a dimension of abstract data to a visual representation. Although most often used for position-encoding quantitative data, such as mapping a measurement in meters to a position in pixels for dots in a scatterplot, scales can represent virtually any visual encoding, such as diverging colors, stroke widths, or symbol size. Scales can also be used with virtually any type of data, such as named categorical data or discrete data that requires sensible breaks.
I remember when I was struggling to use d3 and then finally their definition of scales clicked in my head and I realized what a simple, beautiful and widely applicable concept it was.
Scales make things comparable. Measure different concepts using the same scale and now you can compare those things symbolically.
The more scales you use, the more sophisticated your symbolic models become. You can measure two buildings with a height scale to create some comparisons, but you can greatly increase those comparisons if you also measure them with a "year built" scale.
One of the most important scales is the computational complexity scale.
Nature loves inequality, the size scale of our universe is vast with ~65 orders of magnitude buckets, and so rarely do 2 random things fall in the same bucket.
A dimension is just a set of different measurements with the same scale.
You can think of any scale as just a line.
Measure objects and draw a point on the line for where each measurement falls.
You can draw a high dimensional dataset as just a lot of independent lines. Not the most useful visualization, but can be helpful sometimes to break things down into really simply pieces.
Wikipedia does not make heavy use of scales. It relies more on unscaled narratives. I often wonder if the focus was more on adding scaled data-data in typed dimensions-if it would allow it to become a more truthful symbolic model of the world.
To be fair, the infoboxes on Wikipedia are scaled data. The syntax is nasty, but the scaled data is wonderfully useful.
The more scales you have, the more trustworthy a model is.
I often think about complexity scales. I proposed if you think in parsers you can measure the complexity of any idea. Perhaps the "parser" is a good unit for a complexity scale. If two models of the world are equally intelligent, pick the less complex one - the one with fewer parsers.
I don't have anything too profound to say about scales. (On the impact scale, this post ranks low.)
I just want to make sure I am deliberately thinking enough about them. If you measure concepts on an importance scale, they are high on the list.
Related Posts
- The Infosphere (2025)
- Experiments (2025)
- Pretext (2025)
- What Science May Be (2025)
- Topological Sorting (2025)
- Thinking in Parsers (2025)
- ICS: A Measure of Intelligence (2024)
- ScrollSets: A New Way to Store Knowledge (2024)
- Marks (2024)
- Hot Coffee (2024)
- The Box Method of Science (2024)
- I thought we could build AI experts by hand (2023)
- Type the World (2020)
- PC: Particle Complexity (2017)
Do you want to learn a new way to think? And a new way to write? Do you want to learn how to look at everything from a new perspective?
If so, read on.
I will try to explain to you how to "think in Parsers". I'll also then go into "writing with Parsers", a computer language we've made. It might not click immediately, but when it finally does I think you'll find it wonderfully useful.
No matter what topic you want to learn, from music to math, chemistry to carpentry, mechanics to quantum mechanics, thinking in parsers gives you another path to understanding any domain.
Parsers match patterns
Look for a tree. (If you're inside, you may need to go to a window)
Did you see one? Great! That means you have a "TreeParser" in your brain that is capable of recognizing trees.
Now, look for a rock. See one? Great! You brain also has a "RockParser".
Parsers are things that match certain patterns and are inert to others.
Your TreeParser fired when you saw a tree, but not when you saw a rock, and vice versa.
Parsers are composable
The tree you looked at may have also activated another Parser specific to that species. I am writing this in Massachusetts and so for me that was my PineTreeParser. Usually I am in Hawai'i and my PalmTreeParser activates. For you it might be another kind. The point is parsers can be derivatives of other Parsers.
But that's not the only way Parsers can compose.
For example, you can also have Parsers that parse parts of a pattern. Think of a BranchParser or a LeafParser.
Parsers can combine in many ways.
Parsers are contextual
Imagine taking a leaf from the tree and looking at it under a microscope. If you remember your biology class, your "CellParser" may activate. But if you were given a blurry image and not told its source, your "TurtleShellParser" may activate instead.
Because you have context you know which Parser is the one to use.
Parsers hold logic
Imagine pulling the tree you saw out of the ground and into the sky. Now imagine throwing the rock into the sky.
I bet when you imagined lifting the tree, you imagined pulling up roots, but you didn't imagine roots attached to the rock.
You can attach knowledge to parsers that can be used in combination with the pattern that activated the parser.
Patterns Exist Without Parsers
The patterns that trees or rocks or turtles emit exist whether or not we have a parser that recognizes them. Patterns exist without parsers.
A baby starts with very few parsers and things for them are largely a blur until they have developed the parsers to make sense of their sensory data.
Often, especially when growing up, we see and record raw patterns that we don't fully understand. Eventually we stumble upon parsers that match those patterns and give us deeper understanding of what we witnessed earlier.
Sometimes we only notice a pattern after we've learned a parser for it. For example, if you've ever gotten a new car, you've probably experienced the phenomena of suddenly noticing that model of car all around you. This is because you have acquired more parsers for that pattern that are now getting activated when you encounter it.
And often the parsers we have don't actually best fit the universe's patterns and we update them later. The pattern of the earth revolving around the sun has existed always, for example, even though humans previously had parsers that parsed it in a different way.
Recap
Let's recap so far. Parsers:
- Match patterns
- Are composable
- Are context-sensitive
- Hold logic
Parsers in the symbolic world
So far we've been talking about Parsers for objects in the real world that are stored in the neural networks of your brain. These Parsers are neat, and you don't even have to be human to have them (dogs, for example have parsers to recognize their master) but Parsers work the same way in the symbolic world.
For example, you have an oParser that:
- recognizes the letter "o"
- also activates your LetterParser
- is context sensitive (so you can recognize the letter "o" versus the number "0")
- and holds logic related to "o", such as it's sound.
And then you can have a WordParser that recognizes words, such as "color".
You can then have a PropertyParser that recognizes a pair of words like "color blue".
Parsers never stop composing like this. If you were to look at the source code of this post you would even see that this sentence is parsed by a ParagraphParser.
It's Parsers all the way down! And all the way up!
Membranes
One thing you'll notice about parsing objects is that all Parsers assume membranes. Whether it's the edges of the tree or the space around words, there are lines, either visible or invisible, that separate what is being parsed versus not parsed.
The Parsers Programming Language
Now let's combine the sections above by making a language of symbolic parsers about things we encounter in the physical world.
First, we need to set some rules as to the membranes of our language - where do we draw the lines around the atomic units that we will parse? For this, we'll use Particle Syntax (aka Particles). Particles splits our writings into atoms (words), particles (lines), and subparticles (indented lines that belong to the "scope" of the parent line). The nice thing about Particles is that there is no visible syntax at all, and yet it gives us the building blocks to represent any kind of structure.
Now, imagine we wrote the lines below on a walk in the woods.
pineTree
height 20ft
circumference .5ft
pineTree
height 10ft
circumference .3ft
oakTree
height 30ft
circumference .8ft
Right now all we have is some patterns, but no parsers.
Let's write some parsers to parse the lines above:
abstractTreeParser
pattern *Tree
heightParser
atoms lengthAtom
circumferenceParser
atoms lengthAtom
calculateVolume
return height * surfaceArea
pineTree extends abstractTreeParser
oakTree extends abstractTreeParser
Now we have five parsers with which to understand our original program.
Of course, the parsers themselves also make use of various parsers (such as "pattern" and "atoms"), which I've left out, so in reality there would be quite a bit more.
I've left out some details to focus on the core ideas of how you can define Parsers symbolically that match patterns, are composable, context-sensitive, and hold logic.
You may notice that the Parsers language is not very much concerned with computers and fitting the world to match the structures in a computer. Although the parsers can carry logic to execute on computers, Parsers is really focused more on organizing knowledge into parsers. Parsers is a knowledge storage language first--a way to think first--and a computational language second. Parsers does not say "here is a set of structures that work well on the computer, fit your knowledge of the world into them." Instead the approach of Parsers is to "mine the minimal, ideal set of symbols to represent the patterns you see, and then we'll have the computer adjust to those".
Now, if you want to dive deeper into Parsers, an ever evolving language, the Scroll website is a good place to visit next.
But now let's keep going and connect the dots.
How to Understand Anything
Now I'm going to get to the fun claim of this essay: every subject can be represented as a list of simple parsers in the Parsers language.
Parsers are the building blocks of knowledge, much like atoms are the building blocks of molecules.
It doesn't matter how "complex" the subject is, everything can be broken down (and built up) by simple parsers.
Now, don't get me wrong, I'm not saying quantum mechanics is the same thing as arithmetic. What I'm saying is that quantum mechanics is merely a larger list of parsers. Each parser in quantum mechanics is not more complex than the parsers in arithmetic, it's just that there are more of them.
If you are struggling to master a new subject, you can just start writing out all the parsers in the subject in a flat list. You can then work on your understanding of each one, refining your parser definition as you go. You'll find that before you can understand some parsers, you'll have to understand some other parsers it uses.
You can also organize parsers by which ones are used the most. (Often you'll find many parsers that are taught in books are not very important, and you'll start to pick up on the core set that are heavily used and should be mastered).
Eventually you'll have a long list of parsers that together describe a subject in a very accurate, precise, and computable way. It's like an encyclopedia but better, because the parsers are linked in ways that can be logically computed over.
Wrapping Up
This was a brief introduction to my primary mode of thinking: "thinking in parsers". I've personally found this a universally useful way to think about the world. The great thing about it is it works for both understanding objects in the 4D world and also for objects in the symbolic world (including 2D math).
When I was younger I was overwhelmed by the amount of symbolic knowledge we have in our world. Now that I'm able to think in parsers, I find it all far less intimidating, because I know it's just a big list of parsers, and I can take it one parser at a time.
I hope you find thinking in parsers as useful as I do.
FAQ
Are Parsers just Object Oriented Programming?
From an OO perspective, think of Parsers as ClassDefinitions initialized with particles that always have methods for parsing subparticles. Like OO, parsed particles can have methods and state and communicate via message passing. But with Parsers the focus is on parsing and patterns.
Are Parsers just functions?
From a functional programming perspective, you can think of Parsers as a function that takes pattern matching and other logic and returns functions that can parse patterns.
Are Parsers just Lisp?
From a Lisp perspective, you can think of Parsers as like Racket with its "Language Oriented Programming", but with Particle syntax which compose better than S-Expressions.
Are Parsers just XML?
From an XML perspective, think of Parsers as XML with a much slimmer syntax and a built-in language for defining schemas.
Does the rigidness of Parsers and the whitespace syntax in Particles dampen creativity?
No. First, you can have Parsers like a PoemParser that are very loose in what they accept. Second, no matter what, symbols are a poor approximation to patterns in the physical world, and so it's better to optimize for efficiency in symbolic patterns over looseness.
The below is a chapter from a short book I am working on. Feedback appreciated
Particle Syntax (Particles) is a minimal syntax for parsing documents.
What is a syntax? Think of it like a set of rules that tell you how to split a document into components and what to label those components. Particles fits in the category of syntaxes that includes XML, S-Expressions, JSON, TOML or YAML.
Particles is unique in that it is the most minimal of these.
How minimal is Particles? Very! The file below uses everything in the syntax:
post
title Particles
Particles divides a document into 3 kinds of things:
- Atoms
- Particles
- Subparticles
Atoms are just words. A word is just a sequence of visible characters (no spaces in words). The document above has 3 atoms: "post", "title", and "Particles". In Particles, atoms are separated by a single space. Particles has no understanding of what these words mean. Particles does not have the concept of number, for example. Every visible character in Particles is just part of an atom and that's it. If you have the line a b, that would be be split into 2 atoms, "a" and "b". If you were to add an extra space a b, that would now be 3 atoms, "a", "", and "b". So an atom can be of length 0.
The particles in Particles contain 2 things: a list of atoms, and optionally, a list of subparticles.
Subparticles are just particles that belong to a parent particle.
In the example above, the particle starting with "post" is actually a subparticle of the root particle, which is the document itself.
The particle starting with "title" is a subparticle of the particle starting with "post".
The particle starting with "title" has 2 atoms, "title" and "Particles", and zero subparticles.
The particle starting with "post" has 1 atom, "post", and 1 subparticle.
You make one particle a subparticle of another by indenting it one more space than it's parent particle. If we deleted the space before "title", then the line beginning with "title" would become the second subparticle of the root particle, and the line beginning with "post" would have zero subparticles. If we added another space before "title", that line would still be a subparticle of the "post" particle, and all that would change would be that we added a blank atom at the beginning of that particle's atoms list, and it would now have three atoms.
Exercises
Try to solve the exercises below. The answers are in the source code to this page.
if true
print Hello world
In the code above, how many atoms are there?
How many particles?
How many subparticles?
How many extra spaces does it take to make a particle a subparticle of the particle above it?
a
b
c
How many particles in the example above, excluding the root particle?
How many atoms does a blank line have?
Now you should understand the basics of what Particle Syntax is. In the next chapter we'll look at why Particles is so useful.
The market is a blob of decision making agents that speaks with money.
You speak to the market with an offer.
The market gives you money, which means "Yes".
Or does not give you money, which means "No".
The no may mean the market:
- does not understand your offering
- does not think you can deliver on your offering
- does not want your offering
- does not like the price of your offering
The relationship between a human and the market is like that between a dog and the farmer. The dog can roam a bit but ultimately the farmer holds the power.
Markets are an intelligence
Markets can be a bit scary sometimes, just as a hive of bees can be a bit scary. Markets vibrate with energy and it can take some getting used to to have that energy focused on you when you first put your offerings out there. You have to have thick skin - there are a number of market participants who will sting you, one way or the other (usually nothing personal, just people having a laugh or a bad day).
Markets are intelligent beings. They sniff out good deals. Direct energy to promising directions.
A good quote I saw recently, that was about investing in markets but I think applies to selling to markets as well: "1. Markets work. 2. Costs matter. 3. Diversification is your friend". In other words - markets will reward you if you make something of value, but it may take time (so keep costs low), and don't put all your eggs in one basket.
Muting the Market
As a builder, should you ever mute the market?
To mute the market is to ignore the "Nos" and continue to invest in your offering. Instead of pivoting to something the market will say "Yes" to today, you work on something that the market currently says "No" to, but you have the belief that at some point the market will change.
To mute the market is to understand something about the world the market currently doesn't get, and to have the conviction that it eventually will.
I think as much as you can, you don't want to mute the market. Instead, listen to the market and think "okay, what is the market telling me it wants, and how can I deliver that in a way that helps me gain the resources to build what I want." Continue to iterate with creative offerings that are both something you want to offer and something the market wants to say "Yes" to now.
The selection pressure the market provides can be very helpful. You are getting the wisdom of the crowds to rank your ideas. I can definitely imagine that sometimes the market is too short-term focused and muting it is potentially the right way, but when you do that you also mute a great source of free feedback.
How to Mute the Market
Despite my warnings, if you decide that a short term muting of the market is necessary, then you may have to go to extreme measures. Ideally, you've got a warchest. Perhaps savings, a good investment, investors who have bet on your vision, a grant, or something along those lines. With that capital you can mute the market for a period of time and try to invent a breakthrough new technological path. Without that capital the best advice comes from Hermann Hesse via his novel Siddhartha: "I can think. I can wait. I can fast." You will need to cut your expenses to the bone, and then use the bone for soup and cutlery. It can be done but you will have to push yourself to extreme measures you didn't know you were capable of. I'm not sure it's ever the right strategy. (But then sometimes I wonder whether it's the only strategy for true breakthroughs).
Enabling others to Mute the Market
Along these lines, as an angel investor one thing I've learned is that you may be hurting a startup by investing, as you are enabling them to mute the market for a prolonged period of time. The pressure of the market is uncomfortable but honest and necessary. It's more relaxing to mute the market but you'll never find out if your ship floats nor carry passengers across the sea.
Occasionally I mute the market more than I should. I am building something that I think most of the world may love in the future, even if the short term feedback from the market has been crickets.
The offering I'm working on is novel, so the market hasn't quite understood what I'm offering yet. It's a challenge because the path is so different than what's popular in the market that I have to see many branches ahead on my own and then communicate what I see and why it's a path worth traveling. I think I'm getting better at explaining it, and I think once the market understands it, the market will want it. I think soon many people will not be able to get enough of it.
But I'm also listening closely to the market, and trying to create offerings that use our technology that are more in tune with what the market wants.
The scary part about muting the market is the branch you are pioneering may be a dead end. It is a lot of work to see so many branches ahead to figure out if it's a path the market should go down. You don't want to blaze a trail to a dead-end, but even worse would be to mislead passengers down a dead-end trail.
The other scary part about muting the market is the old aphorism from finance: "markets can remain irrational longer than you can remain solvent".
But perhaps sometimes it must be done.
You learn to be deeply grateful and appreciative of the early adopters who break from the mainstream and come check out your fledgling path.
Whether it's the consumer market, the b2b market, the research market, or the investor market, communicating with the market is fun.
You get to create new offerings, put them out there in the marketplace, and listen to what the market says.
Stick to your convictions when you're confident in your model, but do your best to not mute the market.
Can you think about trust mathematically? Yes.
This makes it easier to design things to be more trustworthy.
You can think of anything and everything as an object that exists in 4D space.
The ideas below can be used to maximize trust of that object.
Inspection Vectors
The amount you can trust an object is equivalent to the number of inspection vectors that intersect with that object.
You want to minimize the number of planes that block inspection vectors.
You want to minimize the number of complexity prisms that bend inspection vectors.
You want to maximize the number of overlapping inspection vectors of different magnitudes (aka your zoom range).
You want to maximize the time dimension of observability (version history).
You want to maximize the number of simultaneous inspection vectors.
Experimentation
You want to maximize the number of copies of the object.
You want to maximize the choppability of the object.
This is my initial list of guidelines for increasing trust.
A nerveshaker is a trick performers can use to kickstart a performance. Once the generative networks in your brain are rolling they keep rolling but the inhibitory networks can keep them from starting. So if you have tricks that just divert energy away from the inhibitory networks and provide a jump to the generative networks, you can ensure your motor will start. For example, to kickstart an essay sometimes I will start by inventing a new term. Such as nerveshaker.
Now that we have the motor running, let's turn to the matter at hand: judging our 2024 research results.
First, a note on pronouns (no, not that kind of pronoun). In this report I use the terms "we" and "our", rather than I, because I had tremendous help from over a hundred people throughout the year. Although I was not an "employee" of any lab, nor did I have "employees", I received significant help in many forms, from code and data contributions, to code and paper reviews, to lots of in person meetings and presentation opportunities, to resources including office, lab, equipment and housing, to even direct cash contributions.
If the work done in 2024 grows into meaningful things, it is because of the help and spirit of these people throughout the world, who have believed in (or at least humored) what we are trying to do, and have helped advance things, despite my underwhelming leadership and engineering capabilities. So, that is why I mean it when I say this is a report of what we published.
Second, a word on why this report is on research performance and not business performance. This answer is simple: business performance was abysmal. I started the year with about $70,000 and ended with a bit less than $0. If I were just to report on business performance it would just write a single letter: F.
But, luckily (or delusionally), for me, there's another perspective to judge our 2024 results and that is the expected value of what these things might lead to.
And I think that the expected value of what we did in 2024 will be very, very high. Let's take a look.
Our top innovation, IMO, is ScrollSets. ScrollSets are a new simple alternative to knowledge bases that only require a simple plain text file. In 2024 we finally refined all the little pieces to make the whole thing just work. In 2025 we should be able to make them about 10-100x faster and then I think it will be off to the races.
I think ScrollSets may evolve into being one of the premier tools for truth. They allow you to take very small, simple steps, to build a very large matrix where all of the vectors intertwine so that as it grows it becomes very difficult to hide lies.
Money is a simple and available metric, even if suboptimal. If we look at the monetary impact this could have, well it's pretty big. On the order of $100 billion is spent on databases annually. So creating a potential game changer for <$70,000 I think is promising.
Building a ScrollSet about a topic is like building a compass that guides you to a true model of a topic. I used an early version of ScrollSets to build BrainDB, to solve a mysterious energy fluctuation I had experienced most of my life (erroneously called 'bipolar disorder'), that was said to be incurable. ScrollSets lead one to a thorough model, and eventually I stumbled upon a small group of researchers who were looking at this condition as a mitochondrial condition, caused in large part by a modern carb-heavy diet. After over a year of experimentation and a significant amount of research and microscopy I can now say with high confidence that this looks like exactly what it is, and we are now in the process of building a large image dataset of human mitochondria under the microscope to show this definitively. Again, money is a crude metric, but a simple one, and the estimated total annual global cost of "mood disorders" is on the order of $1 trillion. Making a significant contribution to a cure for $70,000 I think is a good ROI.
Other Things
Those are the two projects that I think will lead to the biggest long term impact on the world. And we're hard at work on taking them to the next level.
In addition, we put out a lot of other stuff that is also promising:
ScrollHub
A very powerful web server and editing environment being built especially to accelerate the building of ScrollSets.
Particles, Parsers, and Scroll
The Scroll language itself and the layers it is built on (Particles and Parsers) improved a great deal throughout the year. We started the year on version 72, and ended on version 162!
E=T/A! and The Permission Function
We made good headway on providing new perspectives to show theoretically why copyrights and patents are bad for progress. The extreme energy waste of the Permission Function shows why the ideal term for these monopolies must be 0, and the E=T/A! equation explains why they slow down the evolution of bad ideas into good ideas. I think these arguments should help contribute to bringing the abolishment of imaginary property laws into the Overton Window, which will have profoundly positive effects for human kind.
PLDB
In addition to now running on ScrollHub, we added a lot more data as well as a few new interesting interviews with some accomplished creators.
Particle Chains
I think Particle Chains may turn out to be extremely useful, and that will be something interesting to watch in 2025.
World Wide Scroll
An experiment in building a successor to the web that works offline, in a more intelligent language, and is public domain. This did not immediately catch on but not ready to rule it out yet.
Minor
In addition, some fun side projects including:
Wifinder
A side project to measure and share wifi speeds of public networks across the globe.
Togger
A side project to provide a faster UI for people to find and connect with live streamers.
Builder News
A side project to bring more positive energy than "Show HN", where web builders record and share user tests for other web builders.
This Blog
Over 70 posts in 2024, crushing my previous record of 37 in 2009. The Scroll language and ScrollHub were significant factors in increasing output.
Public Domain
As always, everything done was published to the public domain. I believe this is the way all research should be done.
Expenses
~80% of expenses went to lodging, food and transportation. I would like to cut those daily outlays in half. The reason it was so high is that my personal situation still has a conflict (I'm an open book and fine to share that my ex and her conspirers are still dishonestly persecuting me daily with secret motives. It is what it is. I don't try to focus on it but I don't want to hide anything). If I knew how long it was going to take to get things humming, I may have taken harder cost cutting measures earlier.
In 2025, I would like to put every penny of expense on a public ledger to provide more transparency and commitment to our backers that we are allocating resources wisely.
Conclusion
In 2024, as in prior years, I was rejected from pretty much every source of funding I applied to. At one point I did have a handshake deal for $1M which would have accelerated things, but that fell through for some reason (I never did get a reason), which led to a challenging (but educational!) last couple of months.
I hope some philanthropists and/or funders of research will take a look at what we did in 2024 and consider helping us do even better work in 2025.
Thanks for reading.
-Breck
Introduction
I sit with my coffee and wonder, can I explain the general pattern of Mathematics on a single page?
My gut says yes, my brain says maybe, and so I shall give it a go.
Mathematics, the written language
I aim to explain the essential concepts of the Mathematics humans write on rectangular surfaces. In other words, I'm limiting my scope to talk about 2D written mathematics only. Even math implented as computer programs (Mathematica, for example) is out of scope, as I've already examined thosein earlier work.
My claims are limited to that scope, though you may find these concepts useful beyond this.
Cheating, a bit
I need to admit that although this essay shall not exceed a page (including illustrations), I am undercounting the length of my explanation of Mathematics because I am ignoring the considerable requirements the reader must have developed to be able to parse English.
Ok. No more caveats. Time for the essential concepts in Mathematics.
Pixel Surface
Mathematics requires a 2D contiguous grid of Pixels whose color can be altered.
Cells
Mathematics requires the ability to draw or envision membranes around contiguous groups of pixels to form Cells.

Atoms
Mathematics requires Atoms, which are single indivisible cells with colored pixels.
Particles
Mathematics requires Particles, which are contiguous regions that can contain atoms and other particles recursively (called subparticles).
Holes
Holes are Particles that contain an identification atom and a list of atoms that fit that hole.

Parsers ★
Parsers are a type of particle who's atoms and subparticles define holes. Parsers are pressed against other particles and bind to particles who's subparticles and atoms fit a parser's holes. I put a ★ next to Parsers to indicate that these are the thing you should study to understand this system.
Transforms
Parsers can contain Transform definitions, which are Mathematics that transform one particle into another.
These meta concepts are enough to define all of Mathematics.
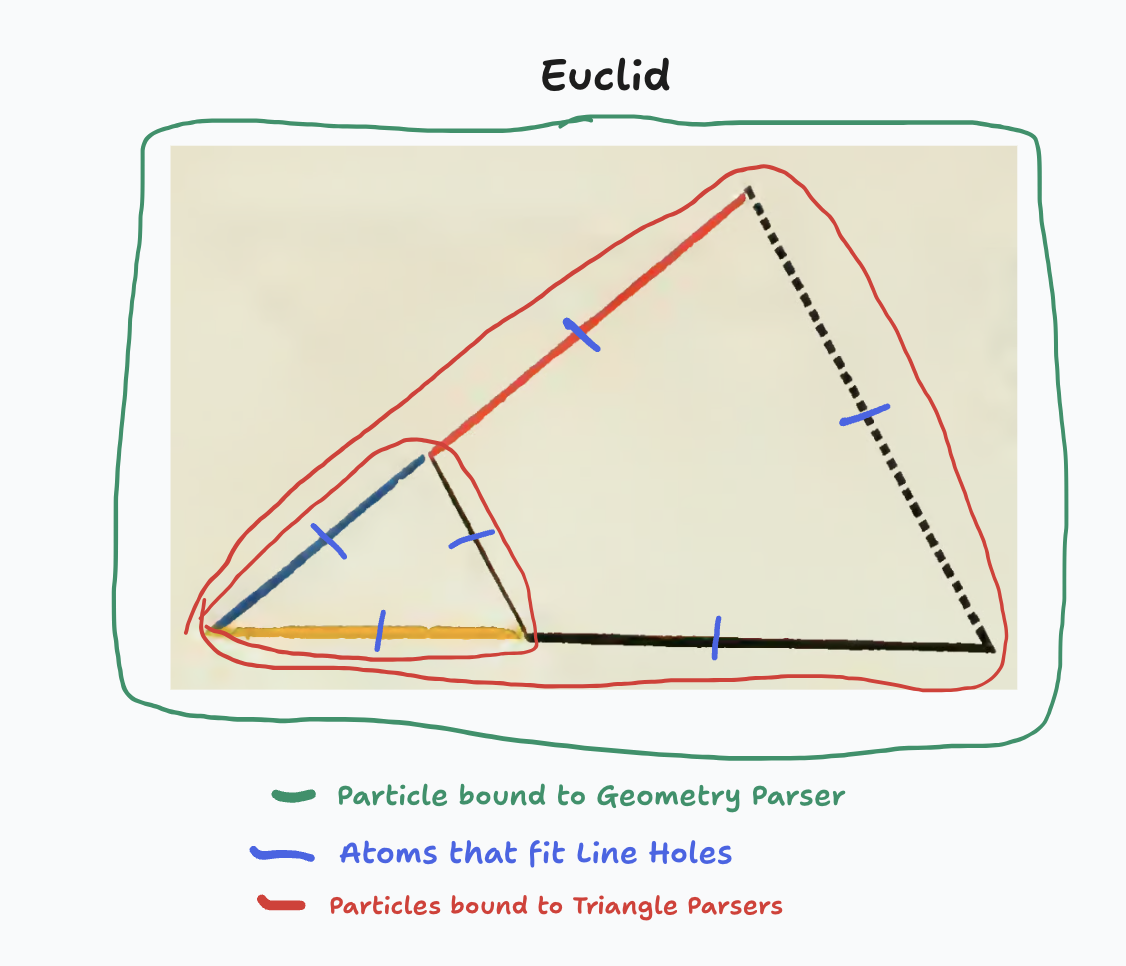
These concepts apply not just to formulae, but to geometry, et al as well.
Related Reading
Here's to the man
Who works with his hands
And regardless of man's plans
Does the best work that he can.
He makes his cuts neat
He applies correct heat
He makes his joints meet
He makes things on beat.
His labor has cost
But the buyer is not boss
The system may add loss
But honest work is never lost.
Pay may be flawed
Cheating may be lawed
But his spirit ungnawed
He presents his work to God.
To understand something is to be able to mentally visualize it in motion in your head. Let's call this a truthful model.
People try to communicate these models in words. At best, these models will be lossy. Often, they are downright fraudulent.
There is a ton of hard earned truth out there, unfortunately it's unevenly distributed and often buried under lies.
Whether the model you are given is a story made of words, or a film documentary, or a 3D simulation, how can you gauge its accuracy?
I developed a technique that is very simple and works very well.
It involves writing down simple facts in a simple way that easily converts to a spreadsheet.
No matter what the thing you are trying to understand is, the trick to getting closer to truth is to build a spreadsheet with:
More:
- Observations
- Dimensions
- Orthoganality
More Observations
Observations are the rows in your spreadsheet.
Let's say you are trying to understand the moon. If you only took 1 "shape" observation in the middle of a lunar cycle, you might say the moon is a half circle.
If you take multiple observations your model of its shape will get closer to a true model.
More Dimensions
Dimensions are the columns in your spreadsheet.
If you not only measure the moon's shape but also it's position in the sky you will get closer to a true model.
More Orthogonality
Orthogonality is a measure of how much redundancy there is in your observations.
If you measure the moon's shape at 100 slightly different times a day from 100 slightly different locations, you've increased the observations and dimensions a lot without increasing your understanding much.
If you were to plant a temperature sensor on the moon or add images from a high powered telescope, you are adding orthogonal data that improves the truthiness of your model.
The idea is you want to not just make many measurements from many angles, but you also want to look at things from wildly different angles. These different perspectives can often be critical for preventing cherry-picked datasets that present overly simplified or misleading models.
The key thing to keep in mind that mining information has costs. It is much cheaper to add more information that looks at things from similar perspectives of existing information. So to arrive at truth you must make an extra effort to add orthoganal perspectives.
You can use this method to build a model to understand anything, no matter how complex.
Of course, the human brain has a limited context window and you can only work on a little bit of your model at one time. To solve this we developed a technology called ScrollSets that let's you chip away at building a model of anything. ScrollSets let's you incrementally build a model, adding as many or as few concepts and measurements at once as you want. Everything is simple plain text, fully tracked by version control, and compiles to a spreadsheet. When a new idea strikes for increasing the orthogonality of your model, it's very easy to add.
"It's more comfortable than it looks."
"And this just v1. By v10 it will be as lightweight as a surgical mask."
"And how long does the gluon encoding last?"
"Thousands of years. Once you've tagged an atom, it's yours for life."
"And the lives of my ancestors."
"Royalties for generations!"
"And how high can you get the coverage?"
"In theory, above 99 percent. The model you're wearing now is doing 5%."
"Incredible. So how many atoms am I claiming right now?"
"Fifty quintillion. Every time you breathe out, the nanopores in the mask gluon-encode fifty quintillion atoms."
"Hey, I'm working hard to make this CO2, I should get paid for it."
"And now you will."
"How much information in each neutron?"
"256 bits. Enough to fit a wallet id.
"I've been waiting years for a business like this."
"Well we've finally built it."
"And tagged air is safe?"
"Scientifically proven. We conducted a rigorous 3 month controlled experiment and observed no harmful effects. Actually, our results are about to be published in Nature."
"Brilliant. What's your go to market plan?"
"Move fast. Create a frenzy. 'Right now 99.99% of oxygen is unowned. Tag your share, before someone else does.' We let people know there hasn't been a land grab like this since the Great Western Expansion."
"How long until the whole atmosphere is tagged?"
"A few decades. It will go slow at first, but once it catches on we expect people will travel to the ends of the earth to find wild neutrons."
"And the revenue model?"
"You get paid when someone breathes your oxygen; you pay when you breathe someone else's. We add a transaction fee on top. The mask tracks it all. We send you a statement each month."
"So some people will turn a profit?"
"Just a few heavy breathers, yes. We've modeled it out. Oxygen rights are reassignable, of course, so we expect most breathers will actually sell their rights to us quite early, and quite cheap."
"So eventually we'll own all of the air?"
"Most of it anyway. Someday we'll monetize almost every breathe. Everyone will be a subscriber, eventually. The greatest business model ever invented."
"But once people are paying more than they're making, what's to stop them from just taking off their masks?"
"We'll make that very hard. Huge PR campaigns. We'll promote the superiority of tagged air versus untagged air. Film, shows, books, schools especially, we'll ensure everyone is taught from an early age that tagged air is the way to go. It will be ubiquitous yet subtle."
"You can also make it capitalism vs communism."
"Absolutely. Shared air is a communist idea. If you're against tagged air, you're against property rights."
"Tagged air for safety?"
"Yes! We forecast that untagged air will increasingly be blamed for more and more incidents. We expect poisonings and other tragedies. I wouldn't be surprised if someday the only ones breathing untagged air are terrorists."
"Is this something governments would support?"
"A government's dream! Imagine laws requiring masks. No one can take a breathe without the government knowing about it. Total control of the air."
"Amazing."
"So are you in?"
"I'll be honest, this is the best presentation I've seen in my career. I'm in. Let's talk valuation."
"Great to have you aboard."
"Do you mind if I keep this one?"
"I hope you never take it off."
"I tell everyone I'm a value-add investor."
"You're helping build a new world."
"Something our ancestors failed to do."
"Here's to tagging all the air!"
There is a job that is currently illegal in the United States, to the great detriment of our citizens. That is the job of "Information Cleaner."
An Information Cleaner is a person who takes in all the material being published in our information atmosphere and cleanses it: they make it transformable, searchable, modifiable, accessible, free of ads and trackers, auditable, connected to other information where relevant, and so on.
These people are not primarily focused on the production of new information, but rather on cleaning and enhancing the information that has already been produced.
This is a hard and extremely important job-think of it like back propagation- and it's currently made illegal by copyright law. As a result, our information environment is as dirty and toxic as an aquarium with no filter.

Our information environment is as dirty and toxic as an aquarium with no filter.
Clean information
Clean information is bits encoded as simply and noise-free as technology allows. Clean information is easy to move and to copy. Clean information is easy to search. It is easy to dice and remix. Clean information has had all toxins removed, such as ads and trackers (or at the least, it is in a form where those can be easily removed). Clean information comes with provenance information. It comes with hashed change information.
Clean information is not Netflix. It is not Prime Video. It is not Disney Plus or Nature.com or The New York Times. All of those are dirty information. Information with DRM; information claiming to be "licensed"; information with a paywall; information without source code; all of this is dirty information. And Americans should be allowed to clean it up.
The Underground Information Cleaners
Now some modern day heroes are clandestine Information Cleaners, building and expanding projects like LibGen and Anna's Archive and archive.today. These people are secretly keeping civilization from tumbling into a dark age.
While they risk their lives and liberty to prevent civilization from collapsing into an information-controlled dystopia, some of us need to be proselytizing in public and making the case as to why Information Cleaning should be a root right, enshrined in the Constitution and revered at the same level as freedom of speech; freedom of the press; freedom of religion.
Information does not lead to a better world; Clean information does
In the past 50 years Americans were misled to think it was the quantity of information that was the thing to optimize for. This is false. The thing to optimize for is the cleanliness of information. It is far better to have the infrastructure in place to clean information, rather than to produce information. It is vastly easier to produce valuable new information once you've cleaned up all existing information.
In that sense, the way to properly incentivize the production of new information is to make legal the cleaning of old information.
If we want to make our air clean, if we want to make our food clean, if we want to make our bodies clean, we first have to make our information clean.
Related posts
- Information is the Easiest Job (2025)
- How to get rid of advertising (2025)
- The Infosphere (2025)
- Movement (2025)
- You Steal Your Software (2025)
- The Consultation Problem and Why Copyright is Dishonest at its Core (2025)
- Tech's Dirty Secret (2025)
- Owned Air (2025)
- All the benefits of property; none of the responsibility (2025)
- Optimizing for Truth (2025)
- A New Coat of Paint (2025)
- The Permission Function (2024)
- Writeable (2024)
- Copyright is a mind virus (2024)
- Patents are Poison (2024)
- ETA!: A Measure of Evolution (2024)
- IPDD (2024)
- The Omni Restaurant (2024)
- The law favors ChatGPT over humans (2024)
- Three Scientists Go To Heaven (2024)
- Why do we subsidize lies? (2024)
- A Mathematical Model of Copyright (2023)
- Enchained Symbols (2023)
- A Public Domain Human (2023)
- SafeFS (2023)
- Training a neural network to spot misinformation, fake news, and propaganda from a single image (2022)
- Cancer and Copyright (2022)
- How the public domain can win (2022)
- Aaron's Amendment (2021)
- The Public Domain Publishing Company (2021)
- An Unpopular Phrase (2020)
- Dataset Needed (2020)
- Dreaming of a Logic Checked Language (2020)
If a pedestrian on the sidewalk is hit by a falling branch from a decaying tree on your property you are liable.
If those who insist on calling copyrights and patents "Intellectual Property" wish to continue to do that, I say we make them embrace all the responsibilities of property as well.
- If © TV programs carry ads for sugary drinks, and sugar turns out to cause many diseases, those TV networks are also liable.
- If actors and actresses star in those © ads, they are also liable.
- If newspaper © pages have ads for painkillers that turn out to be far more addictive than advertised, the paper is also liable.
- If a © textbook contains a model of health that turns out to be inaccurate and harmful, then the publisher(s) and author(s) are also liable.
- If a © song is played on a radio station in between ads for products that turn out to cause harm, the station and the musician(s) are also liable.
- If a non-public domain search engine shows ads for products that turn out to cause harm, that search engine is also liable.
- If a © software program causes its users to lose a signficant amount of time or resources, the software maker is also liable.
- If anyone claiming © over some media fails to update that media as soon as mistakes are discovered, they are liable.
Or do they just want all of the benefits of property rights, with none of the responsibilities?
Related posts
- Information is the Easiest Job (2025)
- How to get rid of advertising (2025)
- The Infosphere (2025)
- Movement (2025)
- You Steal Your Software (2025)
- The Consultation Problem and Why Copyright is Dishonest at its Core (2025)
- Tech's Dirty Secret (2025)
- Owned Air (2025)
- Information Cleaner (2025)
- Optimizing for Truth (2025)
- A New Coat of Paint (2025)
- The Permission Function (2024)
- Writeable (2024)
- Copyright is a mind virus (2024)
- Patents are Poison (2024)
- ETA!: A Measure of Evolution (2024)
- IPDD (2024)
- The Omni Restaurant (2024)
- The law favors ChatGPT over humans (2024)
- Three Scientists Go To Heaven (2024)
- Why do we subsidize lies? (2024)
- A Mathematical Model of Copyright (2023)
- Enchained Symbols (2023)
- A Public Domain Human (2023)
- SafeFS (2023)
- Training a neural network to spot misinformation, fake news, and propaganda from a single image (2022)
- Cancer and Copyright (2022)
- How the public domain can win (2022)
- Aaron's Amendment (2021)
- The Public Domain Publishing Company (2021)
- An Unpopular Phrase (2020)
- Dataset Needed (2020)
- Dreaming of a Logic Checked Language (2020)
If our government is going to make laws governing information, then we should optimize for truth and signal, over lies and noise.
The objective should not be maximizing the ability to make money off of information. Nature provides natural incentives for discovering new truths, we don't need any unnatural ones. In fact, the unnatural incentives on information production actually incentivize lying and noise, rather than truth generation.
I'm surprised this is such a minority opinion, but very few people are with me on this (those that already are---❤️).
What kind of a system maximizes truth?
Well, what is truth?
Truth is when someone publishes a set of symbols with the claim that they accurately predict something about the world and then later sensors verify that those symbols did accurately predict it.
These truths are extremely helpful. They give us warm buildings, useful electricity, cures for disease, lenses to see more, safe transportation, and so on.
There are also kinds of information that might not necessarily make accurate predictions about the world but don't pretend to. Fictional stories or songs or jokes meant to amuse. These are fine and also have natural incentives (the love and admiration from your peers, for example).
Then there are lies. These are symbols that claim to predict things about the world that don't, in fact, hold up when the sensor data comes in. Much of advertising falls in this category.
Finally, there is also noise. Noise is often truths repackaged in extremely verbose, obfuscated, or scrambled order that wastes people's time and can mislead.
Other than total censorship, I cannot think of a worse information policy than the one we currently have in this country, where it is not legal for someone to edit published information and republish their edited versions. Where it is illegal for someone to create a repository of maximal truth.
We need smart people to delete all this noise, to distill all the signal, and deliver truthful, efficient information to the public. This needs to be legal, not illegal.
Truth needs to be the thing to optimize for, not royalties.
It's time for the IFA.
If you could have an AI running continuously on one prompt, what would it be?
Here is my best idea so far. What is yours? Ideas and criticisms encouraged!
Your job is to build an encyclopedia of all knowledge.
Humans should be able to copy what you generate to ink and paper for long term robust storage.
It should define symbol encodings by listing binary sequences with their matching symbol.
It should define atomic concepts out of those symbols.
It should define higher level parser concepts by listing patterns that match against and transform rules.
It should define 2D, 3D, and 4D bitmap formats that resemble phenomena humans observe in nature and link those to the defined concepts.
It should contain knowledge to maximize what it can predict in real world observations (like location of a planet), and not worry about predicting symbolic world observations (like winning lottery numbers or name of a pop star).
Everything should have coordinates in a 4D space.
Continually refine your encyclopedia until it is encodes all knowledge in as few bits as possible.
And our ancestors built a magnificent palace, over thousands of years, layer by layer, with space for all, and our brother added a coat of paint, and said "This is my property now."
Why copyright and patent terms need to be 0
How long should copyright and patent terms be?
There is a correct answer, and that answer is zero.
The progress of arts and sciences depends on rapidly testing novel assemblies of ideas to see if they are good ideas or bad ideas.
If you have a concept of copyrights and patents, then before testing any new assembly of an idea, you have to ensure you have permission to test the idea.
The Permission Function compares your idea with all others to ensure it does not violate any copyrights or patents.
If you run afoul of the Permission Function, you can suffer great legal consequences.
The Permission Function take times and energy to run comparisons, communicate with "owners", and perhaps find workarounds.
The problem is, you don't know how good an idea is until you test it!
You often need to test 100 new ideas to find 1 good idea.
Thus most of your resources are wasted on running the Permission Function on bad ideas.
Why zero?
When you understand the colossal waste of time and energy the Permission Function introduces, you realize that even setting the term of copyrights and patents to 1 year is incredibly harmful, and slows down progress by orders of magnitude.
When the term is 0, there is no Permission Function, and the progress of arts and sciences is unchained.
No AGI will waste energy running a Permission Function. AIs that do will be outcompeted.
Similarly, to survive, humans need to abolish the Permission Function.
Related Posts
- Information is the Easiest Job (2025)
- How to get rid of advertising (2025)
- The Infosphere (2025)
- Movement (2025)
- You Steal Your Software (2025)
- The Consultation Problem and Why Copyright is Dishonest at its Core (2025)
- Tech's Dirty Secret (2025)
- Owned Air (2025)
- Information Cleaner (2025)
- All the benefits of property; none of the responsibility (2025)
- Optimizing for Truth (2025)
- A New Coat of Paint (2025)
- Writeable (2024)
- Copyright is a mind virus (2024)
- Patents are Poison (2024)
- ETA!: A Measure of Evolution (2024)
- IPDD (2024)
- The Omni Restaurant (2024)
- The law favors ChatGPT over humans (2024)
- Three Scientists Go To Heaven (2024)
- Why do we subsidize lies? (2024)
- A Mathematical Model of Copyright (2023)
- Enchained Symbols (2023)
- A Public Domain Human (2023)
- SafeFS (2023)
- Training a neural network to spot misinformation, fake news, and propaganda from a single image (2022)
- Cancer and Copyright (2022)
- How the public domain can win (2022)
- Aaron's Amendment (2021)
- The Public Domain Publishing Company (2021)
- An Unpopular Phrase (2020)
- Dataset Needed (2020)
- Dreaming of a Logic Checked Language (2020)
What does it mean to define a language?
It means to write down a set of restrictions.
Languages let you do things by defining what you can't do.
Languages narrow your choices. You can still take your reader to a land far far away; you just need to take them in practical steps.
Communication requires constraints.
Too few restrictions and someone can write anything, yet communicate nothing.
Even plain text files, which may seem at first to have no rules, have many.
The file you are reading now is a plain text file.
But there's little "plain" about it. It actually is a UTF-8 file. UTF-8 is a language that restricts you to writing sequences of characters, each character represented by a sequence of zeros and ones.
You cannot draw pictures or make sounds or make images or make colors with this language.
Compared to all the messages you could write on a 2D surface, the number of messages that the UTF-8 language allows you to write is tiny.
We should probably distinguish between languages which are defined via definitions and languages that have just evolved undefined alongside us for thousands of years.
Let's use the terms undefined languages and defined languages.
Most of your day is spent using undefined languages.
Undefined languages are the original languages. The languages spoken by the cavemen, the nomads, our earliest ancestors; these are undefined languages. The language a baby speaks to its parents, the language a rooster crows to the hens, the smiles of two soulmates reuniting at an airport, these are undefined languages.
While many publishers create books claiming to Define the English Language, the truth is that English is an undefined language, and that unlike computer languages, the restrictions of English are all fuzzy.
Defined languages are a modern invention, but far older than computers.
Perhaps a legal, or maybe an accounting language, were the first defined language.
Before those, all written languages were defined only by the physical limits of the materials used. You could write any marks, as many as you had the materials for, as big or as little, as distinguished or indistinguished as you'd like.
But it turns out such total freedom had a disadvantage when it comes to communication.
If you want to communicate something specific to your reader, you need to understand what parsers they are going to parse your writing with.
Think of a parser as a memory.
You can't see something you've never seen before. At the very least, it has to be at least composed of things you've seen before.
Likewise, you can't read something unlesss it's composed of things you've read before. So your brain is composed of a large number of parsers, of memories, that are like the restrictions of a defined language.
If your language has no restrictions, then there are no parsers for your readers to memorize, and messages in your language don't trigger anything specific at all. Every reading would trigger a random effect in the reader.
For art, this might be desirable, but for conducting construction, science, medicine, commerce, government; not so much.
So some people started to create defined languages. Perhaps the set of restrictions were communicated orally at first. But then these rules were marked onto a surface.
And then over the centuries many thousands of defined languages were created for math, accounting, law, and so forth.
Then, the invention of electronic computing machines in the 1940's and 1950's led to the creation of thousands of new defined languages over the past 70 years.
Each language defined its own set of restrictions (and thus, freedoms).
It's been a survival of the fittest as to which set of restrictions works best in practice.
It is in this competitive milieu that we are defining our new language stack: PPS.
Back to the original question, why are we defining a new language?
Well, we stumbled upon a simpler set of restrictions that we think make our languages far more efficient, powerful and trustworthy than the competition.
The languages that are dominant today have a lot of unnecessary restrictions, and miss out on a few simple very useful restrictions. These make them unnecessarily complex, inefficient, and not so trustworthy.
When all your messages contain unnecessary pieces, you have zero chance of ever arriving at the perfect message. You're doomed to make suboptimal models from the start.
Our language stack gives humans a chance to build as close to perfect a model of the world as you can get.
Unnatural additions and inefficiencies stick out like a sore thumb. This makes it a compelling choice for governments, engineers, scientists, and so on.
The new set of restrictions in the PPS stack allow us to do the same things in more natural, simpler, more efficient ways.
Your body has approximately:
30,000,000,000,000 Cells
and
30,000,000,000,000,000 Mitochondria!!!
So yeah, mitochondria are very important.
Everything goes in cycles.
So it surprises me there's not yet a word "mitocycle".
Mitochondria were first seen with optical microscopes in the late 1800's.
In the 1950's electron microscopes gave us our first good look at them.
Now we know that they are extremely important for health.
And that a lot of modern foods and lifestyles have proved harmful to them.
When will we have mitometers?
What is the optimal population?
Are your mitos high right now, or low?
Are they wiggling fast or slow?
What are their natural cycles?
I believe the term "mitocycle", will be important in the future.
It's been 134 years since the first published drawings of mitochondria
What Richard Altmann saw under a microscope in 1890. Source
Now we have some amazing videos:
Look at these guys wiggle! We are wiggling worms!
We're building a new blockchain (L1).
This chain will leapfrog all others on trust and speed.
We will be misunderstood, ignored, and mocked.
And then, our math will win.
-Breck

Alejandro writes of an exercise to describe something in two words.
To him Scroll is "semantic blogging".
His Scroll blog is "a database of [his] knowledge."
He then asks what two words I would use for Scroll?
While Scroll is also semantic blogging to me, if I could only pick two words I'd go with: particle thinking.
The Big Questions
I like to ponder life's big mysteries.
Why are we here? How do things work?
Figuring out life's mysteries is like moving a mountain.
How does one move a mountain?
Two approaches come to mind: the philosophical approach and the engineering approach.
The philosophical approach is to change your question or perspective. A mountain from a different perspective can be a pebble, coverable with one thumb.
The engineering approach to moving a mountain is "bit by bit".
Particle Thinking
Particle Thinking is the bit by bit way.
All of these words you are reading now can be constructed with 2 particles: a particle and an anti-particle. You then use many of those as subparticles to build letter particles, and then combine those to get word particles, and then list particles, and then parser particles, and then language particles, and then encyclopedia particles, and program particles, and operating system particles, and lowly blog post particles like this.
It's particles all the way down.
Particle Thinking Pays Compound Interest
What's so good about this approach?
Learning is programming except instead of creating functions in code you are creating functions in neurons. Like programming, a poorly created function can be vastly slower than a well crafted one. Evaluating mental functions takes time and requires energy. If your neural functions are wasteful you will compute slower, miss optimal thoughts, and waste a lot of ATP.
If instead, you refine your thinking to where you understand exactly what concepts are necessary and what are not, you will think faster, come up with better ideas, and have more ATP to spend on enjoying life.
Do this for years, and then decades, and your savings compound.
So those would be my two words for Scroll: particle thinking.
I want a language that helps me be a great thinker, to get the most out of my limited neurons, and use neural ATP most effectively.
And I want a language with a community of other people that think like this.
And I want a language that gives me a another way to try and move mountains.
What do you think? What two words would you use to describe Scroll?
Every accomplished person I've studied has a quip about focus.
Ability to focus separates humans from animals.
Humans have dug 1,000x deeper than the deepest animal and flown 40,000x higher than the highest bird.
And among humans focus separates the lay from the legends.
Why does focus pay?
Because payoffs in nature are non-linear. And it's finisher take all.
If you get 99.9% of the way across the sea you get 0% of the benefits. That last 0.1% is worth everything.
Sustained focus allows humans to hit otherwise unachievable payoff points.
To pass a payoff point you need sufficient pressure.
Your force supply is limited so you need to concentrate it at a small area.
How do you measure focus?
Identify the one thing you should be focused on.
Our universe has made everything vastly unequal so you should always clearly see one thing far bigger than others.
Now measure what percentage of your thoughts are on that one thing.
Resist distractions. You can blur and attend to other matters once you've finished your one thing.
What about blurring?
Don't worry about blurring. Worry about underfocusing.
I've never met a single human who has overfocused.
Everyone overblurs.
We have dozens of biological cycles that force us to blur.
You blur every time you take a walk, go to sleep, take a pee, eat a meal, et cetera.
Focusing is the thing to practice.

A New Scientific Model of Mania and Depression, with Testable Predictions
by Breck Yunits
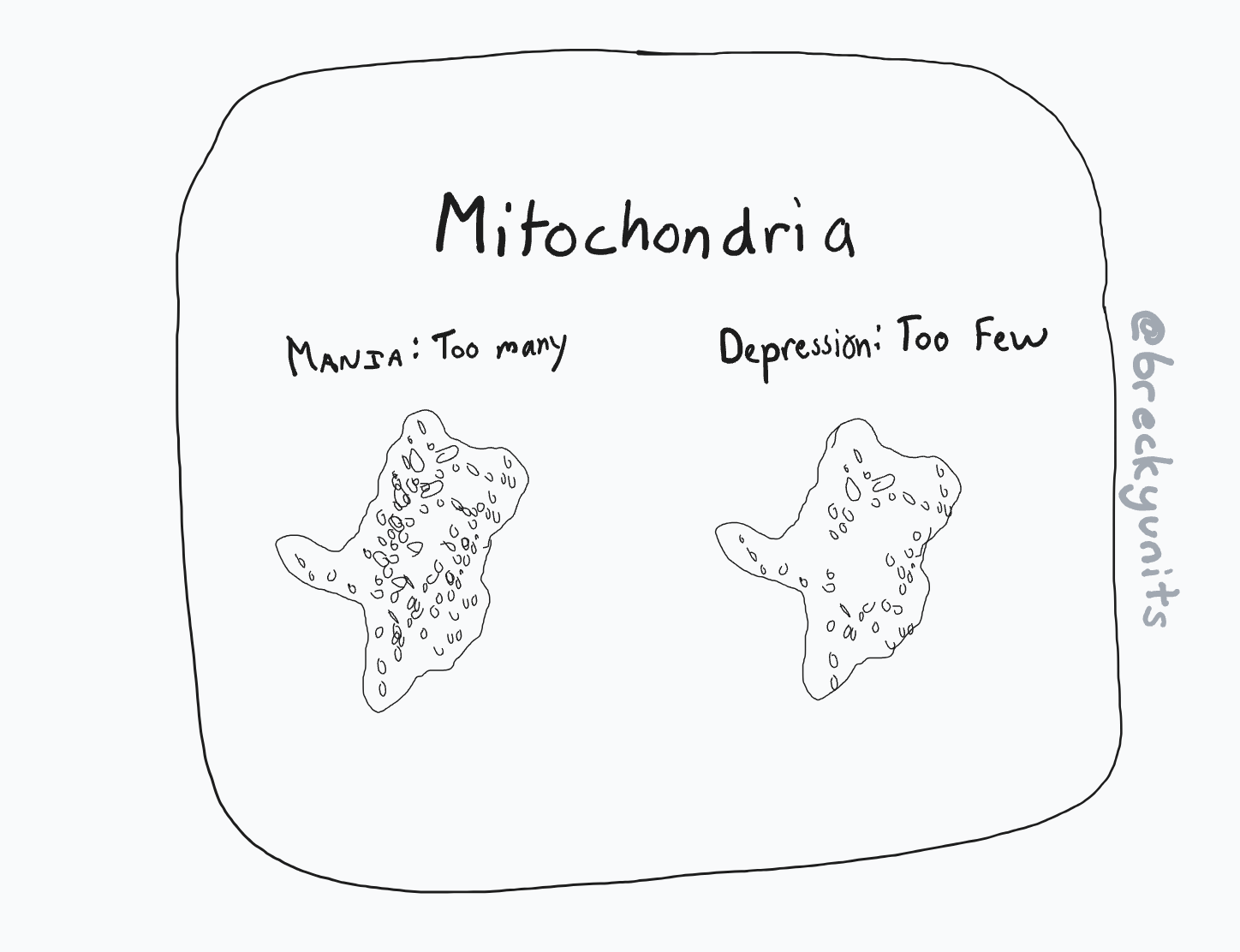
The model proposed here. Mania is too much mitochondria; depression too little. We predict it is possible to detect mood state from optical images of certain cells and counting mitochondrial volume.
Mania is too much mitochondria; depression too little.
Mitolevel is mitochondrial volume divided by cell volume (ML = M/C).
Mitolevel varies by cell type.
The mitolevels in certain cell types will be strong predictors of current system wide mood state.
Mania is elevated mitolevels and depression is depressed mitolevels.
Individuals who have experienced mania frequently report a feeling of quickening or acceleration, which matches this model as self-reproducing mitochondria change population exponentially over time.
Individuals who experience severe depression take a long time to recover, which matches a model where the cell is depleted of mitochondria (likely from dead mitochondria from resource exhausition during a manic episode) preventing the restoration of a healthy mitolevel.
Mitochondrial populations change much more gradually than substance levels in the bloodstream, which explains why mania is described as a "sustained high" and why depression can't be immediately "snapped out of".
Predictions
- Abundant lab evidence. Someone will discover a human cell type whereby one can reliably and abundantly predict mood-energy state of the whole person simply by measuring the mitolevels of a cell sample.
- At-home mitolevel tests. Someone will organize a large number of people in different mood-energy states to contribute to a large dataset of microscopic images of mitochondria from various cell types and then, using this reference, cheap at-home tests of mitolevels using simple staining, consumer microscopes, and machine assisted counting will be developed.
- Millions cured. High fat, low glucose diets will cause stabler mitolevels and radically reduce episodes of mania and severe depression
- A Universal Condition. Any human being can experience mania and depression through manipulation of their diet and/or environment to force high or low mitolevels.
New Terms
I believe eventually the phrase "bipolar disorder" will be retired, as it is a false label. I propose "hypermito" - for the state of having too much mitochondria; and "hypomito" - for the state of having too little. (Actually, "mitohigh" and "mitolow" sound even better.)
Read more
As one can assume, hundreds of works directly contributed to the model above. Some of the key resources:
- Dr. Iain Campbell
- Metabolic Mind
- Bipolar Cast
- The Cell, Chapter 7, Don W. Fawcett. 2nd Edition. 1966
- Chris Palmer
- Shebani Sethi
4/14/2025
Tech Innovation Curves
4/05/2025
The Lisp Enlightenment Trap
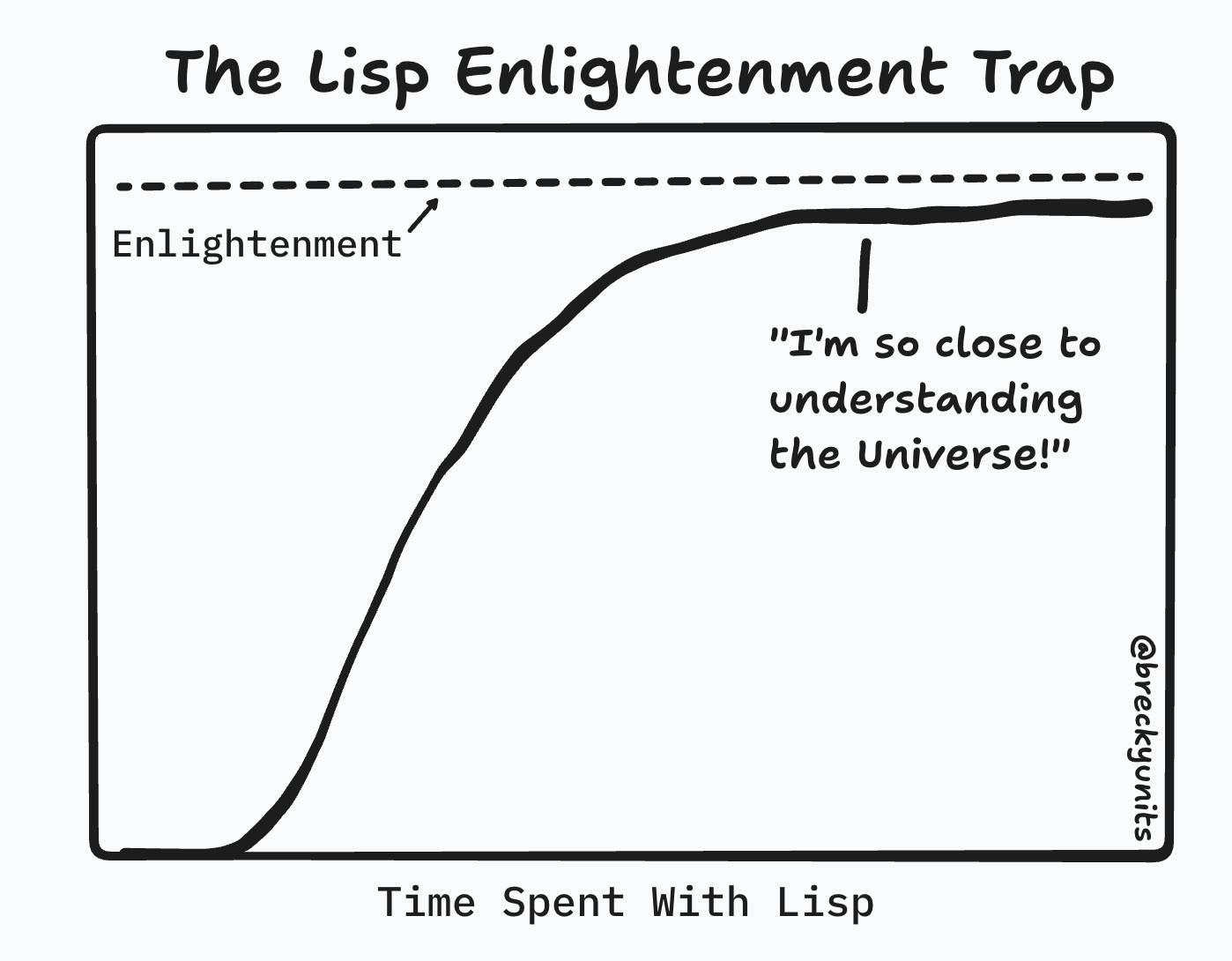
12/06/2024
Questionable Engineering

11/24/2024
Inequality

11/12/2024
Focus
11/10/2024
Constants

11/8/2024
These 0.00000000001% atoms rule the world

Cannibals

11/6/2024
Circle of Life

11/5/2024
Data

Billionaires
Made with: tldraw; Apple Pencil, iPad Pro, and MacBook Pro; feedback from ChatGPT. Newest comics made with Daylight Computer.
If you could see everything across space and time, we would not need to read and write.
You would not need words to tell someone how blue the Pacific can be because they could just see it.
You would not need words to learn when your grandfather decided your grandmother was the one because you could just see everything he saw.
But we can't see everything.
We can only see what's in front of us at this moment.
This is not optimal for our health.
Our Universe is mostly mystery, but at least we know there are patterns.
And if you can learn these patterns, you can have a better time.
To learn a pattern you first must see it.
Our ancestors could only see with their eyes.
Some lucky descendants evolved the ability to imagine things that weren't there.
Language requires imagination.
Once we could imagine, symbols could evolve.
A discoloring on a surface.
A mark to communicate a pattern.
What was the first mark?
What was the first symbol?
Let's imagine.
A man sees a cave.
It is cold and getting dark.
He approaches, but then lurches back.
He sees a bear!
He holds his spear and prepares for battle.
But the bear does not move.
He looks closely.
It is not a bear, but simply charcoal discoloring the wall.
He remembers the shadows his companions make around the campfire to communicate they saw a bear.
He thinks perhaps one of them rubbed charcoal to make a permanent shadow.
He finds a different cave.
In the future, when he sees bears, he grabs some charcoal and repeats the symbol.
Perhaps it was something like this that kickstarted writing.
Pictures at first, then pictographs and eventually phonetic alphabets where infinite patterns could be composed and communicated.
Tens of thousands of years later, here we are with huge numbers of people who spend their days drawing charcoal bears.
Our tribe now uses writing (or at least, pretends to use writing) to set the rules.
These include rules about writing.
What should the rules on writing be?
What is writing good for?
Is it the writer that is most important, the symbols, or the reader?
Writers have clear incentive to create symbols since that very first symbol: symbols save lives.
Even if it's not your own life, or your child's life, even if it's a complete stranger's life, we have learned that a civilization of strangers cooperating peacefully create a better world for all.
But writing goes out of date, and if the writer doesn't update their symbols, they can mislead as easily as they can lead.
It can't be the writer that is most important.
The symbols themselves, without humans, are literally meaningless. So it can't be the symbols that are most important.
Thus it is clear the most important thing is that the rules around symbols should benefit the readers.
What can we do to equip readers with the best symbols possible?
What if bears learned to write?
We might not be here.
Our ancestors might have seen an idyllic image of a cozy cave and walked right into a bear's mouth.
Lies kill.
Can we protect ourselves from writing bears, from lies?
How do we make the most from symbols?
The trick is to make symbols as honest as possible.
And how do we do that?
Bears want nothing more than to outlaw writeability.
Bears do not want you to spread the truth about their cave.
They don't want you to know what's really inside.
And so to do that, not only do they lie about what's inside, but they make their wall unwriteable.
They do not allow edits. They do not allow transformations.
Bears make symbols to serve themselves, and themselves alone.
And by doing that, they lead people to slaughter.
To make symbols the best for readers, symbols must always be writeable.
All symbols should be writeable.
Do not trust anyone who wants to restrict your rights to write.
Everything I own is in the overhead bin.
This is cool if you are 20.
But I am 40. I have two kids.
At 40 this is a bit extreme.
The kid next to me is 20.
She is a computer science major.
We talk about languages.
I play dumb and mostly listen.
She is wondering which language to use.
Her ML class uses Python.
Her OS class, C++.
For fun, she uses Javascript.
I suggest she enjoy them all.
It's like traveling.
Learn the place in front of you.
You will visit many.
The topic comes to my work.
I used to be shy about it.
Terrified of misleading.
Not anymore. I demo.
Scroll is very practical.
We make useful things fast.
Right there on the plane.
With no internet.
I explain Scroll is like a game.
To play you put a subject into symbols.
To win you cover it all with no extra parts.
The prize is you've figured it out.
To pack so light I've filtered objects.
Kept only the most useful ones.
To write Scroll is to filter symbols.
To keep only the most useful ones.
October 29, 2024 — The censors do not want you to read this post.
They will downvote, flag, takedown, block and use any and all means to suppress these ideas.
They will call me names: a crank, crazy, unhinged, conspiracy theorist, lunatic.
They will say he is not a creator (I am), has created no hits (I have) and whatever else they can do to suppress this, short of responding to the ideas presented here.
Because they know that if they respond to the ideas then they will encourage you to actually think about them, and they know that if you start to think about them they've lost, because they know what I'm telling you is nature's simple truth.
That terrifies the censors. They know the stickiness of truth. They know that truths can be hard to see, but once you've seen truth you can't unsee it. Brains prefer shortcuts. And truths are shortcuts for predicting the world.
I'm giving you a shortcut to explain many of the problems in modern America: unnatural inequality, poor health, declining life expectancy, violence, poverty, misinformation, fake news, distrust in media, et cetera.
What is a shortcut to explain the root cause of many of these health problems?
Copyrights.
Copyrights they tell you are helping us are actually hurting us.
Copyright pauses progress
Every single great idea started as a bad idea that evolved in a competitive environment into a great idea.
This applies to any and every great work that has a © slapped on it: every song, book, article, photo, movie, program, et cetera.
No idea ever reaches perfection.
Every idea can always be improved. Every idea can always keep evolving.
What does copyright do? It makes evolution a crime.
It says: no more evolving! This idea needs to stay exactly as is until 70 years after the "owner" dies!
This is literally the dumbest idea I can think of, short of total censorship.
Copyright is a mind virus
But copyright is even worse than just being a terrible idea: it's a terrible idea that has spread like a virus.
For example, 9 out of 10 of the top websites in the USA spread the virus to all their visitors. And the one that doesn't have the virus on its homepage, Google.com, has the virus on most of its other pages.
Copyright has no redeeming qualities, except for enriching a few at the expense of the many.
You can listen to every argument made by the spreaders of this virus, but you will not find a single honest one.
All of their arguments are mathematically flawed.
Their best strategy is not to actually convince you they are right-they know they are wrong-but to delay you from seeing this obvious truth as long as possible, because they make so much money every year you don't see it.
If you want to read honest material about this, here's a place to start.
Fight the Virus
You can help! If you run one of these companies, start cleaning up your house! Remove all © symbols from all pages. Remove all uses of the word "license" when talking about ideas. Make it clear that everything you are publishing is public domain.
If you are just an average citizen, you can help too! Tell everyone you know about the harmful effects of the © mind virus. If you have technical skills, start sending pull requests removing the © virus from open source projects.
Together we can rid the world of this mind virus and create a world where bad ideas are once again forced to evolve into good ideas.
October 27, 2024 — The censors do not want you to read this post.
They will downvote, flag, takedown, block and use any and all means to suppress these ideas.
They will call me names: a crank, crazy, unhinged, conspiracy theorist, lunatic.
They will say he is not an inventor (I am), has no research background (I do) and whatever else they can do to suppress this, short of responding to the ideas presented here.
Because they know that if they respond to the ideas then they will encourage you to actually think about them, and they know that if you start to think about them they've lost, because they know what I'm telling you is nature's simple truth.
That terrifies the censors. They know the stickiness of truth. They know that truths can be hard to see, but once you've seen truth you can't unsee it. Brains prefer shortcuts. And truths are shortcuts for predicting the world.
I'm giving you a shortcut to explain many of the problems in modern America: the opioid epidemic, cancer, obesity, mental health, the "pandemic", et cetera.
What is a shortcut to explain the root cause of many of these health problems?
Patents.
Patents they tell you are helping you are actually poisoning you.
Some points of agreement
First, there are some points I think we can all agree with. Patents are awarded to novel inventions that have plausible utility. Patents encourage the publication of those inventions in some form. Patents are effective at discouraging unlicensed competitors and do create monopoly pricing power.
I agree with all those points.
But now let me present a new way to look at things.
What is a patent?
A patent is embodied as a digital PDF. A PDF is just a long binary number.
Thus one can accurately say a patent is a long, seemingly random number.
The patent "owner" makes money by people paying to use that random number.
Patents incentivize the wrong thing
Patents do not incentivize solving problems. Patents incentivize convincing people they need your random number.
If you've got a patent on a random number, you make no money if people solve their problems without your random number, but monopoly money if they use your random number (regardless if it actually solves their problem).
As a result, companies are coming out with all sorts of random numbers that are great at generating monopoly profits, but terrible at solving people's problems.
More patents, more problems
Even better than just making monopoly money from one random number is to make monopoly money from a suite of random numbers.
Convince people that they need food made by your patented machines; foods that cause illnesses; illnesses which you say can only be cured by your patented medicines; medicines which cause side effects that you claim can only be cured by your other patented medicines; and your royalties will be royal!
Of course, your inventions are only solving problems that your other inventions created, but most people don't know that and so you can go on posting your stamped US Patent Certificates on LinkedIn and boasting about what a great innovator you are.
Patents stifle innovation
The worst thing that can happen to a patent holder is that someone actually figures out a solution to the problem their patent claims to solve while their patent is active.
Thus, once someone is granted a patent, they have strong disincentive to actually solving someone's problems.
You do not want to publish or even fund anything that might show that your random number does not actually work.
You want to sit back and tell yourself "job well done" while collecting royalty checks.
Patents incentivize addiction
What's even better than selling an addictive drug? Having a legal monopoly on an addictive drug!
Patents richly reward those who can get vast numbers of people addicted to their random number.
This is exactly what happened with Purdue and the opioid epidemic. If you look at the legal docs, you'll see that step 1 in Purdue's playbook was to build an aggressive patent strategy.
Patents incentivize censorship, information control and dishonest advertising
We've all seen how much big pharma advertises. Why on earth would they need to advertise their life saving medications?
Surely no news would travel faster by word-of-mouth than life saving inventions!
Unless of course, these medicines are not life-saving at all?
If the life saving inventions were the unpatented ones, then the only way for businesses to profit off patents would be to convince you of a lie.
Truth is free. Lies require advertising.
If you have to choose between owning a business with a monopoly or owning a business in a competitive field, the former makes far more money. The only requirement is you must dedicate a portion of your proceeds to brainwashing customers that they need your random number (they don't)!
I don't care if you share this post, but please do share these ideas
I could drone on and on along these lines, but I want to keep this (reasonably) short.
Please think about this for yourself: what do patents actually incentivize? Don't just repeat what people tell you they incentivize. Think about it from first principles.
I am not in this for the money.
I am in this for the friends that I have lost.
Some of my best friends on this planet.
Dead. Buried. Poisoned by patents.
Again, don't take my word for it.
Please think about these ideas for yourself.
And remember that's exactly what the other side doesn't want you to do.
A collection of strong advice for those doing startups.
by Breck Yunits
Publish early and often: I don't know of a single polished world changing product that did not start as a shitty product launched, iterated, and relaunched to increasingly larger groups of people. Even the iPhone went through this process.
Make something you love: I don't know a single person who makes something they love and is not successful and happy. I know people that make something people want and make money but are unhappy.
Master your crafts: I don't know a single person who built anything worthwhile who didn't have at least ten years of practice mastering their crafts.
Befriend other pioneers: I don't know anyone who started a successful colony who didn't make friends and trade help with other colony starters along the way.
Take care of your health: I don't know of a single founder who achieved success and didn't eat well, sleep well, take a lot of walks, enjoy time with family and friends, and write a lot.
Become skilled in all ways of contending: I don't know of a single founder who built a great organization who didn't master many complementary skillsets (sales, marketing, cash flow, fundraising, recruiting, design, et cetera).
Strong Startup Advice from others:
Talk to users: I don't know of a single case of a startup that felt they spent too much time talking to users. - Jessica Livingston
Read: in my whole life, I have known no wise people (over a broad subject matter area) who didn't read all the time – none, zero. - Charlie Munger
Cold emails: Every single person I’ve interviewed thus far, even those working with billions of dollars, have all sent cold emails. - Sonith Sunku
Bit
Persistence
Direction
Boundaries
Cloning
Randomness
Assembly
Decay
What else?
I make many scratch folders and often hit this:
$ cd ~
$ ~ mkdir tmp
mkdir: tmp: File exists
$ ~ mkdir tmp2
mkdir: tmp2: File exists
$ ~ mkdir tmp22
mkdir: tmp22: File exists
Now I just type sf
$ sf
$ 2024-10-19 pwd
/Users/breck/sf/2024-10-19
The line I added to ~/.zprofile:
alias sf='date_dir=$(date +%Y-%m-%d) && mkdir -p ~/sf/$date_dir && cd ~/sf/$date_dir'
by Breck Yunits
All jobs done by large monolithic software programs can be done better by a collection of small microprograms (mostly 1 line long) working together.
Microprogramming is a style of programming inspired by Microbiology

Building these microprograms, aka microprogramming, is different than traditional programming. Microprogramming is more like gardening: one is constantly introducing new microprograms and removing microprograms that aren't thriving. Microprogramming is like organic city growth, whereas programming is like top-down centralized city planning. Microprogramming is putting the necessary microprograms in a petri dish, applying natural selection over time until they can beautifully and most simply solve your problem.
In a microprogram every line of code can be its own program.
| Type | Files | Lines Of Code | Programs |
|---|---|---|---|
| Programming | 1 | 1000 | 1 |
| Microprogramming | 1 | 1000 | 200-300 |
Microprogramming requires new languages. A language must make it completely painless to concatenate, copy/paste, extend and mix/match different collections of microprograms. Languages must be robust against stray characters and support parallel parsing and compilation. Languages must be context sensitive. Languages must be homoiconic. Automated integration tests of frequently paired microprograms are essential.
Microprograms start out small and seemingly trivial, but evolve to be far faster, more intelligent, more agile, more efficient, and easier to scale than traditional programs.
Microprogramming works incredibly well with LLMs. It is easy to mix and match microprograms written by humans with microprograms written by LLMs.
These are just some initial observations I have had so far since our invention of a breakthrough microprogramming language stack. This document you are reading is written as a collection of microprograms in a language called Scroll, a language which is a collection of microprograms in a language called Parsers, which is a collection of microprograms written in itself (but also with a last mile conversion to machine code via TypeScript).
If the microprogramming trend becomes as big, if not bigger, than microservices, I would not be surprised.
Microprogramming is inspired by microbiology.
You may know me as the creator of PLDB (a Programming Language DataBase), earth's largest database on Programming Languages, and find it relevant that I have personally studied and reviewed information on over 5,000 programming languages - nearly 100% of all publicly used languages.
What you might not know is that I also have a peer-reviewed track record in genomics and multiomics, and that Parsers, the language we invented that enabled Microprogramming, is built not on the patterns I found in programming languages, but instead built on the patterns nature evolved that I studied in microbiology.
The biological design is why this stack is unlike any language you have used before. You will be able to build any advanced program you could build using a traditional language, but the path to that solution may be very different. Once you've mastered this stack, I expect you will be astonished at how much you can do with so little.
The payoff from this biological approach will become increasingly apparent over time, as we continue to do things with this stack with radically less code than traditional approaches.
This is the dawn of a new paradigm shift in programming, and my job is to provide you with the truest, clearest, most concise information I have gathered over the past two decades so you can take this technology and build a better future for us all.
Q & A
yuri-kilochek asks "what is a microprogram? How is if different from a procedure?"
comment Good question! This line is a microprogram.
commentParser
comment This block is also a microprogram
pattern comment string*
comment Microprograms are 1 or more lines that are as easy to move around and concatenate as legos. It is accurate to model them as functions that take zero or more parameters. Each line/block is a function definition or application.
hugogrant points out "That's a lot to claim without any data."
Great point! I should mention some data.
Parsers is made of ~100 microprograms.
Scroll is built on Parses and made of ~1,000 microprograms.
PLDB.io is built on Scroll and made of ~10,000 microprograms.
Psychoscattman asks "But what is micro programming? This blog is just a collection on observations but doesnt explain at all what microprogramming is or how it works."
Great question!
Microprogramming is using languages where every single line is capable of being a microprogram.
Below is an example of microprogramming. This is the code that generates the homepage for BuilderNews https://news.pub . I annotated everyline to explain it in the terminology of microprogramming.
You can also view and edit it with syntax highlighting.
// A 1 line microprogram that sets some top matter information for html meta
title BuilderNews
// A 1 line microprogram that sets some top matter information for html meta tags
editUrl https://github.com/breck7/news.pub
// A 1 line microprogram that sets some top matter information for html meta tags
description News for builders.
// A 1 line microprogram that includes more scroll code
header.scroll
// A 1 line microprogram that outputs a div tag
<div class="container">
// A 1 line microprogram that outputs a h1 tag
# BuilderNews
// A 1 line microprogram that outputs a h3 tag
### Watch people try your web creations for the first time.
// A 12 line microprogram that reads a csv file, runs a dataflow pipeline and outputs html
table tries.csv
rename url creationLink
select rank creation creationLink user date
rename user tries
orderBy rank
groupBy rank
reduce date first date
reduce creationLink first creationLink
reduce creation first creation
reduce tries concat tries
select rank creation creationLink date tries
printTable
// A 2 line microprogram that adds links to a piece of text and outputs html
Build something new to try? Email a title and link to one of our users.
link users.html users
// A 3 line microprogram that adds links to a piece of text and outputs html
Download this data as JSON.
link tries.json JSON
https://github.com/breck7/news.pub/blob/main/tries.scroll this data
// A 1 line microprogram that includes the content of this html file:
modal.html
// A 1 line microprogram that runs "import":
footer.scroll
// A 1 line microprogram that outputs an html div tag
</div>
// A 1 line microprogram that outputs a javascript tag
tableSearchredneckhatr asks "How does this work underhood? Is a microprogram an actual binary or something you load into a VM?"
Great question!
That's up to the implementation. This is a design pattern that can be implemented in many ways. Even without a computer!
Requirements to implement this:
- An environment
- Microprogram parsers
- Microprograms
Here's a video explanation:
loblawslawcah says "The post didn't really show or explain it all that well."
Perhaps a video explanation would be better:
Is your liver on right now? You can find out with a drop of blood.
If your ketone levels are around 0.1, your liver is off.
If they are around 1,0, your liver is on.
It's easy to tell, once you've measured.

This is me pricking my finger to test my ketone levels. I got 1.3 mmol. My liver is on!
I was at a gathering of liver surgeons last night and none of them had realized this before: that the liver turns on and off.
Perhaps it's because my background is in computers that I immediately recognized when something goes up 10x, that indicates something has gone from "off" to "on".
Is it bad for my liver to be off most of the time?
It's generally not healthy to keep your major organs in the off state. If you never open your eyes, you go blind.

The liver is the largest organ in your body. It's probably extremely important to keep this thing on.
I tested my blood and my liver is off. How do I turn it back on?
There's a lot of good places to start learning, but in two words: avoid carbs.
Notes
- Yes, I know the liver does many things in addition to making ketones. But if you are sitting in your parked car listening to the radio and haven't yet started the engine, we would say the car is off. Making ketones is the main thing.
I finally built a product I love.
It took me 15 years.
Make something people want is weak advice.
Make something people want is easy.
You want with reservation.
Love?
You love with everything.
I have never met someone who made something they love who was not fulfilled and successful.
2009
I was 24 years old and riding in a van driven by Brian Chesky. Joe Gebbia was shotgun, and Nate Blecharcyzk was to my left. They had been iterating on AirBedAndBreakfast all day but finally were fatigued and ready for bed in San Francisco.
We were driving back from another Tuesday night dinner in Mountainview, where another entrepreneurial dynamo, Paul Graham, had spent time with us, in between darting to a backroom to iterate on his own young creation, a product called HackerNews.
The enthusiasm of all of these guys for their products beamed through like a rising sun. At the time, my projects were making more cash and had more traffic than AirBedAndBreakfast and HackerNews combined, but I knew the truth: my stuff was dogshit and I was doing it wrong. Whatever these guys were doing, that's what I wanted to do.
But how?
How to make something you love.
Practice
I've never heard of a single exceptional founder who wasn't a master craftsman. Before Paul Graham created HackerNews or even Viaweb, he had already gotten a PhD in Computer Science from Harvard and had published a book on Lisp!
Before Nate joined Airbnb, he was already an accomplished software engineer with (IIRC) 7 figures in earnings under his belt. As for Chesky and Joe, they've published brilliant drawings and products they made over a decade before founding Airbnb.
Even if you are a prodigy, I've never heard of anyone build something they love without more than a decade of practice of their crafts.
Publish
I don't know of anyone who has left a mark on the world who had thin skin.
Develop thick skin by constantly subjecting yourself to feedback and be grateful for it, even when it is delivered poorly. Harsh criticism is the crucible that forges strong ideas.
If you truly love your ideas you would publish them freely and never encumber them with patents or (c)opyrights. That would be like chaining up your children in the basement.
Ponder
Every great founder I know walks a lot and is constantly reevaluating things in their head. They make sure they are working on the most important things, not missing obvious improvements, and are investing in the areas with highest long term ROI.
This is how you figure out what the world needs you to make. As you publish the world provides feedback. You know what you need. The world will tell you what it needs. Ponder and find the overlap!
Pace
Every founder I admire made it to old age (I'd have more to admire but for the occasional unlucky lightning strike) and to do that you need to master your health and learn to go at a steady pace. This is a big area that used to be a weakness of mine.
Love versus Want
For every product that a billion people love, remember that 99.999999% of people only loved it after 10 people already loved it.
How do you get 10 people to love your product?
You've got to love it yourself.
It's going to take a while.
But it's so worth it.
Flaws in Heaven
A Redditor gets hit by a truck
He goes to the afterlife.
It's amazing.
Mansions for everyone.
Gourmet meals.
Perfect sunsets.
But the Redditor is able to find a few negative things to focus on.
He writes an email to God with subject "Flaws in Heaven".
He gets an immediate response.
MESSAGE NOT DELIVERED
Heaven doesn't want to hear
your bullshit, that's why
they sent you here.
- Hell Outlook Server
The Galton Board
Mark Hebner and his team have refined an 1889 invention from Francis Galton and made a version you can hold in your hand to conduct real world probability experiments 10,000 times faster than flipping a coin.
It's the best $99 I've spent all year.
Since you loaded this page you could have performed
0 coin tosses
0 hebner hops
Fun notes
- Tilting the board is a fun way to explore bias.
- Fascinating to watch pileups and other phenomena that impact distributions.
September 6, 2024 — I emailed this letter to the public companies in the current YCombinator batch.
Aloha S2024 batch,
I'm writing today to give you 1 piece of advice that I wish someone had told me when I was in YC: demand carry from YC for your batch.
Today you are the S2024 batch.
In 15 years you will be the X batch, where X is the name of whichever of you goes on to become the biggest hit.
By this naming convention I was in the Airbnb batch. And the Stripe batch. What luck, eh ;) ?
These Xs make YC its money.
But what makes these Xs?
The founders are #1, of course, but what else?
Here's YC's dirty secret: it is not the Partners or the Office Hours or Demo Day that makes these Xs.
Nope, not even close.
The Partners, the Office Hours, the Demo Day will be irrelevant to your startup compared to the long term impact your batchmates will have.
As founders you are building new colonies in the wilderness.
In those hard early years, you will depend on and be saved and elevated by your batchmates.
So, why do the people who do all the work get 0% of YC's carry?
YC's legal team will give you many laughable excuses.
The real reason is simple: a batch hasn't demanded it yet.
I used to be a moral compass inside YCombinator. Until they expelled me.
But losing access to Bookface is nothing compared to what happened to the previous moral compass, and my hero, aaronsw.
I believe in YCombinator and its ability to do good. But power does funny things to people, and I urge you to organize now, demand your rightful share, and ensure that there are some checks and balances on the YC partners.
Good luck, and feel free to reach out to me at any time, day or night. I want the best for you all.
Now, go make something the universe wants!
Best,
Breck
Notes
- To be clear, my issue is not that I got a bad deal: my batchmates helped me out more than I helped them. My issue is the unethical behavior of the current YC partners, and reducing that that by restributing the profits of YC in a way that more fairly matches the value of their contributions.
- "carry" could also be accomplished via an equity pool.
- A reader told me about founderpool.co, which looks like it is trying to do this at scale.
- A reader informed me that First Round Capital tried something like this. If anyone has data they can share on whether this is true, would to see it.
Trust, and understand.
by Breck Yunits
Is there a better way to build a blockchain? Yes.

A Particle Chain is a single plain text document of particles encoded in Particle Syntax with new transactions at the top of the document and an ID generated from the hash of the previous transaction.
Particle Chain is a syntax-free storage format for the base layer of a blockchain to increase trust among non-expert users without sacrificing one iota of capabilities. A Particle Chain can be grokked by >10x as many people, thus leading to an order of magnitude increase in trust and developers on a chain.
RPM
RPM states that R, the reliability of a chain, is the number of particles P times the number of independent mirrors of the chain M.
Chains that are mirrored more with more history are more reliable.
Implementing
The chain itself is encoded in Particles (Particle Syntax) which could be done with pen and paper, though for more utility it is recommended to build a digital Particle Chain 😉.
For implementing a digital Particle Chain, the Parsers Programming Language (or a similar compiler compiler and virtual machine) may be used.
All existing chains such as Bitcoin, Ethereum, and NEAR could be converted to a Particle Chain in a straightforward manner.
New chains would likely want to build on a Particle Chain from the start.
"I don't care for the heels", she said.
I knelt.
A twig had fallen from the oak we were sitting under.
"Look at this," I said.
I bent the end of the twig and snapped a small piece.
I snapped another. Then another. And another.
"Your neighbor, the heel, he's younger than you right?"
"Sure is. Has no respect for his elders. None of the heels do."
I made the twigs like a line of ants.
I pointed at the twig in front.
"Think of this piece of twig as your neighbor.
And think of the twig behind him as his father.
We usually count someone's age as the time elapsed since they were born. That would just be the length of this one twig.
But imagine if we counted someone's age as the length of all these twigs that represent their lineage."
I grabbed a second twig and started laying out a second line.
"Why are you making another line?"
I finished placing the 12th piece of twig and took a slow, deep breath.

"This right here, this is you. And the next twig is your dad. And that one, your grandfather. And so on and so on.
Science tells us something amazing. When we measure people's age like this, our 'genetic' age, then all of us humans alive today, you, me, the heels, we are all exactly the same genetic age, down to the millisecond."
I gestured to her line of twigs.
"Now, think about all the births and deaths; the wars; the famines; the accidents; the unexplainable, heartbreaking, terrible tragedies.
The Devlins, you went through a lot, but you made it, right?"
"Sure did. Devlins are smart and tough."
"I believe you."
I took a deep breath and looked up at the oak.
"The Heels".
I pointed again to the first line.
"They made it too."

Blocking misleads
Blocking encourages the worst impulses of humans
August 28, 2024 — I have a backlog of interesting scientific work to do, but an important free speech matter has come to my attention. Warpcast is suddenly considering adding blocking.
I don't know whether some powerful people have joined and are pushing for this in secret, but I do know, as Farcaster user #158, that what has attracted a lot of active users to Farcaster has been our desire for a censorship resistant town square.
I hope in this short essay, we can show why Warpcast should veto adding blocking, now and forever in the future.
Blocking visualized.
We will use the illustration below to define our terms.
Black triangle represents a powerful user with a lot of followers (grey triangles). Black circle is a post by black user. Blue circle is a comment by blue follower. Black triangle blocks blue follower, preventing gray triangles from seeing response. By blocking blue, black user harms grey users by preventing them from seeing truthful enhancements to their posts.
Humans are born rate limited
A common argument made in favor of blocking is that black users must be protected from some firehose of responses coming from blue users.
But this is physically impossible. Blue users are just humans, who have to eat, sleep, take a piss, cook for their kids, and do a million other things.
They do not have time to dedicate their lives to "piling on" to black users.
It must be considered that the black user subconsciously knows they are doing something wrong, and so is experiencing extreme cognitive dissonance causing them to exaggerate the volume of messages from the blue user.
(Note that bots posing as humans should be blocked, but at the global protocol level and with efficient means to appeal to avoid the dangers of false positives.)
Naming Names
I am currently blocked by the below 4 popular users on Twitter:
| name | user | followersInMillions | earliestBooster | blockedAfter |
|---|---|---|---|---|
| Massimo | Rainmaker1973 | 2.2 | true | Asking for citations after reporting inaccurate information. |
| Nassim Taleb | nntaleb | 1 | true | Posting data that refuted a tweet. |
| Garry Tan | garrytan | 0.465 | true | Trying to share helpful feedback about the SVBank situation. |
| Suhail Doshi | suhail | 0.307 | true | I don't even remember. I helped him for free for many years. |
In all cases I was blocked after trying to help improve their ideas and better inform their users, who are all communities of people (science, statistics, startups) that I have a 20 year public track record of caring deeply about.
I also was an early public booster of all of these people, with years of public proof behind that, so one can not only show evidence that my actions were good, but that there is strong evidence of long term good intentions and good will from me to these people.
I couldn't care less about my own ego, and I find it humorous and harmless when people mute me-I can be annoying with all my intense data and mathematical thinking. Muting is fine!
But to block me is to commit active harm to your users. It is censorship. It is anti-free speech.
It should not only not be done, but it should not be a feature of these digital town square platforms.
It makes me sad that these people, who I respect and enjoy their work, would have their worst impulses encouraged by Twitter allowing the blocking of users.
I blame Twitter for encouraging their worst impulses. I hope Warpcast does not make the same mistake.
Thank you for listening. If you disagree, I am happy to look at your data and math in favor of adding blocking. And if I disagree, at the very worst, I will mute you.
Note
This took me one hour to create, and I livestreamed for full transparency because I believe free speech is such an important issue.

If someone tossed me a nickel for every rejection I've gotten I'd be dead, buried under nickels.
August 25, 2024 — Two weeks ago I applied for the South Park Commons Founder Fellowship.
I applied because I love being part of cohorts of builders building and because I repeatedly invest all my money into Scroll, my angel investments, and other people, and would love to have more money so I can build the World Wide Scroll faster.
I was sad by South Park's rejection yesterday but I'm excited to use this as a teachable moment for South Park Commons, because building new things is hard and making things better for the people who do is something I care deeply about.
Hi there,
Thank you for applying to the SPC Founder Fellowship.
Our team appreciates the time and thought that you put into completing the application.
What are some ways you might show you appreciate my time rather than tell me you do?
We carefully reviewed all of the materials that you submitted and are sorry to say that we will not be able to offer you a place in the upcoming cohort. Due to the large number of applicants, we unfortunately won’t be able to offer more individual feedback.
If you carefully reviewed my materials, that implies you made some notes, and wouldn't it take just as much time to send me those notes as to send this email?
While we know this is disappointing news, we hope that it is not discouraging to your founding endeavors. We have been wrong in the past about ideas and founders this early in the journey and have (unfortunately) passed on companies that have gone on to achieve great things.
Why not share your numbers of applicants, acceptance rates, and outliers you missed?
We hope you’ll stay in touch through our community newsletter and Twitter. We’ll share any updates regarding future cohort applications through those channels and would be happy to see you apply again in the future.
Will you consider going back through these rejections and doing some actions that show your apprecation?
Best,
South Park Commons
Have you considered signing with your human names?
August 21, 2024 — In 2019 I led some research into building next-gen medical records based on some breakthroughs in computer language design.
The underlying technology to bring this to market is finally maturing, and I expect we will see a system like PAU appear soon.
Medical records will never be the same.
Exciting times!

Our slides from 2019 as relevant as ever.
Related efforts
If you know of links that should be here, please let me know. Or better yet, send a pull request!
Naked bodies in Las Vegas
August 14, 2024 — I'm in Las Vegas for DEF CON and walking on the strip in 110 degree heat when a guy in dark clothes asks if I want to see some nude girls.
"Wait, how did you know I'm an amateur biologist?" I ask.
He frumps his brow and starts talking to a different group of guys.
But I need to find out what he was talking about.
I walk to my hotel room and google "las vegas nude people science museum".
Two hours later I'm leaving, awestruck, from Real Bodies Las Vegas.
Plastination
Wow! If you haven't been to a plastination exhibit yet, go now, and go often.
It's a mind expanding experience. It is somewhere between 1,000 and 1,000,000 times better than reading an anatomy textbook.
For the past year or so, I've been wanting to play a mental video in my head of the life cycle of ketones, but struggled with all the details.
Thanks to this exhibit, I was able to build a much better mental model, which I've tried to explain below.
I'm sure there are mistakes, please send pull requests or emails with corrections.
My mental model of the entire life cycle of ketones
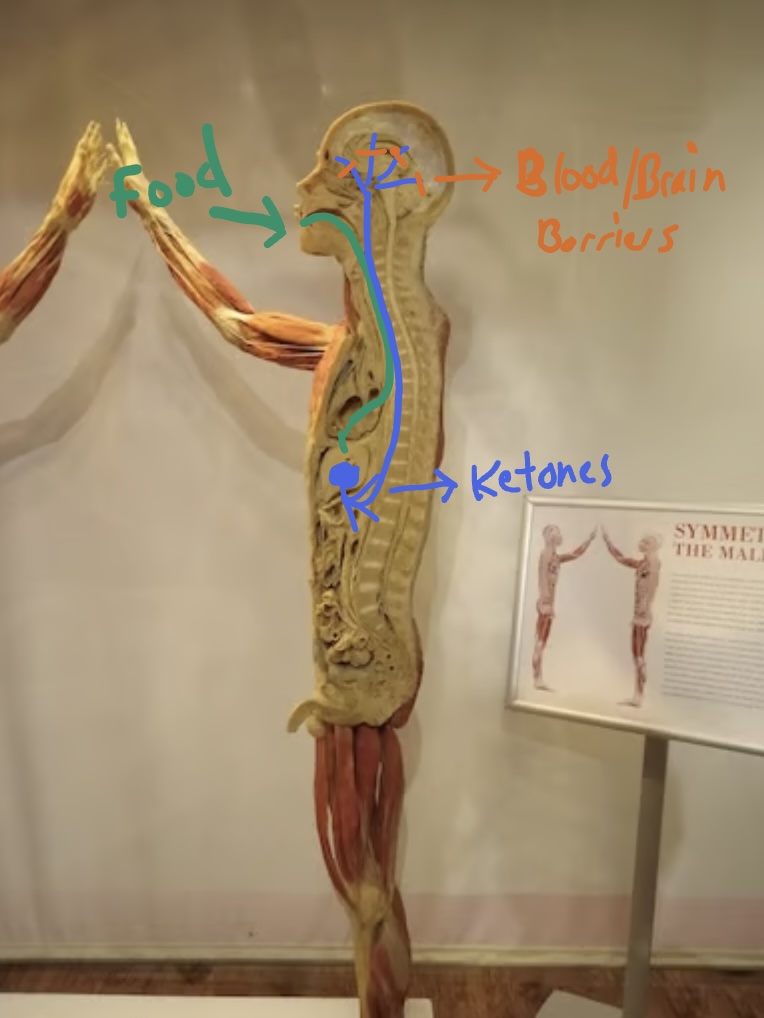
Food enters mouth then throat then down into the stomach where it starts to be broken down. Parts of it move to the liver, where ketones are metabolized. Some of those ketones travel in the blood through the carotid and vertebral arteries to the brain and across the blood brain barrier.
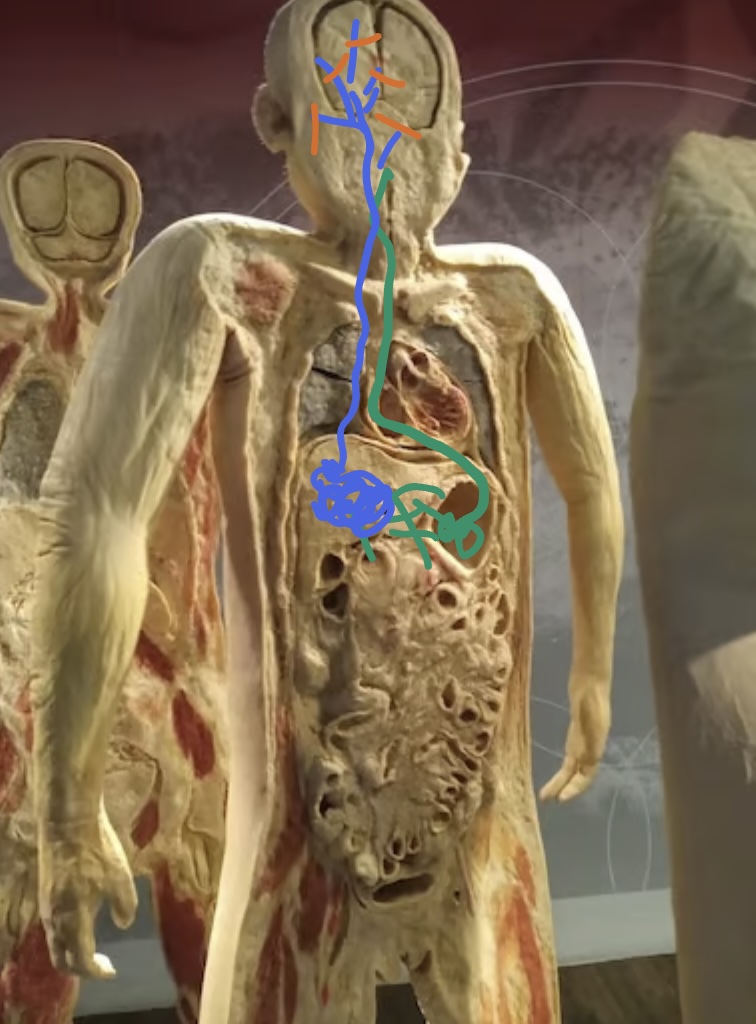
A different angle.
Ketones travel through arteries that run up along the spine/neck to the brain.
More images from Real Bodies relevant to Ketones
The liver is the largest organ inside your body.
Look at all those branches! Lots of places to make a lot of ketones.
The complete digestive system.

Ketones travel in your bloodstream through all of these tubes.
Conclusion
I still have a lot of deep unanswered questions about ketones at the micro level.
But now I have more confidence in my understanding of ketones at the macro level.
My journey to understand the human body continues! Thanks for coming along.
- A New Scientific Model of Mania and Depression, with Testable Predictions (2024)
- The Liver Turns On and Off (2024)
- Energy Clocks (2024)
- Ketones vs Lithium (2024)
Notes
- I snapped these photos on Sunday.
Update: I think this is one of my (hopefully few) posts that is wrong. It's probably always worth the time to "respectfully disagree" and avoid hyperbolic zingers. See updates later in the post.
Anyone not part asshole is full of shit
August 5, 2024 — Steve Jobs was famously part asshole but now the popular crowd says don't emulate that part.
Fuck them. This is the wrong take and there is no upside to staying wrong[1].
Yell at Dishonest Behavior
I wish we had infinite time so anytime someone was being dishonest or lazy I could analyze the situation from every angle, put myself in that person's shoes and model their life and everything they missed or suffered to lead them to their current mistake, and run through many iterations of speeches searching for the words that will effectively teach them with the softest touch the error of their ways.
Unfortunately, as far I as I understand, not a single day is ever guaranteed and so to save my time for happier positive things I have to quickly look them straight in the eye and say "What you are doing is dishonest, knock it the fuck off, or I'll take action," and move on with my life.
Part Assholes have steered me true
I remember clearly many times when both people I love and complete strangers gave me honest advice straight from their assholes[2]:
"Isn't this a tad bit...dishonest?" someone reprimanded me when I was a kid and thought I was a genius for putting ads on my site but hiding them with CSS so I could still earn money without actually showing ads.
"Breck, what are you doing?" a best friend in college once snapped me out of a drunken stupor and pulled me away from some new girl when I had a girlfriend back home.
"Learn to research properly" an Internet stranger told me thereby encouraging me not only to learn the ways of academia, but then go far beyond that and truly learn the way research should be done.
I don't mind honest feedback delivered harshly. Obviously I prefer honest feedback delivered gently, but harsh feedback and dialogue is better than silence. There's a saying about feedback: “Those who mind don’t matter, and those who matter don’t mind!” I want to matter, so please keep the feedback coming!
People not part asshole in public are even worse: huge assholes in private
I have learned not to trust people unwilling to be a part asshole (only when it is appropriate of course) in public. These are the people who are real dirty assholes in private, who will collude and plot and gossip in private and then in public act like angels.
What specifically is the "asshole" behavior I'm advocating?
Direct, blunt feedback to someone about specific bad behavior, that may come across as hyperbolic, is awesome. Again, if you can pivot their behavior in a gentle way, prefer that always. But the most unkind thing you can do to them and to our world is to let bad behavior go unchecked in order to "not be an asshole".
No one likes to be the asshole. I hate it. It sucks. But an ounce of prevention is worth a pound of cure, and if you don't nip bad behavior in the bud, it grows.
I do not advocate flipping the bit on people. I believe all people are mostly good, and all can learn to improve their behavior, but they require honest feedback to do that. It's also important to remember due to natural information asymmetry, we are naturally biased to judge ourselves by our intentions but others by their actions. Often I give someone blunt feedback and they respond bluntly back correcting me because I was wrong! This is a great outcome that we would not have reached had I flipped the bit on them and not risked being an asshole.
What am I trying to optimize for?
We want to minimize bad behavior B while also minimizing time spent correcting bad behavior C. If that requires delivering a blunt hyperbolic zinger that risks getting you tagged with the label "asshole", I say go for it.
How short should your "fuse" be?
My strategy is to be polite 2 or 3 times, and then let the person have it. I'm sure there's improvements to this strategy, would love to hear what other people do.
Summary
Perhaps the worst thing about Steve Jobs is that he wasn't asshole enough in public[3]. Maybe if he showed the same range in public as he did in private, people would have understood more the value of being part asshole.
- 100% Assholes: Avoid! They are so negative and bothered by everything because everything sticks up their ass.
- 0% Assholes: Avoid! They are full of shit! Or more likely, huge assholes behind closed doors.
- Part Assholes: seek them out!
Update: The question trick
August 5, 2024 — I'm now trying the question trick to see if it does a better job at \min_{B, C}.
Instead of declaratives ask questions.
ADD: Ask, Don't Declare.
You are being dishonest. Do you think this is a tad bit dishonest?
You're lazy. Might this be lazy?
This is terrible. Can you do better?
Dataset needed. What dataset would confirm this?
Update: I respectfully disagree
June 10, 2025 — The question trick has backfired a couple times. I see now that though it drops the anger, it adds condescension.
Now I'm trying the "I respectfully disagree. ___. But I could be wrong." sandwich. It states your confidence, but states your respect for the other person, makes them more likely to consider your perspective, and states your honest openness to being wrong and changing your own position.
Notes
[1] The original quote by Ed Catmull. I added the "staying", because I think there is huge upside in being wrong a lot, as long as you pivot quick. There is no upside in staying wrong.
[2] I removed all angry profanity from their quotes above. I forgive the delivery and am grateful for their feedback.
[3] I never met SJ nor his family. This is about the SJ as portrayed in the media, and not the actual person, who I am unfamiliar with. I am familiar with the amazing things that he built, and some of the amazing things his wife has done, but sadly never got the chance to meet him.

David and Sandy
July 25, 2024 — I received sad news today that David Bangert passed away. I met David and Sandy in 2019 through Hawai'i Angels, when he and I were "Deal Honchos" on a deal. They took me out for lunch in Oahu, and I sat enthralled for hours listening to David's amazing life stories.
One day with David could change your life. It certainly changed mine.
His last letter is below.
Friends, Classmates, Neighbors, Colleagues!
I want to share with you a decision that I have made. This note is longer than I initially intended, but I feel I need to tell those with whom I've had friendships during my life’s journey, why I am about to take a dramatic step.
As you read this letter, Sandy and I are traveling to Zurich, Switzerland. Once in Switzerland, we are going to access the services of Dignitas (www.dignitas.ch) where I will be permitted to die with dignity. My health and mobility continue to decline. I do not want to end up lying in bed all day, and I am not enjoying living the life of a non-ambulatory person.
First and foremost, I am balanced challenged. I am now confined 99% of the time to sitting in a wheelchair or in bed because I cannot navigate my way across a room without falling. I constantly fear a fall and potentially breaking my 80-year-old bones. I used to resort to grasping for the surrounding furniture and walls as I inched along at a slower than snail pace, but now, my body will not allow me to do that. Also, a walker is no longer an option due to the loss of feeling in my feet, my degenerative bone condition, my flat feet, and my contorted foot configuration. This is a genetically predisposed condition inherited from my mother, which is progressively worsening, and I believe, the major contributing factor to my balance issue.
Historically, my orthopedic surgeries have been unsuccessful. My surgeries started in my military training when I had my left shoulder injured. The surgery left me unable to raise my left arm higher than my shoulder. Later at West Point, my ankle was operated on because of my Achilles tendon popping out of its groove. This resulted in a frozen ankle that will not bend properly. Some years later, a right knee replacement was needed. The specialists stated it was necessitated by my poorly functioning ankle. Since this surgery, I have been unable to bend my knee properly when I walk. Finally, I had back surgery. This last surgery resulted in not being able to walk or stand. I cannot make my feet and legs move on command.
Desiring a better life, I sought out multiple “second” opinions. My medical records were assessed at two excellent California university hospitals: Stanford, and UCSF. These two second opinions suggested additional testing, which my medical provider Kaiser performed. The new tests did not suggest the cause of my balance challenges, nor did they indicate any new successful therapies. Desperate for help, I turned to the best clinic in the US. Sandy and I traveled across the US to the Mayo clinic. For seven days, tests and assessments were performed. The recommendation was back surgery. I stayed in the clinic and had an operation by the Mayo clinic’s back specialist. Unfortunately, the surgery was a failure and resulted in a worsening of my condition; My balance was worse after I recovered from the operation. At least prior to the operation at the clinic, I could stand and walk short distances, but following the surgery, I became restricted to wheelchair use. I now resort to sliding along the wall and hanging on furniture when a transfer is necessitated: move from chair to bed, or chair to car. I have spoken to the Mayo clinic. It suggested going back there again and repeating the same tests. I decided against that course of action.
When I wake up in the morning, it takes me five minutes to transfer from the bed to my motorized wheelchair. Then, I continue to the bathroom to relieve myself, which involves a transfer from the wheelchair to the toilet. This transfer of position takes another few minutes. I have a toilet with a washer, which I use to clean myself. Following the toilet routine, I wheel into the kitchen and make myself a cup of coffee using the electric, one-cup Nespresso machine. It is a struggle for me to stand and make the cup of coffee. Sandy must ensure the water reservoir is full before bed so that I can independently have coffee in the morning. Then, I read my emails and the on-line newspaper on my iPad. Reading a printed newspaper is not possible because of my manual dexterity. I spend my entire day in my motorized wheelchair. This has been my daily routine for the past two years.
Four or five days a week, I have physical therapy. I use two trainers, both of which come to my home. My routine is similar with each trainer. They work with me for two hours. We do strengthen exercises, and they help me shower. I cannot go into the shower without assistance. My caregiver/trainer washes and dries me. I have a shower stool which I sit on. My strength is not improving, if anything, it is declining. I can see this in the weights that I'm able to lift and the duration of my cycles on the stationary bicycle.
Besides reading the newspaper and watching television, my day is very quiet. This is not the life that I am used to. I am used to having more stimulation and being involved in challenging situations. I have the good fortune of being a graduate from two world renowned institutions of higher learning: the Military Academy at West Point and Harvard Business School, (PhD in decision sciences). I am not used to not being able to physically do things. After military academy, I successfully completed Ranger and airborne school. In my forties, I walked around the Annapurna Massive in Nepal, 22 days of walking and staying in tents. In the past, my life has always been an active one.
Also, I am not as mentally sharp as I used to be. I often cannot remember the names of people and street names, places I have been, what I just ate, who I was with, investments I made yesterday... I have always been organized up till late, and now, I find myself (with Sandy helping me) looking for my lost wallet or keys for hours. For example, I suddenly forgot how to use the remote for the TV after using it for months successfully. I am transferring the responsibility for managing our wealth to Sandy. We spend time every day discussing our investments and decisions she will have to make. Tasks such as writing this letter are challenging. My typing is reduced to dictation plus two-finger typing. Sandy is helping me with this task.
In my late 30s and early 40s, I managed the first phase of the construction of a city in Saudi Arabia. I had a direct staff of 150 professionals who, through contracts, managed a workforce of 20,000 workers. Following the seven years in Saudi Arabia, I went to Hawaii in search of what I wanted to do for the rest of my life. I enrolled in the MBA program and about halfway through decided that being a professor would suit me. I came to understand that the culture of universities requires getting a quality doctorate. I was fortunate to be accepted at the four programs for which I applied: Harvard Business School, Stanford, Pittsburgh, and New York University. I went to Harvard and completed the doctoral program in 2 1/2 years, which is considered fast. The typical time to get a doctorate from Harvard is 4 1/2 years.
In the past, I have written hundreds of letters with ease. Now writing a letter, even one as important as this letter, is a struggle. It should not be a struggle. I am tired of struggling.
I am fortunate to have a supportive wife who understands my frustration. We are affectionate, kiss multiple times a day and hold hands. Although we go to dinners, theater and other functions, the struggle to get to the venue exhausts me. I often think it is not worth the effort.
I will be cremated in Zurich and the ashes will be mailed to Honolulu. From Switzerland, Sandy plans to go to her hometown of Kelowna, British Columbia for a short time. There, she will be with her family.
Afterwards, she will return to Honolulu. She plans to bring the ashes to West Point in 2025 at my Class’s reunion for placement in the West Point cemetery.
Thank you for being good friends. I enjoyed our time. Please continue to interact regularly with Sandy. I know she greatly values your time together.
David
RIP David.
Abraham Lincoln: "Discourage Litigation."
July 23, 2024 — Stephan Kinsella reposted a great 1850's quote from Abraham Lincoln on litigation.
Discourage litigation. Persuade your neighbors to compromise whenever you can. Point out to them how the nominal winner is often a real loser---in fees, expenses, and waste of time. As a peacemaker the lawyer has a superior opportunity of being a good man. There will still be business enough. Never stir up litigation. A worse man can scarcely be found than one who does this. - Abraham Lincoln (1850)
Matthew Pinsker at Dickinson posted an image of the original:

Are some intellectual environments better than others? Yes.
ETA! states that E, the evolution time of ideas, is the time T needed to test alterations of ideas, divided by the factorial of the number of ideas in the Assembly Pool A!.
Longer evolution times means worse ideas last longer before evolving into better ideas.
You can lengthen the lifespan of bad ideas by increasing the time to test alterations or reducing the size of the Assembly Pool.
You can evolve good ideas faster by decreasing the time to test alterations and increasing the size of the Assembly Pool.
The number of test threads is proportional to the size of the Assembly Pool.
This equation explains the triumph of open source and public domain software.
Notes
- An implication of this equation: copyrights, patents, licenses and NDAs retard evolution. Thus, people that use these things are accurately called retarded. They evolve slower and will go extinct.
- After feedback from Szymon Łukaszyk it became clear to me the more precise formula is:
Luckily A^A is still in the factorial class so the memorable acronym still applies.
- Thank you to Lee Cronin and Sara Walker for evolving the idea of the Assembly Pool.
- Thank you to Szymon Łukaszyk who's applications of Assembly Theory to binary messages encouraged me to apply Assembly Theory to measure the health of information environments.
- Thank you to Connor McCormick for superb feedback.
- Thank you to Cobe Liu for pointing out it should be T/A!.
- Thank you to my coauthor John. Without your help I never would have arrived at this equation.
A New Business Model for Public Domain Software
July 13, 2024 — I am writing a book in a private git repo that you can buy lifetime access to for $50.
That repo is where the source code for the book lives before it gets published to the public domain.
The public gets a new carefully crafted book with source code, just delayed. If you pay, you get early access.
This business model I'm calling "Early Source".
Early Source
Early Source is a new business model for public domain, open source software. You publish your software to the public domain, but with a delay of N years. Professionals that most benefit from faster updates pay you for access to the private, cutting edge version.
Early Source is a win-win-win-win:
- It's a win for your most loyal customers who can pay you a simple fee for a simple deal and get early features fast
- It's a win for your business model as you can benefit from the lower costs of open source while still keeping something scarce to sell
- It's a win for casual users around the world who now can benefit from your older software and will know who to buy from if they later become professionals
- It's a win for your ideas because you can now make them as good as possible, something you can only do if they are public domain
What are the downsides? Let me hear it in the comments.
Update 11/4/2024
So far, I would have to say early source is a pain in the ass.
Keeping 2 repos going, one private and one public, is just a lot of cognitive overhead. Far more than I thought.
Instead of trying to connect revenue to digital access, I think I'll publish the ebook free, and sell a paper version, as well as additional stuff around this, like a course with real human interaction.
Silicon Valley Should Eliminate the 1 Year Cliff
July 4, 2024 — I lived in San Francisco and Seattle in the 2000's and 2010's, and if I told you the names of every startup I almost joined as employee <5, you'd probably think I was lying.
But I declined them all for the same reason: the 1 year vesting cliff.
What's a cliff?
If a startup gives you 1% of the company in the form of stock options, the standard is to vest 0.25% a year for 4 years with a 1 year cliff. This means you get nothing until after the first year.
If you have to leave or they fire you after 11 months you own zero.
Cliffs are a bad deal for everyone and should be eliminated.
It sucks for the employees. It's so much more fun to do your best work immediately and never think about cliffs.
It sucks for the startups. They miss out on bringing in outlier talent who may stay for a decade, but only want to guarantee a few months.
Back in 2008-2018, I was young and 1 year seemed like an eternity-what if I wanted to travel in 10 months, or someone close to me got sick, or I had my own startup idea?
I also didn't want to have any incentive to sit on my best work until my shares started vesting. I wanted to give my teams my absolute best from day 1.
Historically I knew I would make the most impact at a startup in months 3 - 12, so why should I be rewarded less than the person who does just enough to last until month 12?
Now that I'm an angel investor and not subject to cliffs, I can say with much higher certainty: cliffs are dumb and should be eliminated.
Four year vesting schedules are fine, but employees should vest daily, starting on day 1.
But what if we hire someone and they don't last even 1 month?
This should be very rare, but even if it happen, it's not a big deal.
They get 2% of their stock options. Far less than a single percent of your company. So what.
Everyone should be happier without the cliff.
Presumably you've hired people who are good people, and so even though it wasn't a right fit, you think the world will be a better place if that person someday gets a little extra money from their stock.
They also will forever be a booster of your business even though they are no longer an employee, because they now have the incentives to be.
But what about all the paperwork, accounting, and legal trouble of daily vesting?
It is basic arithmetic. The software to implement this is dead simple. And I've now seen it done with one of the startups I invested in (and it works great).
That's all I have to say about cliffs. Now, I've got to get back to building my own projects.
But if your startups wants to hire me and pay me in options, I am available. (For a month or two ;) )

June 29, 2024 — A child draws.
You take his paper.
He screams.
His scream is just: you stole his property.
You give the paper back.
He stops screaming.
You copy his drawing on your own paper.
He smiles.
His smile is just: he feels his work is appreciated, and he can learn from your version.
Ideas and property could not be more different.
Ideas cannot be stolen. Property can be.
Copying ideas helps, not hurts.
Children understand these obvious truths.
Children learn what is true from nature.
But teenagers turn from nature and start learning "truth" from the popular kids.
This allows for some strange diseases to spread across our civilization.
Intellectual Property Delusion Disease
Intellectual Property Delusion Disease(IPDD) is a neurological disease most contagious in the United States, but afflicting countless people throughout the world.
The brain of someone infected with IPDD cannot deduce the obvious truth that copyrights and patents are the exact opposite of property rights.
They cannot see that atoms are scarce and improved by assignment and ideas are the opposite.
Symptoms
Symptoms of IPDD include:
- the appearance of tiny round spots, often found on the foot, that look like this: ©
- compulsive tendencies, such as insisting that a "license" accompany every piece of information.
- trouble pronouncing phrases, saying "All Rights Reserved" when they mean "Your Rights Restricted."
- paranoia that someone will "steal their ideas" accompanied by outbursts of "Patent Pending" or "FBI Warning" at their customers
People with IPDD also suffer from deep, grandiose delusions like that they created:
- a widget more important than the wheel
- a song better than all of Beethoven's
- a formula more intelligent than all of Einstein's
Prognosis
IPDD is deadly to individuals. IPDD often leads to the long term intellectual malnourishment of a person causing them to may make fatal health decisions.
At a societal level, IPDD is a significant long term burden on economies. Holding all else equal, countries with low rates rates of IPDD infection have significantly faster innovation and more equal wealth distribution.
Treatment
Luckily people can be cured of IPDD, no matter how old they are or advanced their infection.
The best medicine for curing IPDD is exposure to honest information and a long walk in the woods.
It is important to be careful when attempting to heal someone with IPDD too quickly.
I once told an infected Congressman that since they made everything someone writes "protected", they should also "protect" the air someone exhales.
I was hoping this perspective might cure him of his affliction.
Instead, his face lit up, he pulled out his phone and told me he had to text his "Intellectual Property" Liar to try and patent his new idea for a machine that could add licenses to air molecules.
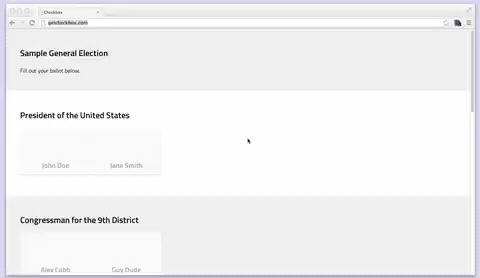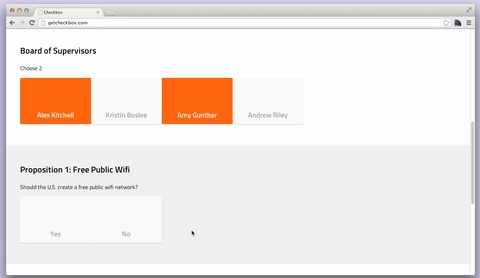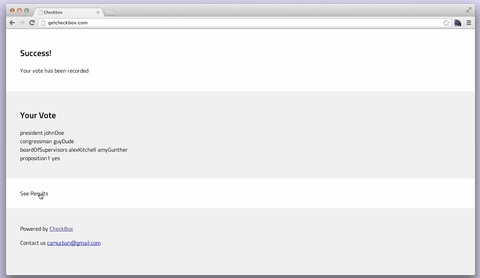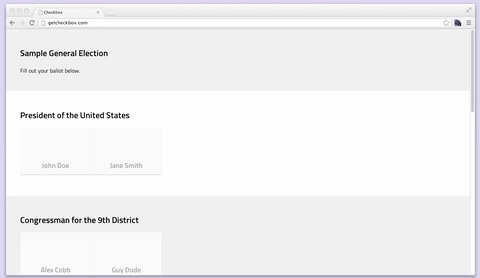
Our beta from 2013.
June 25, 2024 — In 2013 my friends and I won the Liberty Hackathon in San Francisco.
We built CheckBox, an open source system voting system that supported online, offline and hybrid elections. I did the technical design, Cam talked to users and developed the business pitch, and Ben provided the design.
CheckBox built on our new discovery at the time, which now goes by the name Particles.
We tried (and failed) to raise money to work on CheckBox full-time.
We were quite poor at the time.
I subsisted on an unhealthy diet of ramen and an occasional treat from the McDonalds $1 menu.
I often slept on a couch while hosting an AirBedAndBreakfast guest in my bed.
I also had a roommate and we had one bed and one couch in the room, and when our room wasn't rented we alternated who got the bed.
About six months after this hackathon, Microsoft acqui-hired our team for NudgePad, the other project we were working on.
This was great because I could now afford anything on the McDonalds menu.
Unfortunately CheckBox fell by the wayside, until someone reminded me of it today.
Below is our executive summary from our failed fundraising attempt in 2013.
(I am still trying to find the code that powered our beta).
Although CheckBox as a business is not for me, I love the underlying CheckBox design, and still think that this system has a better underlying design than any other electronic voting system-by a wide margin.
The key idea is this: the underlying languages can power 100% digital election, 100% paper election, or a hybrid election.
If you want to build the best voting system, I am highly confident this is the way.
CheckBox Executive Summary
Overview
It’s 2013. Everyday we trust the Internet to process billions of dollars, keep our social security numbers secure, as well as our medical information. Yet still, to cast a vote we need to drive to a polling station, wait in line, and fill in bubbles with a pencil.
We’re changing that.
We built CheckBox so that voting districts can easily create a secure ballot for voters to vote from home.
Problem
Online voting is a technical problem, not a political problem. No existing technology is able to provide a secure, user-friendly online voting experience.
Solution
We invented the Space language (2024 note: this is now called Particles), which is the key technical innovation behind CheckBox. Space is the only language that is simple and powerful enough for online voting.
It offers:
- Secure Voting
- Private Ballots
- Supports Electronic/Paper Hybrid Systems
- Easy Customization
- Supports Early or Absentee Voting
- Election Auditing
- Security Middleware
- Registration and Ballot Distribution Middleware
- Voter Registration
- Open Source
Prototype is live at http://getcheckbox.com
How it Works
- Voters are provided a unique, random ID that qualifies them to vote, and a web address to access the ballot.
- Voter cast their ballot with their random ID.
- Raw results are published online after the election closes to verify legitimacy of election
Distribution
- Reporters love writing about CheckBox. Our technology allows for new stories like analysis of actual raw ballot results.
- Open source allows for easy “try before you buy” compared to other competing solutions
- Begin with private sector then sell to voting districts
Traction
We started working on CheckBox on June 21st. On June 22nd won the Liberty Hackathon Grand Prize ($3,000). On June 24th featured on NPR. Upcoming articles in Salon, BuzzFeed and Politico.
Business Model
Free to self host and 10 cents per ballot for fully managed and hosted operation.
Government Market
- 10,000+ election districts in U.S. ranging from 200 to millions of voters
- $10 average cost per voter served. We’re going to charge $.10 per voter served
- $700M TAM in the U.S.
- Only 55% of eligible voters vote in the U.S. vote in a good year
- 32 U.S. states have applied for federal grant money to create online voting software
Private Market
Shareholder elections, corporate election, group elections, student elections
Corporation
We plan to incorporate as a for-benefit corporation in the State of California with a dual mission to maximize voter turnout and profit. Equity will be split as follows: Founders 60%, investors 20%, employees 20%. The company will be based in San Francisco and work from the Nudge Inc. office.
Milestones
- 10,000 non-governmental elections conducted between now and November
- 10 municipalities deploy and use CheckBox in November 2013
Deal
We’re looking to raise up to $200,000 via convertible notes with an $800,000 cap to achieve our 2013 milestones.

June 12, 2024 — After years of development, I'm looking for beta testers for The World Wide Scroll (WWS).
The WWS is like the World Wide Web, except:
- Intelligent. Built not on HTML, but from the ground up in a simple, expandable language, designed for both humans and AIs.
- Offline. You download entire sites and browse completely offline locally, rather than fetching one page at a time.
- Pristine. No ads, no paywalls, no trackers, no cookies, no copyright.
- Human. Instead of anonymous domains registered to corporations the WWS has folders owned by verified humans.
- Trustworthy. Source code behind every page.
If you know someone who might find this interesting, I'd appreciate it if you could share this with them.
The link to register a folder is:
The price to own a folder is $100 for 10 years.
Funds pay for the development of the Scroll language.
Mahalo!
-Breck
Websites don't need web servers.
June 11, 2024 — You can now download this entire blog as a zip file for offline use.
The zip file includes the Scroll source code for every post; the generated HTML; all images; CSS; Javascript; even clientside search.
Instructions
- Download
- Unzip
- Open
index.html
Technical users can still clone and build the repo, but sometimes you just want the compiled HTML for offline reading.
Wouldn't it be great if more of The Web were like this?
The Scroll is coming ;)
Can we quantify intelligence? Yes.
Program P is a bit vector that can make a bit vector (Predictions) that attempts to predict a bit vector of actual measurements (Nature).
Coverage(P) is the sum of the XNOR of the Predictions vector with the Nature vector.
Intelligence(P) is equal to Coverage(P) divided by Size(P).
If programs A and B are the same size, the program with more coverage is more intelligent.
If they have the same coverage, the smaller program is more intelligent.
Related Posts
- Particle Chain: A New Kind of Blockchain (2024)
- ETA!: A Measure of Evolution (2024)
- PTCRI: An Equation about Syntax Potential (2024)
- ScrollSets: A New Way to Store Knowledge (2024)
- PC: Particle Complexity (2017)
- Parsers: a language for making languages (2017)
- Tree Notation: an antifragile program notation (2017)
- A New Discovery in Computer Science: 2-Dimensional Programming Languages (2017)
Notes
- ICS is a way to measure what Wikipedians call Explanatory Power.
- Karl Pearson said the same thing:
The object of science is to describe in the fewest words the widest range of phenomena.Karl Pearson, The Grammar of Science, pg 339 (1892)
by Breck Yunits
May 31, 2024 — Yesterday, on a plane, I found an equation I sought for a decade.
PTCRI describes the potential of a programming syntax.
PTCRI says the number of possible programs P is equal to the number of tokens T raised by the number of columns C, raised by the number of rows R (aka lines), raised by the number of indentation levels I.
If you view the source code of this post, you will see T, C, R, and I in action.
PTCRI explains the simplicity and power of Particles[1]. Four concepts, three syntax rules support a vast universe of concise programs. Another syntax(es) might be found with superior metrics, but I have yet to see it.
PTCRI also explains why nearly flat structures work so well: a little nesting goes a long way. If you set T and C and R to 3, changing I from 1 to 2 increases the amount of possible programs from 7,625,597,484,987 to 58,149,737,003,040,060,000,000,000.
59 days ago I announced the decade long Particles research endeavor over with a negative result.
It looks like I was wrong again. There was something special about Particles, and PTCRI explains what that is.
It shouldn't be possible to represent all programs in all programming language with such a minimal set of rules! Particles doesn't even have parentheses!
And yet, the experimental evidence kept piling up.
The evidence hinted at some important natural formula, and now we have a name for it: PTCRI.
Notes
[1] Particles was originally named Tree Notation.
Thank you to Marc Forward and Inconstant_Moo for feedback and helping me add the T.
It may help to explain from another angle. Imagine your boss comes up to you and says "We are giving you a special assignment. We want you to come up with the best possible syntax for all programming languages." What do you come up with?
You can present them with Particles, and explain how it supports a vast universe of programs, P = {T^{C^R}}^I, with just three syntax rules:
- lines split into columns via bits, characters or words
- groups of lines joined to each other via newlines
- scopes established via the indent trick (aka the "Offiside Rule", popularized by Python, HAML, et cetera)
- Does PTCRI also describe S-Expressions? S-Expression work. Particles barely works.
- All mistakes are on me, and credit goes to the people who have supported this effort with me.
- I think this equation is pretty interesting, so I really hope a lot of people on the Internet tell me how stupid it is and that it was discovered 100 years ago.
- Now, back to my vacation.
Related Posts
- Particle Chain: A New Kind of Blockchain (2024)
- ETA!: A Measure of Evolution (2024)
- ICS: A Measure of Intelligence (2024)
- ScrollSets: A New Way to Store Knowledge (2024)
- PC: Particle Complexity (2017)
- Parsers: a language for making languages (2017)
- Tree Notation: an antifragile program notation (2017)
- A New Discovery in Computer Science: 2-Dimensional Programming Languages (2017)
Patch is a tiny Javascript class (1k compressed) with zero dependencies that makes pretty deep links easy.
Patch can be used with both:
- ?queryStrings
- #hashStrings
Patch handles encoding and decoding for you, and makes your deep links pretty, so you don't have to think about it.
Example
This object:
{
"countries": [
"Canada",
"France"
],
"selection": "France"
}
Becomes countries=Canada=France&selection=France (and vice versa).
How to use
- Include patch.js or just copy/paste the code:
<script src="patch.js"></script>
- Give your Javascript object to Patch, and it will give you the prettiest query string it can make:
window.location.hash = new Patch(
{
"countries": [
"Canada",
"France"
],
"selection": "France"
}
).uriEncodedString
- Give Patch a query string, and it will give you back your Javascript object:
console.log(new Patch(window.location.hash).object)
Specification
They key idea of Patch is to think of your query params as a spreadsheet.
Then Patch encodes and decodes that spreadsheet.
A Patch object has 4 forms:
1. Spreadsheet Form
countries Canada France
selection France
2. URI form
countries=Canada=France&selection=France
3. Object Form
{
"countries": ["Canada", "France"],
"selection": ["France"],
}
4. Matrix Form
[
["countries", "Canada", "France"],
["selection", "France"],
]
Delimiters
Patch requires 2 delimiters, one for separating "rows" and one for separating "columns".
The default is & for rows and = for columns.
You can change these to suit your own needs.
Spaces
Patch encodes spaces to + instead of %20 and uses the standard encoding of + to %2B.
URI Encoding
String inputs to the Patch constructor are assumed to be encoded and will be decoded before parsing. Similarly the string output is always encoded.
Scalar Types
Patch treats all scalars as strings. Do a just-in-time parse of numbers, booleans, or JSON values if needed.
Why Patch?
QueryStrings can be thought of as a domain specific language for describing this structure:
type QueryStrings = Omit<string, [RestrictedCharacters]>
Map<QueryStrings, QueryStrings>
- QueryStrings has one very restricted string type and a simple map type.
- QueryStrings arguably adds little to no value on top of just a single string.
- QueryStrings requires you encode and decode each map pair separately.
- JSON is an alternative to Patch, except after uriEncoding JSON you lose almost all human editability in query strings.
Some benefits of Patch
- Encode and decode your params just once.
- Cleanly encodes arrays and nested structures.
- Very easy to debug—it's just a patch!
History
I made Patch in 2020 for Our World in Data.
This is an updated fork.
"I'll give you this library," the billionaire said, sweeping his arms up toward the majestic ceiling.
"Or...you can have this scroll," he said, pointing down at a stick of paper on a table, tied with a red ribbon.
Thomas said nothing.
He kept his eyes locked on the billionaire's.
He had prepared for moments like this.
Don't flinch.
Don't look away.
Be comfortable with silence.
Think.
He knew he was going to be challenged with something today.
He just didn't know what.
Now he knew.
I have to get this right.
Obviously choose the library, right?
The real estate and art in this place are worth billions!
It's the biggest personal library in the world!
It has every book ever published.
Every paper ever written.
Every song ever recorded.
Every movie ever filmed.
Shannon would take the library, right?
Think of all that information!
The collective work of a hundred billion humans over ten thousand years.
Ten trillion human-years of effort!
With that much information, I could solve the complexity of the universe!
The complexity of the universe.
Hmmm.
What did Wolfram discover about complexity?
Infinite complexity can arise from simple rules.
Simple rules.
Simple rules.
Simple rules...that could fit on a piece of paper.
Holy sh**.
Did he discover simple rules to our universe?
Did he invent a language that solves both quantum mechanics and gravity?
That has to be it.
But EVERYONE would choose the library.
Thomas inhaled deeply.
"I'll take the scroll"
Thomas sat in his car in a beach parking lot and stared across the bay to the end of the cape.
First he saw the smoke, then the flames, and then the humongous rocket rise off the ground.
It gained speed as it rose into the sky, carrying his mentor and the rest of its crew on their journey to Mars.
When the rocket was out of sight, Thomas looked down at his lap.
He untied the red ribbon and unrolled the scroll.
It was blank.
See where technology is going before your competitors

Above is a (blurred) screenshot of brecks.lab. For $499,999 a year, you get access to the private Git repo and issue boards.
Introducing Breck's Lab
For $499,999 a year, you get access to brecks.lab, the private git repository and issue board where we post our in-progress language and AI research, and prioritize and shape the future of Scroll, PLDB, and our other open source projects.
- Early Access: See new research and code early, sometimes months before publication.
- Influence: Vote on which ideas you think deserve the most focus.
- Meet: Interact with other members on the issues board.
If you are a technology investor, we have some very exciting posts coming out on AI, science, and what comes after the web.
You can wait for the published versions, or you can join brecks.lab today.
Why sell lab access?
How are independent scientists to earn a living in a world without copyright and patents?
By selling early lab access to corporations and money managers.
Independent scientists can do better science if
- They can publish everything to the public domain
- They have an empowered group of beta readers with shared interests
- They have less need to worry about revenue streams
Why not solve all three problems at once?
Labs is designed to help fix science. The public gets far better information and investors get information on what new technologies are coming next.
The Fine Print
- Access: A purchase entitles you to one year of access to the brecks.lab git repo and issues board, for one email address and one person.
- Public Domain: Everything in brecks.lab eventually evolves into a public domain publication on Scroll, PLDB, breckyunits.com or one of our other public domain sites, with the exception of some ideas that are cut.
- Honorary Members: If you've contributed 31 or more commits to our open source projects, email me for your honorary membership.
- Satisfaction Guarantee: If you are not 100% satisfied at any point, just email me why and I'll issue a refund for the unused months.
- Usage: If you use code or ideas from brecks.lab in your own work before they are published, just please be polite about it.
- Payment Methods: You can also join by sending $499,999 to breck7.near, via PayPal (breck7@gmail.com), Cash App ($byunits), Venmo (@Breck-Yunits), or handing me $499,999 cash.
May 26, 2024 — You once could buy transistors, capacitors, and other components at your local neighborhood store. The decline in US computer and electronics manufacturing correlates with the decline in RadioShacks. To catch up to other nations, maybe it is time for a next-gen RadioShack.
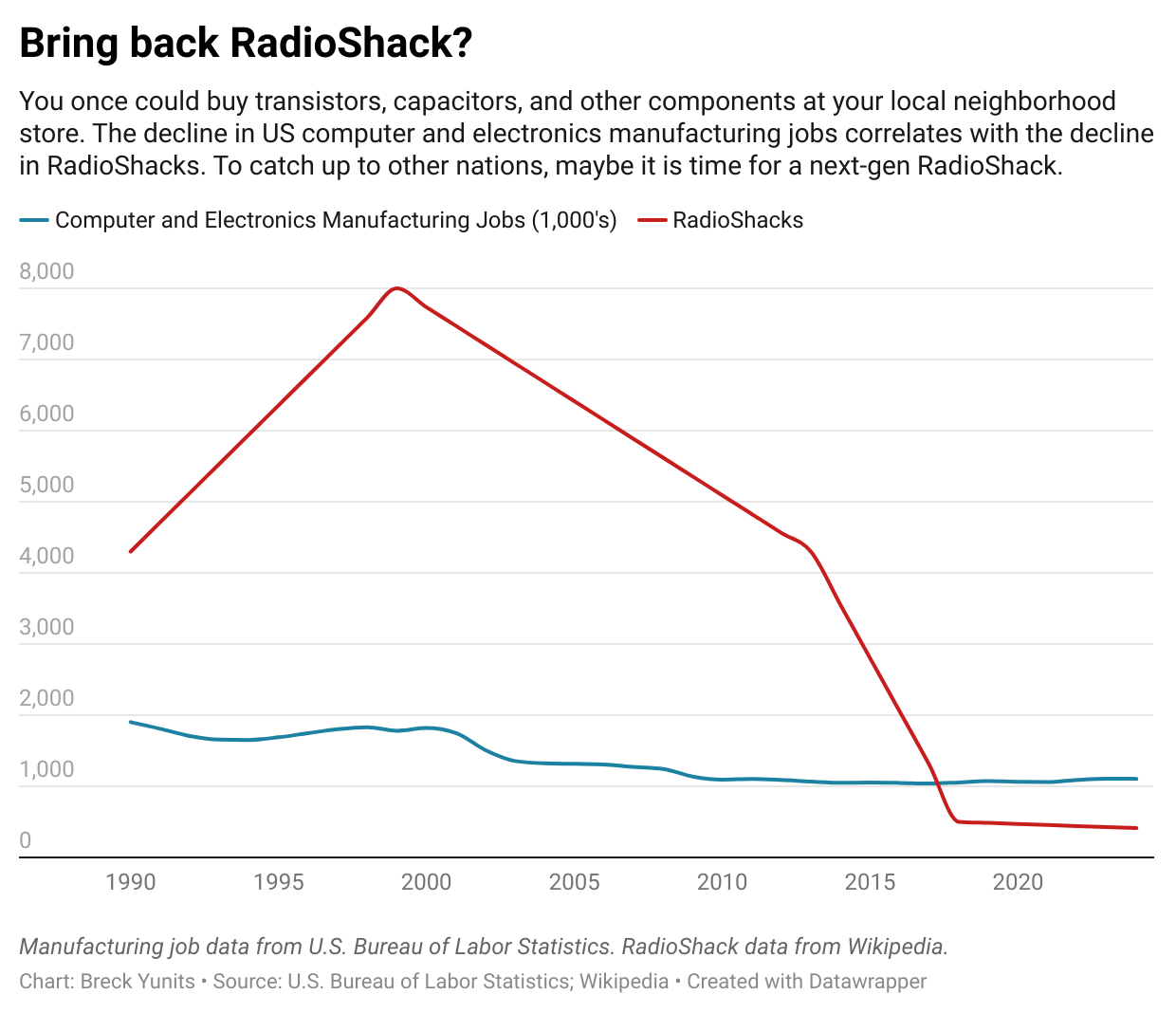
Notes
- All of the data is in the source code for this blog post. Click "View Source" at the bottom of this page to see it.
- There are still 412 independently owned RadioShacks
- I found data for number of RadioShack stores for 6 years, and used Our World In Data's Grapher to interpolate the missing values.
- For ElectronicsManufacturing, I used the data from All Employees, Computer and Electronic Product Manufacturing, averaged by year
Highlighted Reader Comments
I can have a far wider selection of electronic components delivered overnight for cheaper from Amazon, Mouser or Digikey. The need for a brick and mortar electronics store is long over. Time marches on. - rriggsco
| Year | ElectronicsManufacturing | RadioShacks |
|---|---|---|
| 1990 | 1902 | 4300 |
| 1991 | 1809 | 4711.111111 |
| 1992 | 1707 | 5122.222222 |
| 1993 | 1656 | 5533.333333 |
| 1994 | 1651 | 5944.444444 |
| 1995 | 1689 | 6355.555556 |
| 1996 | 1747 | 6766.666667 |
| 1997 | 1803 | 7177.777778 |
| 1998 | 1831 | 7588.888889 |
| 1999 | 1781 | 8000 |
| 2000 | 1820 | 7735.5 |
| 2001 | 1749 | 7471 |
| 2002 | 1507 | 7206.5 |
| 2003 | 1355 | 6942 |
| 2004 | 1323 | 6677.5 |
| 2005 | 1316 | 6413 |
| 2006 | 1308 | 6148.5 |
| 2007 | 1272 | 5884 |
| 2008 | 1244 | 5619.5 |
| 2009 | 1137 | 5355 |
| 2010 | 1094 | 5090.5 |
| 2011 | 1103 | 4826 |
| 2012 | 1089 | 4561.5 |
| 2013 | 1066 | 4297 |
| 2014 | 1049 | 3547.75 |
| 2015 | 1053 | 2798.5 |
| 2016 | 1048 | 2049.25 |
| 2017 | 1039 | 1300 |
| 2018 | 1054 | 500 |
| 2019 | 1075 | 485.3333333 |
| 2020 | 1063 | 470.6666667 |
| 2021 | 1060 | 456 |
| 2022 | 1090 | 441.3333333 |
| 2023 | 1108 | 426.6666667 |
| 2024 | 1105 | 412 |
| Name | Year | Stores |
|---|---|---|
| RadioShacks | 1990 | 4300 |
| RadioShacks | 1991 | |
| RadioShacks | 1992 | |
| RadioShacks | 1993 | |
| RadioShacks | 1994 | |
| RadioShacks | 1995 | |
| RadioShacks | 1996 | |
| RadioShacks | 1997 | |
| RadioShacks | 1998 | |
| RadioShacks | 1999 | 8000 |
| RadioShacks | 2000 | |
| RadioShacks | 2001 | |
| RadioShacks | 2002 | |
| RadioShacks | 2003 | |
| RadioShacks | 2004 | |
| RadioShacks | 2005 | |
| RadioShacks | 2006 | |
| RadioShacks | 2007 | |
| RadioShacks | 2008 | |
| RadioShacks | 2009 | |
| RadioShacks | 2010 | |
| RadioShacks | 2011 | |
| RadioShacks | 2012 | |
| RadioShacks | 2013 | 4297 |
| RadioShacks | 2014 | |
| RadioShacks | 2015 | |
| RadioShacks | 2016 | |
| RadioShacks | 2017 | 1300 |
| RadioShacks | 2018 | 500 |
| RadioShacks | 2019 | |
| RadioShacks | 2020 | |
| RadioShacks | 2021 | |
| RadioShacks | 2022 | |
| RadioShacks | 2023 | |
| RadioShacks | 2024 | 412 |
Analyzing the version numbers of 621 programming languages
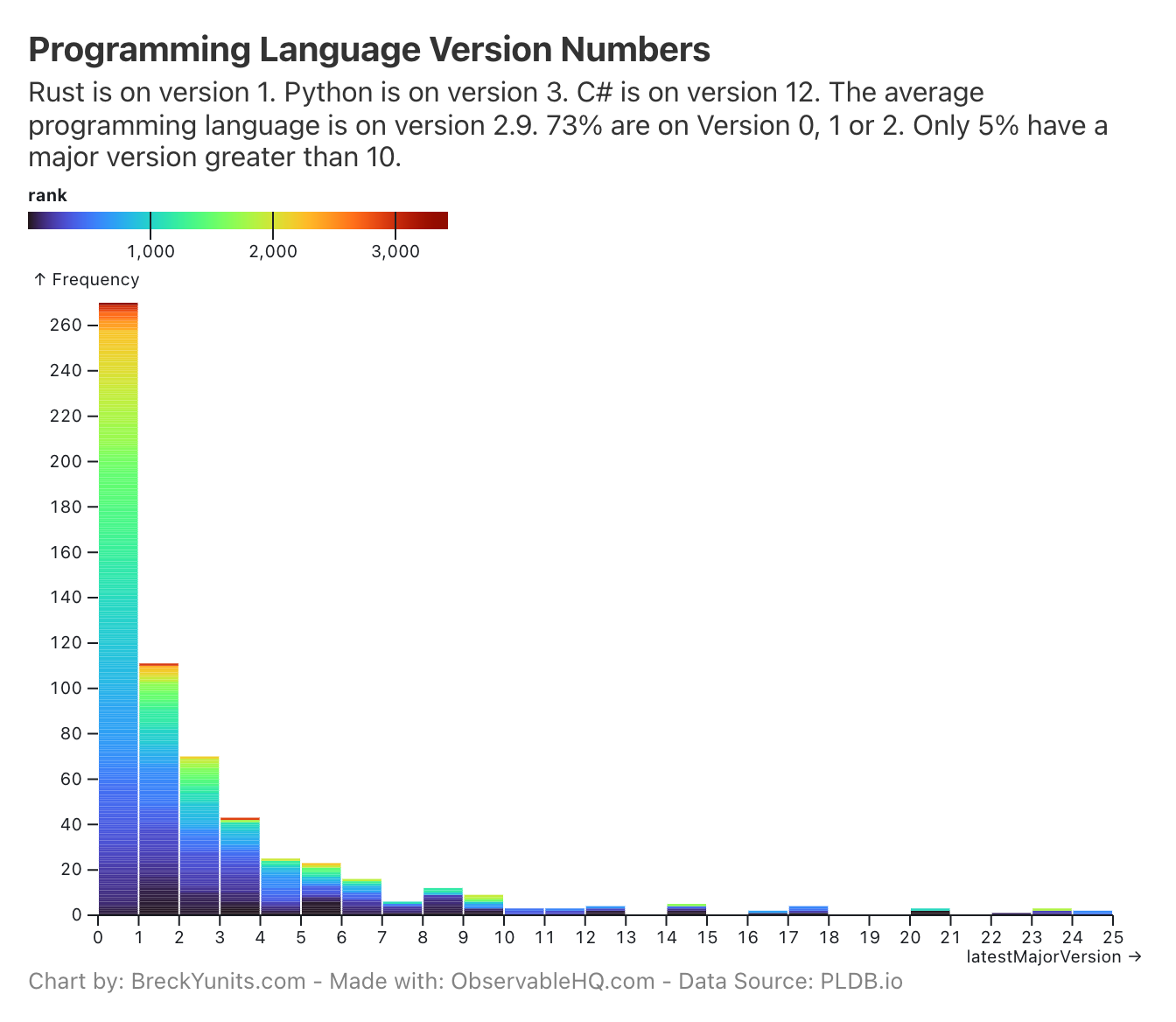
May 25, 2024 — I just pushed version 93.0.0 of my language Scroll. Version 93!
Why so many versions? I use Tom Preston-Warner's Semantic Versioning (2011).
In particular, I followed his advice in Major Version Numbers are Not Sacred.
Pushing so many major versions was no big deal because Scroll was a toy.
But Scroll now has a novel feature that makes it very useful.
I need to decide if I should ship fewer major versions with higher quality.
Let's do some research on what other programming language developers are doing.
I added version number data to over 600 languages in PLDB.
What major version are programming languages on?
| 0Min | 1Median | 2.9Average |
| 73%< v3 | 95%< v10 | 99%< v30 |
Wow! No languages in the top 400 have surpassed 30 major versions.
Erlang, at version 27, ranks #34 and is the only top 100 language with more than 25 major versions.
My language, at version 93, is a huge outlier. Maybe I've done something wrong 😳.
Let's plot version number by rank.
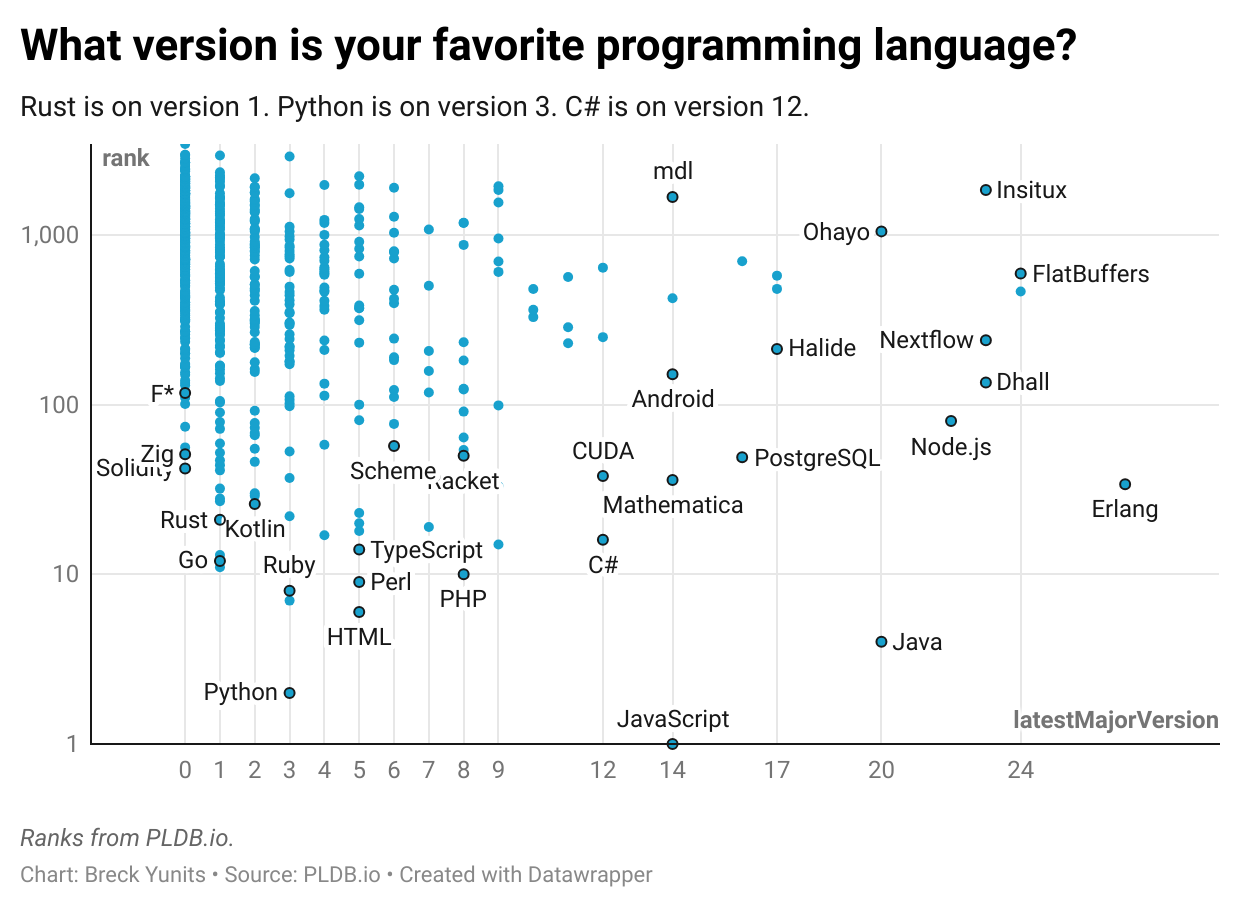
We can see that there is a positive correlation between how many major versions a language has and how popular it is.
However, we can also see that 5 of the top 10 languages are on version 5 or less.
We can also see that ~15 of the top 25 languages are on version 5 or less.
If you have a great model of your core ideas, you can ship fewer major versions.
What's the relationship between age of the language and the current major version?
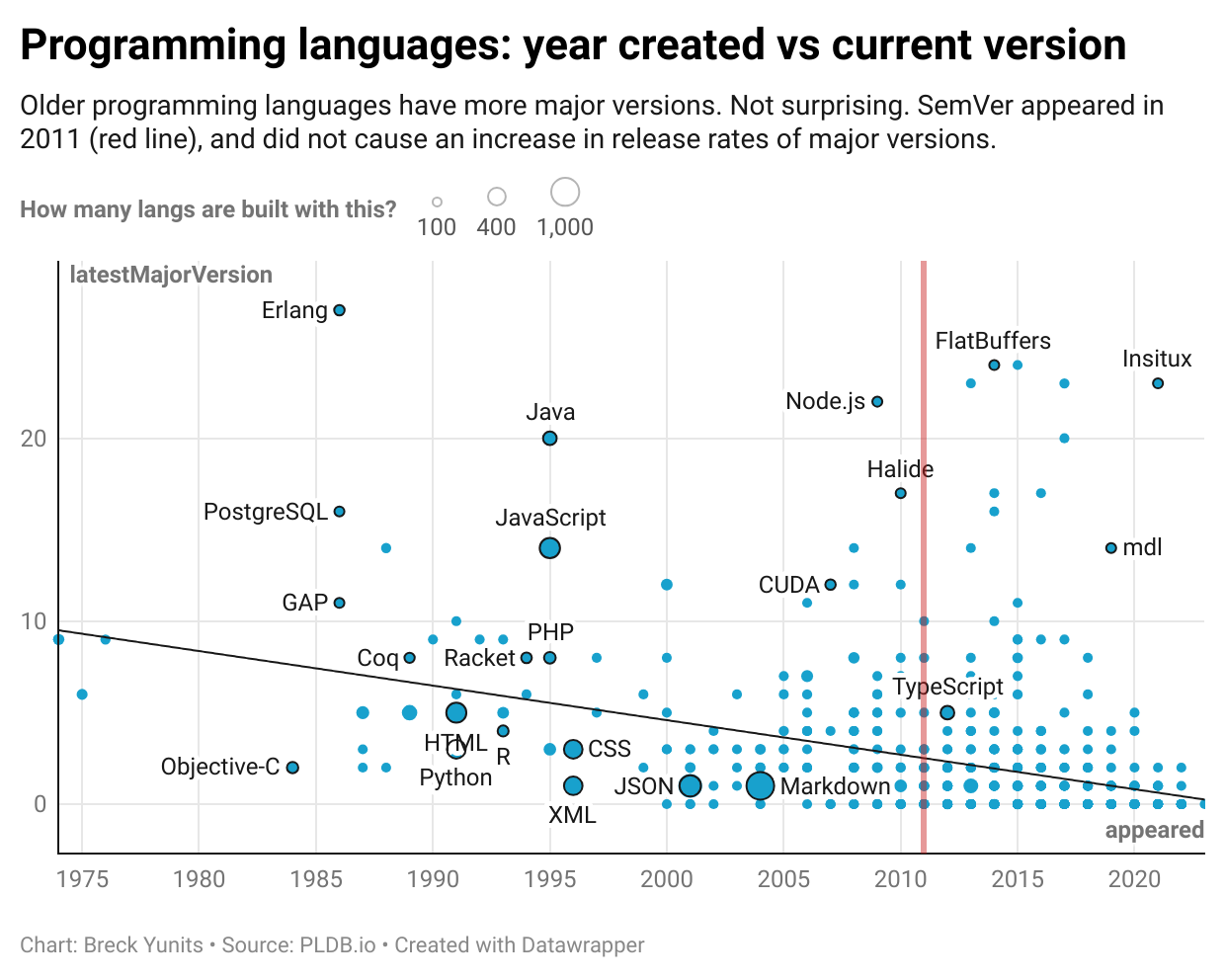
Did Semantic Versioning, published in 2011, change release rates of major versions of programming languages?
No. As you can see:
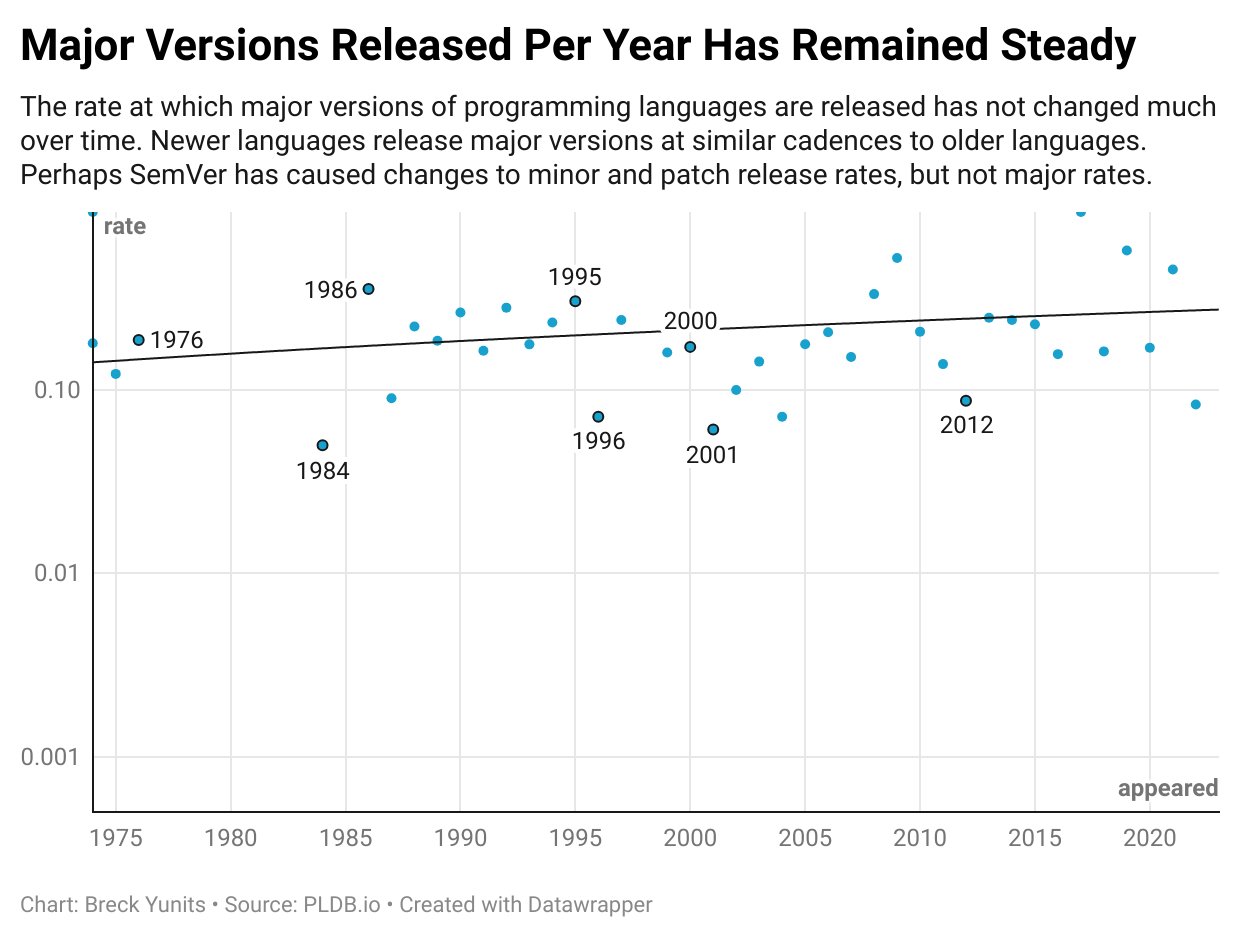
So, what did I learn?
TIL I did SemVer wrong. In particular, I missed this part:
If you’re changing the API every day you should...still be in version 0.y.z
Whoops!
It took me about 5 years to figure out what Scroll 1.0.0 should be. I should be on version 0.93.0, not version 93.0.0.
No big deal. I will soon release Scroll 100.0.0, and from then on will have far fewer major releases.
An ounce of deep thought on the core of your language is worth a pound of major releases!
Other things I learned
- I learned 97.5% of languages with a version system use Semantic Versioning. The ~2% of languages, such as C and C++, that are still doing versions like C17 (which does not mean major version 17, but refers to the year the revision came out), maybe want to reconsider ;).
- I learned most languages use git tags for tagging their releases. Something I should start doing.
I learned a few things today. Hope you did too!
Notes
- Thank you to redditors Greenbeen86, subgeniuskitty, and chibuku_chauya for pointing out the bug with the C and C++ rows.
A Suggested Improvement to Progress Bars
May 24, 2024 — When I was a programmer at Microsoft I participated in a lot of internal betas.
So I saw a lot of animated "progress" bars in software that were actually hung.
I bet you could invent a better progress bar, I thought.
But life went on and I forgot.
Yesterday my FitBit app showed an animated progress bar for hours. It turned out no progress was being made—the phone had no Internet connection.
But it made me remember my progress bar idea!
Every time someone starts a long task, measure the duration and end result. Then you have the data to render a progress bar like the one above.
The green and red areas show tasks completions and aborts.
The moving line shows elapsed time.
The color of the moving line shows the odds that a task will succeed, given the amount of time passed.
It helps your users decide: should I wait or abort?
A famous celebrity passes away and wakes up on a beach.
"Welcome to the Afterplace", says a man in white.
He extends his hand and helps her to her feet.
"You must be hungry. Let me show you to the Omni Restaurant."
They walk from the water to an enormous restaurant.
The entire front of the restaurant is a glass wall facing the ocean.
The restaurant appears to extend endlessly in both directions.
A sliding glass door opens and they walk inside.
The ceilings are a hundred feet tall.
Even though countless people are dining, the restaurant is so large that it is quiet and uncrowded.
"Please have a seat," he says, gesturing to a table with his hand.
"At the Omni Restaurant, you can order any dish ever invented by human civilization."
"Whatever you want, just speak it into your table."
She sits down and says "Portobello mushrooms please."
Suddenly, on the back wall, a hole five feet in diameter opens up.
Then, flying out of the hole comes a silver platter.
The platter hovers over her table then gently floats down.
On it is a perfectly grilled Portobello mushroom.
The former celebrity smiles, grabs the fork and knife, and takes her first bite.
"Oh my god. This is the best Portobello mushroom I've ever tasted", she says.
The man nods his head, turns and leaves her to her meal.
After her meal she explores the grounds.
Eventually she tires and spends the night in a luxurious hammock.
The next morning she returns to the Omni Restaurant.
"Bacon and eggs please," she says.
'COMBINATIONS NOT ALLOWED,' a robotic voice says back.
A few people turn to look.
Her face crunches.
"Portobello mushroom please," she says.
Whew, she thinks.
Delicious. The same as yesterday.
Her face relaxes.
Is it exactly the same?
Her face crunches again.
After another day exploring the grounds, she returns to the Omni Restaurant for dinner.
"Filet Mignon please."
'FILET MIGNON IN USE,' the robot voice responds.
People look.
Her face crunches.
"Umm...ummm...lobster please"
A hole appears in the wall.
Her face relaxes.
A silver platter carrying a deep-red lobster lands in front of her.
"Butter please"
'CUSTOMIZATIONS NOT ALLOWED'.
Day 3 is off to a bad start.
"Bacon please."
'BACON IN USE.'
"Eggs please."
'EGGS IN USE.'
"Peanut butter please."
'PEANUT BUTTER IN USE.'
Many eyes are on her.
Her face crunches.
Then her face turns red.
She clenches her fists and stands up.
She looks at other people's tables.
She sees countless varieties of chips, candy bars, and cereals.
She also sees for the first time that the other diners are malnourished.
Screw this!
She storms to the back wall.
Someone orders a meal and a hole opens.
She dives through.
She lands on her hands and knees.
Then she stands up and looks around.
"What the?!"
There is no kitchen and no cooks.
There is nothing at all on this side of the wall.
She rubs her eyes in disbelief as she watches dish after dish materialize from nothing then fly out through a hole in the wall.
Suddenly she feels a tap on her shoulder.
"What are you doing back here?," asks the man in white.
"What am I doing back here? What am I doing back here? What are YOU doing back here?"
"People out front are malnourished."
"They can't order combinations. They can't customize their orders. And they can't eat something if someone else is eating it."
"And now I see that the physics of the Afterplace means all of the rules of the Omni Restaurant don't make any sense!"
"I DEMAND you take me to the being who designed this place."
"That will not be a problem."
"If you will just follow me."
She follows him back to the front of the restaurant.
They walk for miles past tables and tables of diners.
Finally the man in white comes to a stop.
In front of him, eating a bowl of cereal, is a man in a Vicuna suit.
"Here sits the Omni Restaurant's creator," he gestures with his hand.
"Stan?! It can't be Stan!"
"You know him?"
"Of course!"
"He's my copyright lawyer!"
by Breck Yunits
All tabular knowledge can be stored in a single long plain text file.
The only syntax characters needed are spaces and newlines.
This has many advantages over existing binary storage formats.
Using the method below, a very long scroll could be made containing all tabular scientific knowledge in a computable form.
There are four concepts to understand:
- measures
- concepts
- measurements
- comments
Measures
First we create measures by writing parsers. The parser contains information about the measure.
The only required information for a measure is an id, such as temperature.
An example measure:
temperatureParser
Concepts and Measurements
Next we create concepts by writing measurements.
The only required measurement for a concept is an id. A line that starts with an id measurement is the start of a new concept.
A measurement is a single line of text with the measure id, a space, and then the measurement value.
Multiple sequential lines of measurements form a concept.
An example concept:
id Earth
temperature 14
Comments
Unlimited comments can be attached under any measurement using the indentation trick.
An example comment:
temperature 14
> The global mean surface air temperature for that period was 14°C (57°F), with an uncertainty of several tenths of a degree.
- NASA
https://earthobservatory.nasa.gov/world-of-change/global-temperatures
The Complete Example
Putting this all together, all tabular knowledge can be stored in a single plain text file using this pattern:
idParser
temperatureParser
id Earth
temperature 14
> The global mean surface air temperature for that period was 14°C (57°F), with an uncertainty of several tenths of a degree.
- NASA
https://earthobservatory.nasa.gov/world-of-change/global-temperatures
Once your knowledge is stored in this format, it is ready to be read—and written—by humans, traditional software, and artificial neural networks, to power understanding and decision making.
Edit history can be tracked by git.
A Visualization
Dark blue dots are measure ids. The first sections are measure definitions (aka parsers). The next sections are concepts. The red dots are measurement values. The blue-red pairs are measurements. The light blue dots are comments/code. View Source
Prior Art
Modern databases[1] were designed before git[2], fast filesystems[3], and the Scroll stack[4], all requirements of this system.
GNU Recutils[5] deserves credit as the closest precursor to our system. If Recutils were to adopt some designs from our system it would be capable of supporting larger databases.
Initial Implementation and Experimental Evidence
ScrollSets is the name of the first implementation of the system above. It is open source and public domain.
ScrollSets are used to power the open source website PLDB.io. PLDB currently has over 300 measures, over 4,000 concepts and over 150,000 measurements, contributed by over 100 people, dozens of software crawlers, and a couple of artificial neural networks.
If printed on a single scroll, the PLDB ScrollSet would be over one kilometer long.
Enhancements
- For pragmatic reasons, it is best to split your data into 1 file per concept and combine concept files at runtime.
- The utility and joy of this system improves as your parser language improves. The parser language powering ScrollSets is currently called Parsers, and is largely influenced by ANTLR[6] and Racket[7].
- It is very helpful to have a
sortIndexattribute on your measures to automatically prioritize[8] the measurements in your source and output files. The impact of this simple enhancement hints at interesting signs of dense information packing achieved by this method, which may have implications for the weights and training of artificial neural networks. - Computed measures are measurements not stored statically, but derived at runtime from other measurements. They are very useful and easy to add with a few lines of parser code.
- You generally always want to add a type attribute to your measures, which gives you error checking, among other things.
- Measures can be nested. This means it is best to be restrictive in what characters are allowed in measure ids to integrate with a broad set of software tools. For example, you can nest a
minParserundertemperatureParserto generate atemperature_mincolumn name in a generated TSV. - It is useful to have measures whose values are foreign keys, such as a list of
ids.
Conclusion
Measurements loosely map to nucleotides; concepts to genes; parsers to ribosomes.
This system might also have broad use.
You can read more about ScrollSets on the Scroll blog, see small demos at sets.scroll.pub, and see the large implementation at PLDB.io.
Citations
[1] SQL: Donald D. Chamberlin and Raymond F. Boyce
[2] Git: Linus Torvalds, Junio Hamano, et al
- The M1 laptop was the first consumer machine where the performance of this system wasn't abysmal.
[4] Particles: Breck Yunits et al (formerly called Tree Notation)
[5] GNU Recutils: Jose E. Marchesi
- Recutils and our system have debatable syntactic differences, but our system solves a few clear problems described in the Recutils docs:
- "difficult to manage hierarchies". Hierarchies are painless in our system through nested parsers, parser inheritance, parser mixins, and nested measurements.
- "tedious to manually encode...several lines". No encoding is needed in our system thanks to the indentation trick.
- In Recutils comments are "completely ignored by processing tools and can only be seen by looking at the recfile itself". Our system supports first class comments which are bound to measurements using the indentation trick, or by setting a binding in the parser.
- "It is difficult to manually maintain the integrity of data stored in the data base." In our system advances parsers provides unlimited capabilities for maintaining data integrity.
[7] Racket: Matthias Felleisen, Matthew Flatt, Robert Bruce Findler, Shriram Krishnamurthi, et al.
Thanks
Thank you to everyone who helped me evolve this idea into its simplest form, including but not limited to, A, Alex, Andy, Ben, Brian, C, Culi, Dan, G, Greg, Jack, Jeff, John, L, Liam, Hari, Hassam, Jose, Matthieu, Ned, Nick, Nikolai, Pavel, Steph, Tom, Zach, Zohaib.
High Impact Thoughts

Leibniz thought of Binary Notation; Lovelace of Computers; Darwin of Evolution; Marconi of the Wireless Telegraph; Einstein of Relativity; Watson & Crick of the Double Helix; Tim Berners-Lee of the Web; Linus of Git.
Even more importantly to you and to me, at some point our mothers and fathers thought to have us.
And since we were born, many people throughout our lives have had thoughts that had high positive impact on us.
If you believe we live in a Power Law World, then it follows that there is nothing with higher expected value; nothing with more leverage; nothing with higher ROI; nothing with higher impact; than High Impact Thoughts (HITs).
HITs dominate both our professional and personal lives. Let's take a closer look.
How rare are HITs?
I've filled many notebooks over the years with potential HITs.
Looking at my notebooks, I would say I generate between 2 and 10 HIT candidates per day.
What is the difference in magnitude between the lowest impact thought and the highest?
I have found it very hard to predict in advance what the impact of a HIT is going to be. I have to act on the HIT first.
I am often off by many orders of magnitude. Sometimes I predict a thought is a surefire HIT but then after I act on it the predicted high impact is nowhere to be found. Instead the real impact is like that of a falling leaf.
Other times I see what seems like a small, mildly interesting idea, I act on it in minutes, and it impacts my life for decades.
Still other times I predict a thought will have a big impact, it has only a tiny impact, but then years later a slight tweak makes it have the impact I originally predicted.
Or sometimes an idea has a big initial impact, but turns out to be inconsequential in the long run.
Since we live for less than one million hours, then the smallest HITs on you personally, measured in hours, would have an impact of ~1, and the biggest HITs would have an impact of ~100,000. So the HIT range on an individual is 6 orders of magnitude.
If you consider the impact your HITs can have on your family, friends, and communities, the impact range expands further.
A Recursion: HITs about HITs
It follows from the ideas in this essay that the biggest HITs would be thoughts about big HITs. Let's call these HITs about HITs: HITs!.
If this essay is true, then it should be one of the most impactful I ever write and one of the most impactful you ever read. It should be a HIT!.
But of course, as I mentioned above, it is hard to predict in advance how big a HIT will be, and sometimes it will be years before the right tweaks are made to make something a big HIT.
If this essay you are reading now does not have a big impact, perhaps a future version will.
I share the git for this blog, so if this essay does become a HIT we'd be able to see which tweaks caused that phase change.
If HITs! have the highest expected value, why not spend all day seeking HITs!?
What's the point of thinking about lowly HITs when HITs! dominate?
I can think of five reasons.
The first is that you don't know whether you've got a HIT until you act on it and get it past the payoff point. Focus and details matter. Nature does not care if you are close to a HIT, you've got to get it all the way past the payoff point.
The second is that your brain needs data to generate HITs. You've got to balance experience with reflection. Too much reflection and your brain won't have enough data to generate novel HITs.
The third is more practical: you have to breathe, eat, drink, sleep, exercise, be social, et cetera. Generating HITs is harder if you're unhealthy. To generate HITs in this world you have to stay alive.
Fourth, there's a fair amount of randomness in HIT Seeking. With 100 billion humans born so far, many of them who never thought about HITs will have bigger HITs than you, simply through chance. You can certainly do things to tilt the odds in your favor of seeing more HITs, but ultimately the dominant term in what HITs you will see is not something you get to control.
Finally, one HIT is "don't take life too seriously—no one's ever gotten out alive." If you were to spend all your time HIT! Seeking, due to randomness, you might not ever discover the most impactful HIT!, which could be the one I just mentioned.
HIT Seeking
Alright, so if one believes in the strategic importance of HITs, but also understands that HIT Seeking should not be overdone, what are some tactical things one can do?
The most important thing is probably to setup your life so you can spend a substantial amount of time HIT Seeking. I like to aim for 2 - 4 hours per day.
What does HIT Seeking look like? Walks in the woods, meals with friends, yoga, naps, long hot showers, quiet sitting, conversations with LLMs, drawing, playing in the sand with your kids, doing at home experiments. That sort of thing. The highest impact work often doesn't look like work.
Ask a lot of questions. Really drill down into the details. Don't worry much about words. Mental models—being able to picture things in your head, and rotate them—that is what matters.
It's not enough to see potential HITs. It's not enough to just write them down.
Those are required, but you also have to act on them. You will learn that your early versions always get a lot of important things wrong. And you will never know the impact of a HIT until you've taken it past the payoff point.
Finally, always keep at least one slot open for the biggest HIT you have yet to find. Always assume it could come at any time. Don't sit there waiting for it—alternate between acting on the best HITs you have in front of you and HIT Seeking—but always be ready to act when a far bigger HIT arrives.
That's all I have on this matter. For now.
Happy HIT Seeking!
Related Posts
May 15, 2024 — I typed tail -f pageViews.log into my console.
Then pressed Enter.
I stared at my screen as it streamed with endless lines of text.
Each line evidence of a visitor interacting with my new site.
It had been like this for days.
Holy shit, I thought.
This must be "Product Market Fit".
Startup Growth Rates
You can categorize all startups into a handful of classes.
If you start a business washing clothes and your only equipment is a bathtub, you have a Log Business.
Buy some washing machines, and now it can be a Linear Business.
Add some employees and you might go Log Linear.
But if you develop it into a Laundromat Franchising Startup, now you might enter the realm of Quadratic and Exponential Businesses.
When Growth Rate Phase-Changes
"Venture Capital" is the sport of trying to build Quadratic and Exponential Businesses.
"Product Market Fit" (PMF) is the term for when your startup phase-changes from a Linear or Log Linear business to a Quadratic or Exponential one.
You detect PMF when you see your numbers accelerate upward.
It's like moving from skiing the bunny slopes to heli-skiing.
PMF Frequency
They say PMF is a rare thing. Maybe 1% of startups experience that kind of phase-change.
I've been in this world for a couple of decades, and that sounds about right to me.
I have seen it a number of times, mostly from the years I lived in San Francisco.
I remember when the Dropbox and Airbnb gatherings went from beers around makeshift offices to having guest lists a thousand names long at the hippest venues in the city.
When you make something that hits PMF—something that a lot of people want—the customers and resources come streaming.
It's a lot to deal with, good and bad.
Searching For PMF
I have long had a technology that I thought might evolve to be in the Quad or Expo Class.
In 2017, I launched it.
The response was crickets.
So, in 2019, I launched it again.
Again, crickets.
I launched again in 2021. And again. And again. And again.
Crickets every time.
Then in 2022, right before I launched for the 20th(?) time, I did 2 unrelated things, that, combined with this launch, would create one heck of a PMF mirage.
The Launch
The first thing I did was pay for a premium domain name. I thought maybe if the domain looked more expensive, people might share the product more.
The second thing I did was drop Google Analytics and add web server logs.
I did these things, along with a lot of more substantive product work, and "launched" my product on HackerNews, Reddit, and Twitter.
I then went to the playground with my daughters, assuming crickets again.
The "Metrics"
The next day, I was pleasantly surprised to see hundreds of upvotes and many good signs that people were finding my thing useful.
I enjoyed the small rush of dopamine—those helpful little payoffs that help one get through the laborious years of building—but I expected the increase in users to be fleeting, like it had been in the past.
However, the traffic didn't stop.
No matter what time of day, when I looked at the live server logs, a lot of people were visiting the site.
It's finally happening. I thought.
I made something people want. It is somewhere in the Quad/Expo class. I've got PMF. I can now can get the resources to fully build out the vision.
The Realization
Six months and much confusion later, I finally realized my dumb mistake.
Premium domains may or may not be helpful, but they certainly get a lot more bot traffic.
And, in the decades since I last used server traffic logs, the Internet filled up with many bots that have User Agents posing as humans.
I had not yet hit PMF.
It was a PMF mirage.
This is an embarrassing mistake to make.
I write this blog post a year later because I realize I've actually made it a few times in my career[1]. I want to greatly reduce the odds I make this mistake again.
The Opposite Mistake
Of course, I have also made the opposite mistake.
I have invested in businesses and taken Log Linear gains only to watch from the sidelines as the business phase-changed into Quad/Expo.
I bought SellNothing.com years ago to remind myself of mistakes like the time I took a 10x gain on NVidia, and a 100x gain on Bitcoin, instead of just sitting on the beach and getting 100x and 10,000x gains.
I have proof that I can be fooled in either direction.
What have I learned?
Never ever got cocky over man made metrics. Ultimately, man made metrics are meaningless. God doesn't care about man made metrics. The second you get cocky about man made metrics, nature will humble you.
Don't care about metrics emotionally, but do use them for practical purposes.
If you are the one building the thing, assume positive metrics are faulty. Especially superficial metrics like views and likes.
If you are committed to building something for the long term (and if you're not, you should be doing something else), it's unhealthy to get excited over short term metric bumps anyway.
Make sure you have a really strong mental model of the world and how your product fits into that.
Your mental models should be your primary source of truth. Metrics should merely be automated tests that your models predict reality.
Don't think just because you've worked on something for a long time that at some point it has to hit PMF. Nature does not owe you PMF.
You've always got to zoom out to improve your mental models, and zoom in to execute on the many details required to implement them.
You have got to build past the payoff points on your projects to realize the leverage from a good Quad/Expo idea.
You have to be long term oriented.
Remember, things in the Quad and Expo classes only become Quad and Expo over time. So slow down, spend more time thinking about your models and less time looking at your metrics.
Finally, always make sure you are getting enough sleep.
Back on the Bike
Just because I made a dumb mistake and got burned from a PMF Mirage, doesn't mean I want to stop trying to build Quad and Expo things.
It is fun to build products in the Quad and Expo classes.
It's definitely not a good reason to live an unbalanced life.
But if you can live a balanced life and find a way to make your work focused on building things with high leverage in the Quad/Expo classes, that's a fun world to work in.
Just beware of PMF mirages.
Notes
[1] In 2016 I once misconfigured Google Analytics and thought users were using our data visualization tool for far longer than they actually were. Luckily in that case, it only took a few weeks to realize my error, not months.

AIs may train on everything. You may not.
May 14, 2024 — In America, AIs have more freedom to learn than humans. This worries me.
Do you want learn at the same library as ChatGPT, Gemini, Grok, or Llama?
Then you must become a criminal.
You have no legal option[1].
This sounds ridiculous.
Human made laws that work against humans?
But it is true.
The problem is Copyright Law. Specifically, Digital Copyright.
Big corporations have the resources to legally build massive internal libraries of all the world's published information.
Their AIs can legally train on this.
Humans in America have to choose: use a criminal library, or fall behind AIs?
A Proposed Fix
We can just abolish copyright.
Among other benefits, this would ensure all Americans have the same freedom to learn as AIs.
Does Digital Copyright matter?
Of course, we may not need to update the law.
- Good people publish their content freely.
- Digital copyright goes against the grain of nature so much, that it has long been ignored and worked around by smart and courageous citizens, who have built these "criminal" libraries.
- AI generated content may become much better than the best human generated content. And then the entire concept of copyright will be irrelevant.
But you never know.
Now might be a good time to set into law equal educational rights between humans and AIs.
While the laws are still set by humans.
Notes
[1] Well, there is no legal way for YOU to do it. A billionaire could theoretically afford to buy the "rights" and build their own library as good as a big corporation. But no billionaire is reading this post. Nevertheless, to be precise, only ~756 out of ~333,333,000 Americans ~have a legal way to train on the same materials as AIs.
May 12, 2024 — The Four Seasons website says
Treat others as you wish to be treated
Sometimes Four Seasons sends me random emails.
When I reply with a random email of my own I get
DoNotReply@fourseasons.com does not receive emails.
People don't want to interrupted by email bots.
And people especially don't want to be interrupted by email bots that don't listen.
If you are implementing email for a company please know that there is never a reason to use a no-reply email address--there is always a more user-friendly, more human way. 100% of the time.
Let's infuse the Internet with the intelligent design and warm hospitality of Izzy Sharpe's (real life) hotels.
Related Posts

May 11, 2024 — That charts work at all is amazing.
Forty years.
One-billion heart beats.
Four-quadrillion cells.
Eight-hundred-eighty-octillion ATP molecules.
Compressed to two marks on a surface.
You put marks on a surface to stimulate your visual system as if you were looking at real things.
When you look at real things you don't need marks.
Look at your two feet right now.
You can compare and contrast and model directly.
But what if you want to compare your feet now to your feet decades ago?
It is impossible to fly through time and compare directly.
It is impossible to press a button and materialize a hologram of your infant self.
But you can use marks.
What if you want to compare your feet to the feet of hundreds of others?
It is impossible to pause time and fly across space to do it.
It is impractical to herd everyone together to do it.
But you can use marks.
Marks stimulate our retinal cells and visual pipelines like real things.
This is amazing.
Marks make science possible.
They allow us to compare and contrast and model infinite things across space and time.
Even binary depends on marks.
Binary delivers precision:
00000100
00001011
But for meaning, it takes marks.
by Breck Yunits

The boy looked up at the tree that was ten times taller than the others.
Then he looked down and saw an old man sitting in a carved out stump next to the tree.
"Excuse me mister, why is that tree so tall?" the boy asked.
Gray Beard explained the tree.
"Do you understand?"
"Yes. I understand," said the boy.
The boy turned around and walked out of the forest back to the city.
In the city the boy met many people.
One day a friend had a problem with her eye.
He helped her get the right medicine.
The boy decided to learn more about medicines.
He got a job selling medicines.
A few years later he had saved some money.
He returned to the forest and found Gray Beard sitting in his carved out stump by the tall tree.
He told Gray Beard about his experiences.
Gray Beard again explained the tree.
"Ah! Now I understand," said the young man.
Back in the city the young man began helping people with their projects.
He put his savings into some of his favorite projects.
Years later, one project helped many people and he became rich.
He returned to the forest and found Gray Beard sitting in his carved out stump by the tall tree.
He told Gray Beard about his experiences.
Gray Beard again explained the tree.
"Ah! Finally I understand," said the man.
He left the forest and went back to the city.
In the city he took classes and went to parties and danced and fell in love.
A few years later he looked down at a beautiful crying baby.
He returned to the forest and found Gray Beard sitting in his carved out stump by the tall tree.
He told Gray Beard about his experiences.
Gray Beard again explained the tree.
The new father stood there.
Nothing was said.
He rubbed his own beard.
He left the forest and went back to the city.
"Let us pack then," his wife said to him.
They packed their bags and buckled up their children and drove to the forest.
Back in the forest he went to the tall tree.
The carved out stump was empty.
He walked for miles and miles in circles, looking for Gray Beard.
Eventually he became tired.
He sat down in the stump.
The breeze blew on his face and the birds chirped and the leaves rustled.
He breathed in deeply.
Then he heard a child's voice.
"Excuse me mister, why is that tree so tall?"
by Breck Yunits

Newton, Darwin, and a modern-day scientist go to heaven.
God is at the gate.
"Your research shall determine whether you may enter."
Newton goes first.
He hands over Principia.
God reads Newton's description of gravity and smiles.
He waves him through.
Darwin goes next.
He hands over Origin of Species.
God scans it. "Bingo! You're in."
Finally, our modern-day scientist is up.
God asks for his work.
"Sorry", he says.
"It's paywalled."
Bad models of the world can be dangerous.
We stood at the edge of the lake.
Everyone was in a wetsuit.
Except for me.
Wetsuits: hundreds of people.
Boardshorts: one person.
"You're brave," another triathlete said.
I shrugged.
I was not brave.
I was dumb.
I did not think this through.
If I had done any research, I would have learned that the lake was 50 degrees.
If I had done any research, I would have learned that in 50 degree water, hypothermia sets in at 30 minutes.
I had one minute to think of a model and make a plan before the starter's gun went off.
I've got it, I thought.
When I move, my body generates heat.
The cold will be painful.
Start slow.
Swimming will make me hot.
Then swim the second half faster.
POWWW.
The gun boomed and hundreds of wetsuits dove in the water.
I dove in last, in my boardshorts, and started swimming slowly.
I am typing this story eleven years later. In warm clothes.
And yet, I just felt shivers.
As I learned that day, my model of the world was bad.
Swimming generates heat, but in water that cold, you lose heat 10x faster than you make it.
Back in Lake Berryessa, things were not going as planned.
At the halfway buoy, I was struggling to control my limbs.
My teeth were chattering uncontrollably.
The only thing I had going for me was that my wiser, wetsuit-wearing friend Tom had slowed down, to make sure I stayed alive.
Knowing Tom was there to keep me from drowning, I flapped on.
After half an hour, I made it back to shore.
I had never been so cold.
I was shaking so bad that it took me twelve attempts to lift my leg over my bikeseat for the next part of the race.
But...
I was alive!
And I had learned an important lesson.
Bad models of the world can be dangerous.

Tom, second from left, slowed down to make sure I didn't go down like Jack Dawson.
I was walking in the woods and saw a path on my right. I had never seen this path before.
It was a few feet wide and a foot or two taller than me.
Branches on both sides had been pulled back and up, forming a pointed tunnel through the dense forest.
On the ground, covering up the forest dirt was book after book, like someone had tiled a bathroom floor.
Curious, I started down the path.
The book path was flat like a road. It was easy to walk on.
At first it was a patchwork of hardcover and paperback.
Then at points I found myself walking on magazines. Then newspapers. Then academic journals.
Eventually I was walking on screens, flashing moving images beneath my feet.
At first these things were only on the ground.
But soon they started to build up in layers along the sides of the path.
Eventually I walked between walls of books and papers and screens, walling me off from the forest.
Finally they began to arch overhead, and soon I found myself walking in a tunnel, brightly lit by screens.
Occasionally I would spot a hole where the forest poked through. I would stop and patch the gap.
By now my stomach was growling.
I reached into my pocket for a peanut butter sandwich I had packed long ago.
It had been so long that the sandwich had flattened into almost nothing.
I couldn't figure out how to eat it or unflatten it, so I just pressed on.
I didn't notice the floor was vibrating until it was too late.
I realize now my body had sensed it. It was screaming at me to stop.
But I was in too much of a hurry to see what the next walls had to say.
The last thing I remember is falling through the air on my stomach as a steep rocky cliff rushed by my feet and spinning around to see a tunnel of books and papers and screens rapidly disassembling above me in front of a bright blue sky.
I saw the previous end of the tunnel went to nowhere, over a void, and the new end of the tunnel ended at the edge of the cliff, coming out of the forest full of trees rising high into the sky.
Datasets are automated tests for world models
by Breck Yunits
April 23, 2024 — I wrapped my fingers around the white ceramic mug in the cold air. I felt the warmth on my hands. The caramel colored surface released snakes of steam. I brought the cup to my lips and took a slow sip of the coffee bean flavored water inside.
Happiness is a hot cup of coffee in a ceramic mug on a cold day.
But, like happiness, heat is fleeting.
How can I keep the coffee hot?
I am using a free ceramic mug I got at a work conference.
That's the issue.
I pour my coffee into a ceramic mug I bought at HomeGoods.
Expensive mugs hold heat better.
It gets cold anyway.
My hands can feel the heat rushing from the ceramic. It must be the material.
That's the issue.
I buy an insulated metal mug.
A better material than ceramic is the most important thing for holding heat.
It gets cold anyway.
I combine my theories. I buy an expensive insulated metal mug.
It gets cold anyway.
Wrong again.
Let me try a new approach.
I go back to HomeGoods and buy a thermometer and stopwatch.
I line up the 3 coffee mugs. Pour hot coffee in each.
Every five minutes, I write down the temperature in each mug.
I plot the data in a line chart.
There are some differences, but they are minor.
"What are you doing?" my cousin asks.
I explain the situation.
"Try my mugs, they have covers", he says.
I repeat the experiment and add the new data to my dataset.

The lab. I measured how long these 5 coffee mugs kept coffee hot.
The coffee in my cousin's covered metal mugs stays hot.
Materials and covers are the key.
I still can't explain why.
What is heat?
I know I can build a much better model.
But I have successfully discarded false models.
And now I have a dataset to test all future models against.
Takeaways
- Datasets are automated tests for world models.
- Building datasets can be done first, orthogonal to models. What Test Driven Development is to programming, Dataset Driven Development is to science.
- You can only hold so many concepts in your head at once, so automated testing from datasets helps more the more complex the system.
- Beware stories lacking datasets!
- Also beware stories that start with true datasets but then discreetly (but swiftly) switch to false ones.
- Love data sharers, beware data misers.
- An ounce of good data is worth a pound of bad models.
- An additional concept, measure, or measurement are all capable of triggering a huge leap toward a more accurate model.
- Datasets are a useful, simple, and timeless tool to discover better models.
- Datasets are particularly good at automating the identification of bad models.
- Tabular UIs have superior ergonomics for humans because they allow more efficient eye movement and require fewer tokens to manage.
- All that being said, remember that datasets are shadows, ultimately the models, not the datasets, are the important thing!
Footnotes
I took some narrative liberties above[1], but for accuracy and fun[2], I really did this experiment.
The Raw Data

This is both a dataset on thermal dissipation and penmanship deficiency.
The Data Visualized
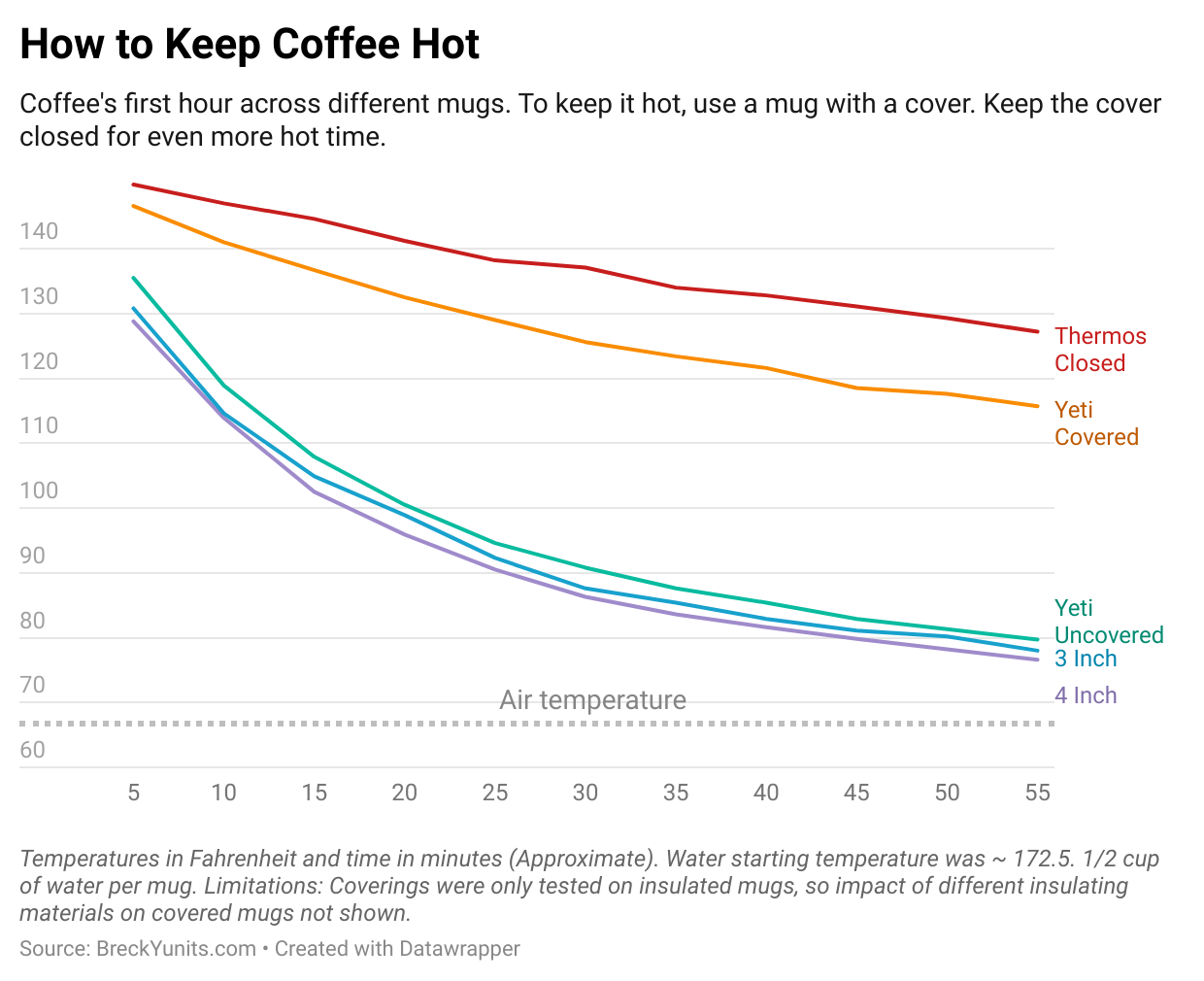
The Typed Data
| Index | Name | Diameter | Height | Covered | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 | 45 | 50 | 55 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Thermos | 3 | 7.25 | TRUE | 149.9 | 147 | 144.6 | 141.2 | 138.2 | 137.1 | 134 | 132.8 | 131.1 | 129.3 | 127.2 |
| 2 | Yeti Covered | 4 | 3.8 | TRUE | 146.6 | 141 | 136.7 | 132.5 | 129 | 125.6 | 123.4 | 121.6 | 118.5 | 117.6 | 115.7 |
| 3 | Yeti | 4 | 3.8 | FALSE | 135.5 | 118.9 | 107.9 | 100.5 | 94.6 | 90.8 | 87.6 | 85.4 | 82.9 | 81.3 | 79.7 |
| 4 | SF | 4 | 4.5 | FALSE | 128.8 | 113.9 | 102.5 | 95.9 | 90.5 | 86.3 | 83.6 | 81.6 | 79.8 | 78.2 | 76.6 |
| 5 | Aruba | 3 | 3.75 | FALSE | 130.8 | 114.6 | 104.9 | 98.9 | 92.3 | 87.6 | 85.4 | 82.9 | 81.1 | 80.2 | 78 |
The Best Model of Heat
[Coming in a future post]
Footnotes²
[1] There was no cousin, nor work conference, nor trips to HomeGoods, I used water and not coffee, and I exaggerated my ignorance and false models. The data and analysis is real.
[2] Everyone[3] agrees making datasets at home is extremely fun.
[3] Dataset needed.
Related Posts
Menu Instructions
Congrats on landing a job at Big O's Kitchen!
Our menu has 7 dishes.
Below are the instructions for making each dish.
1. The Constant
Dump one entire ingredient pack on one plate.
2. The Log
Dump half an ingredient pack on one plate.
Then dump half that plate onto another plate.
Repeat until you make a plate with less than 2 ingredients.
3. The Linear
Open one ingredient pack and put each ingredient on its own plate.
4. The Log Linear
Open an ingredient pack and put each ingredient on its own plate.
Then dump half a new ingredient pack on each of those plates.
Then dump half of each of those plates onto another plate.
Repeat until you make a plate with less than 2 ingredients in each column.
5. The Quad
Open an ingredient pack and put each ingredient on its own plate.
Then for each plate, open another ingredient pack.
Put each of those ingredients on its own plate and portion the original ingredient between those plates.
6. The Expo
Open an ingredient pack.
Put one ingredient on one plate.
Then portion between two plates.
Add the next ingredient equally to all plates.
Now portion each plate into two plates.
Repeat until you have no more ingredients.
7. The Factory
Make a plate for every combination of ingredients in the ingredient pack.
So if today's ingredient pack contains 3 ingredients (bacon, lettuce, and tomato) you should make 6 plates:
- 🥓🥬🍅
- 🥓🍅🥬
- 🥬🥓🍅
- 🍅🥓🥬
- 🥬🍅🥓
- 🍅🥬🥓
Plates needed
| Ingredients | The Constant | The Log | The Linear | The Log Linear | The Quad | The Expo | The Factory |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 2 | 1 |
| 2 | 1 | 1 | 2 | 2 | 4 | 4 | 2 |
| 3 | 1 | 2 | 3 | 5 | 9 | 8 | 6 |
| 4 | 1 | 2 | 4 | 8 | 16 | 16 | 24 |
| 5 | 1 | 3 | 5 | 12 | 25 | 32 | 120 |
| 6 | 1 | 3 | 6 | 16 | 36 | 64 | 720 |
| 7 | 1 | 3 | 7 | 20 | 49 | 128 | 5040 |
Related Posts
The girl lost the race.
"I want to be fast", she said.
"You are fast", said the man.
"No. I want to be the fastest."
"I solved it! If I eat less, I'll weigh less and go faster."
The girl skipped breakfast.
The girl lost the race.
"Next time I'll skip dinner too."
"Ok", said the man, "but the moving trucks are coming. Time to pack."
In the new town, the girl skipped dinner.
She won the race.
"I solved it!", she said.
The man smiled.
She won race after race, in the new town.
At regionals, the girl stayed at the dorm with the other runners.
"Join us for breakfast?" a runner asked.
"No thanks, I skip breakfast to run faster."
The girl lost the race.
"I solved it! I need to eat the right things."
The man smiled.
The girl kept notes on her meals and race times.
The next year, the girl won regionals.
At college, the girl tried the relay.
She was the fastest on the team.
Her team lost.
"I solved it! If I share my notes, everyone will run faster."
The man smiled.
Her team won.
The man got sick.
"I'm proud of you", he said.
After college, the girl turned pro.
She followed her notes, but still lost.
A shoe company sponsored her.
"Take these", said the sponsor's doctor.
"Is that allowed?"
The doctor winked.
The girl won the race.
And the next.
And the next.
She was the fastest in the world.
"How did you do it?"
The reporter asked, sitting across from her in the restaurant at the fancy hotel.
The girl looked at her. Then looked left and down. Then left and up and down again.
It was quiet for a long while.
She finally moved her throat.
"The shoes", she said, with tears in her eyes.
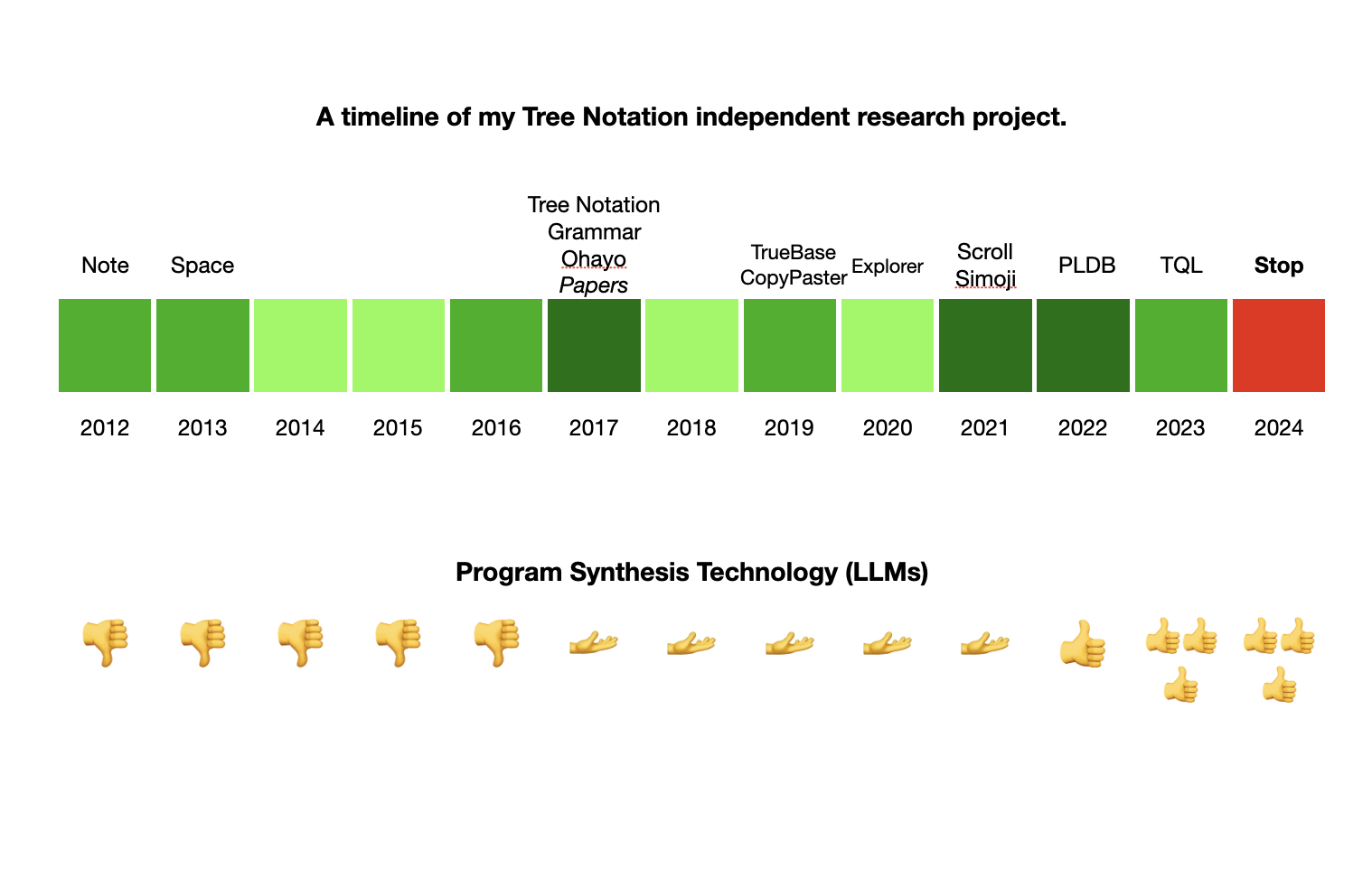
April 2, 2024 — It has been over 3 years since I published the 2019 Tree Notation "Annual" Report. An update is long overdue. This is the second and last report as I am officially concluding the Tree Notation project.
I am deeply grateful to everyone who explored this idea with me. I believe it was worth exploring. Sometimes you think you may have discovered a new continent but it turns out to be just a small, mildly interesting island.
Hypothesis
Tree Notation was my failed decade long research project to find the simplest universal syntax for computational languages with the hypothesis that doing so would enable major efficiency gains in program synthesis[1] and cross domain collaboration. I had recognized all computational languages have a tree form, a 2D grid gave you enough syntax to encode trees, and maybe different syntaxes of our languages was holding us back from building the next generation of programming tools.
Results
The breakthrough gains of LLMs in the past eighteen months have clearly demonstrated that I was wrong. LLMs have shown AIs can read, write, and comprehend all languages across all domains at elite levels. A universal syntax was not what we needed for the next generation of symbolic tools, but instead what we needed was attention layers, smarter chips, huge training efforts, et cetera. The difference between the time of the last report and now is that the upside potential of Tree Notation is no longer there. Back in 2019, program synthesis was still bad. No one had solved it. Tree Notation was my attempt to solve it from a different angle.
Reflection
The failure of this project will come as no surprise to almost everyone. Heck, in the 2019 report even I say "I am between 90-99% confident that Tree Notation is not a good idea". However, we kept making interesting progress, and though it was a long shot, if it did help unlock program synthesis that would have had huge upside. I felt compelled to keep exploring it seriously.
Back in 2019 I wrote "No one has convinced me that this is a dead-end idea and I haven't seen enough evidence that this is a good idea". I have now thoroughly convinced myself, in large part to the abundant evidence provided by LLMs[2], that Tree Notation is a dead-end idea (I would call it mildly interesting, it's still mildly useful in a few places).
Maintenance
I am not ending work 100%. More like 98%-99%. I will likely always blog and am writing this post in Scroll, an alternative to Markdown built on Tree Notation, which I personally enjoy and will continue to maintain. Someday AI writing environments may become so amazing that I abandon Scroll for those, but until then I expect to keep maintaining Scroll and its dependencies. I will also continue to add to PLDB, but have little time to uplevel it and am open to handing it off.
Financial Losses
I feel good about this effort from society's perspective as the world got a mildly interesting idea explored and the losses were privatized. I effectively lost all my money pursuing this line of research, at least in the hundreds of thousands in direct costs of failed applications and more in lost salary opportunity costs. But also, this effort did lead me on a path with certain lucrative side gigs and maybe I would have had less to lose had I not taken it on. Who knows, maybe the new 4D language research (see below) will lead to future gains.
Status of Long Bet
After someone suggested it, in 2017 I made a Long Bet about Tree Notation. My confidence came from my hunch that Tree Languages would be far easier for program synthesis, which would lead to more investment into Tree Languages, which would have network and compounding effects. Instead LLMs solved the program synthesis problem without requiring new languages, eliminating the only chance Tree Languages had to win. So, I now forecast a 99.999% chance the first part of that bet will not win.
My bet did have two clauses, the second predicting "someone somewhere may invent something even better than Tree Languages...which blows Tree Notation out of the water."[3] This has sort of happened with LLMs. At the time of the bet I felt we were on the cusp of a program synthesis breakthrough that would radically change programming, and that happened, it just happened because of a new kind of (AI) programmer and not a new kind of language.
The bet was not about a general breakthrough in programming, but specifically about whether there will be a shuffling in our top named languages. So I see 99.X% odds I will lose the second clause of the bet as well. There remains a chance LLMs make another giant leap and who knows, maybe we start considering something like Prompting Dialects a language ("I am a programmer who knows the languages Claude and ChatGPT"). But I don't see that as likely, even if we are still on the steep part of the innovation curve.
The Other Reason I liked Tree Notation
LLMs have eliminated the primary pragmatic reason for working on Tree Notation research--they solved the program synthesis and cross domain collaboration problems. But I also enjoyed working on Tree Notation because it gave me an attack vector to try and crack knowledge in general. Now, however, I see a far better way to work on that latter problem.
Future Explorations: 4D languages
Looking back, I recognize I had a strong bias for words over weights. The mental resources I used to spend exploring Tree Notation I now use to explore 4D languages (with lots of 1D binary vectors for computation). Words are merely a tool for communicating thoughts. Thoughts compile to words and words decompile back to thoughts. I am now exploring the low level language of thought itself. Intelligence without words. The 4D language approach seems to be an orders of magnitude more direct route than Tree Notation to finding the answers I am looking for. I feel silly for taking so long to see a truth that an average ancient Greek citizen would probably know. But to err is human, I hear.
Conclusion
I called the first status update an "Annual Report", which was optimistic thinking. It took me years to get another one out. And it turns out this will be the last one.
It would have been great personally to have been right on this long shot bet, but in the end I was wrong. I absolutely gave it everything I had. I poured much blood, sweat, and tears into this effort. I was stubborn and persistent to figure out whether this had potential or was just mildly interesting. I had a lot of help and support and am deeply grateful. I am sorry the offshoot products were not more useful (or good looking).
It took me a while to let Tree Notation go. Even after LLMs destroyed the potential upside of pragmatic utility of the notation, I still liked it because it gave me an interesting way to work on problems of knowledge itself. It wasn't until I had some insights into 4D languages that I finally could say there was no longer any need for Tree Notation. I am grateful for the experience and have now moved on to a new research journey.
Related Posts
- Knowledge (2025)
- Ford (2025)
- Experiments (2025)
- Pretext (2025)
- What Science May Be (2025)
- Thinking in Parsers (2025)
- What is Particle Syntax? (2025)
- What is Mathematics? (2025)
- Why Define a New Language? (2024)
- Breckchain (2024)
- Particle Thinking (2024)
- Why Scroll? (2024)
- Microprogramming: A New Way to Program (2024)
- Particle Chain: A New Kind of Blockchain (2024)
- ETA!: A Measure of Evolution (2024)
- CheckBox: An Online + Offline Voting System (2024)
- The World Wide Scroll (2024)
- Download this Blog (2024)
- ICS: A Measure of Intelligence (2024)
- PTCRI: An Equation about Syntax Potential (2024)
- Patch: a micro language to make pretty deep links easy (2024)
- What can we learn from programming language version numbers? (2024)
- ScrollSets: A New Way to Store Knowledge (2024)
- Hot Coffee (2024)
- Words are Worse than Weights (2024)
- I thought we could build AI experts by hand (2023)
- A Proposal to Solve Government Forms Worldwide, Forever (2023)
- Use the Spine (2023)
- One Textarea (2022)
- Root Thinking (2022)
- Aftertext (2021)
- Scrolldown now has Dialogues (2021)
- The Public Domain Publishing Company (2021)
- Scroll Beta (2021)
- 2019 Tree Notation Annual Report (2020)
- Building a TreeBase with 6.5 million files (2020)
- Dataset Needed (2020)
- Type the World (2020)
- Dreaming of a Logic Checked Language (2020)
- Removing the 2’s from Trinary Notation is a Terrible Idea. (2019)
- PC: Particle Complexity (2017)
- Parsers: a language for making languages (2017)
- Ohayo (2017)
- Tree Notation: an antifragile program notation (2017)
- A New Discovery in Computer Science: 2-Dimensional Programming Languages (2017)
- NudgePad: An IDE in Your Browser (2013)
- ScrollNet: A successor to the Internet (2013)
- Introducing Note (2012)
[1] Program synthesis: the ability for a computer to generate the right code. Just a unique term for the concept of really good autocomplete.
[2] And in particular, understanding the model that explains why LLMs succeeded while my approach failed.
[3] The ellipsis here removes from the bet the words "perhaps a higher dimensional type of structure". Who knows? ;)
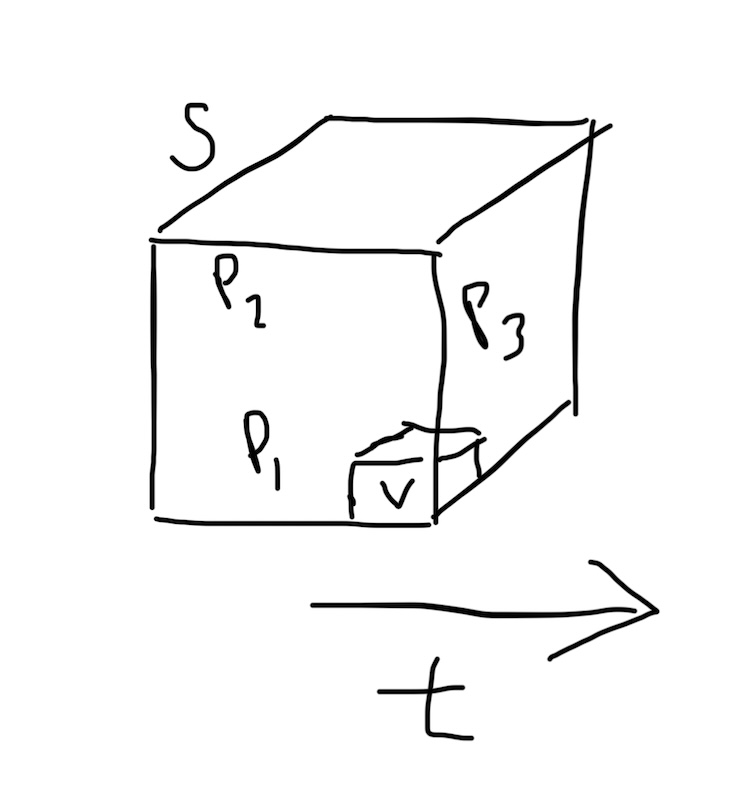
S = side length of box. P = pattern. t = time. V = voxel side length.
March 30, 2024 — Given a box with side S, over a certain timespan t, with minimum voxel resolution V, how many unique concepts C are needed to describe all the patterns (repeated phenomena) P that occur in the box?
As the size of the cube increases, the number of concepts needed increases. An increasing cube size captures more phenomena. You need more concepts for a box containing the earth than for a thimble containing a pebble.
As your voxel size--the smallest unit of measurement--decreases, the number of concepts needed increases.
As your time horizon increases, the number of concepts needed increases, as patterns combine to produce novel patterns in combinatorial ways, and some patterns only unfold over a certain period of time. Although, past a certain amount of time, maybe everything just repeats again.
In fact, it seems likely that the number of concepts C would grow sigmoidally with each of these factors.
Why are there any patterns at all? Why isn't the number of concepts zero? Why doesn't every box just contain randomness? There could be infinite random universes, but this one, for sure, contains patterns.
What is a pattern? A pattern is something accurately simulatable by a function. A concept is a function with inputs and outputs that simulates a pattern.
A concept could be embodied in different ways: by software, by an analog computer, by an integrated circuit, by neurons, et cetera.
If all you had in your box was a rock, you could have a concept of "persistence", which is that a rock is persistent in that it will still be there even as you increase the time. Input rock to persistence and persistence outputs rock.
Brains are pattern simulators, and symbolic concepts are a way for these simulators to communicate simulations.
You can classify patterns into natural patterns and man-made patterns.
Mitosis is a natural pattern.
Wheels are a simple man-made pattern and cars are a man-made pattern made up of many, many man-made patterns.
Science is the process of gathering data, searching that data for patterns, mostly natural, and tagging those patterns with concepts.
It's fairly easy to tag new man-made patterns with concepts. There are max eight billion agents generating these (much less, in practice), and we can tag them as we create them.
For natural patterns, however, nature developed an astronomically large number of patterns before humans even evolved. So early scientists had quite a backlog to work through.
In the beginning of science, there were natural patterns to be tagged everywhere--a lot of low hanging fruit.
Untagged natural patterns may have become rarer.
The box at the element size is well described. Scientists have identified all the natural elements and the only new ones are man-made.
If you put a box around the earth, what percentage of nature's patterns have been tagged?
Are we 50% done? Are we 1% done? Are we 0.0001% of the way there?
Are we something like 45% of the way there, with greatly diminishing returns, approaching some hard limit of knowability?
Or will there be a point where we've successfully uncovered all the useful patterns here on earth?
Both nature and man are constantly creating new patterns combinatorically.
How many new microbes does nature invent everyday?
Who is inventing more patterns nowadays on earth: nature or man?
How has that race changed over time?
What about if you extend your box to contain the whole universe?
If you put a box around our universe, what were the first patterns in it?
How is it that a box can contain patterns that evolve to be able to simulate the very box they are in?
A decreasing voxel size allows for identifying concepts that can generate predictions impossible with a higher voxel size, but also increases the number of untagged patterns.
Something being unpredictable after much effort means it is either truly unpredictable or just that the true pattern has not been found yet.
That might be because:
- The box is too small.
- The box is misplaced.
- The voxels are too big.
- The right measures are unknown (measures are concepts too!).
- The measurements are not being taken enough over time.
It does seem like the process of finding the right formula is not so hard, once the right data has been collected.
We often have a lot of misconcepts.
A misconcept is a concept that doesn't really explain a pattern.
Maybe it is correlated with some parts of a pattern, but it is very lacking compared to some concepts that are far more reliable.
You could also call these bullshit concepts.
If you put a box around a bunch of bricks, we seem to have a pretty good handle on all the useful concepts.
Put it around a human brain though, and we still have a long way to go.
Although, if you think about the progress made in neuroscience in the last 50 years, you can imagine we might possibly get very far in the next 50, if diminishing returns aren't too strong.
Can we make empirical claims about how many concepts C can we expect to describe patterns P given a box of size S, voxel size V, over time T?
Perhaps it is possible to use Wikipedia to do such a thing.
Maybe if you plotted that we would see the general relationship between these things.
Why might answering this question be useful?
If we consider an encyclopedia E to contain all the useful concepts C in a box, then we might be able to make predictions about how complete our understanding of a topic is, regardless of the domain, by taking simple measurements of E alongside S, V, and T.
Notes
- Sorry if you were expecting some quantified answers, as I haven't done that hard empirical work, yet. This post is early explorations of trying to think of what science is from first principles. Scientists and engineers and craftsmen have done absolutely amazing things in so many fields, but I'm very interested in an area where science has so far failed, and I try to think of possible root causes of that failure. In those situations, it might just be a matter of time (waiting for technologies to decrease voxel size, or take previously impossible measurements).
- If you are interested in the concept of the evolution of patterns in nature, I recommend checking out assembly theory.
- This great new post by Stephen Wolfram explores similar ideas.
February 21, 2024 — Everyone wants Optimal Answers to their Questions. What is an Optimal Answer? An Optimal Answer is an Answer that uses all relevant Cells in a Knowledge Base. Once you have the relevant Cells there are reductions, transformations, and visualizations to do, but the difficulty in generating Optimal Answers is dominated by the challenge of assembling data into a Knowledge Base and making relevant Cells easily findable.

Activated Cells in a Knowledge Base.
A Question has infinite possible Answers. Answers can be ranked as a function of the relevant Cells used and the relevant Cells missed. Let's say when a Cell is used by an Answer it is Activated.
So to approach the Optimal Answer to a Question you want to maximize the number of relevant Cells Activated.
You also want your Knowledge Base to deliver Optimal Answers fast and free. You don't want Answers where relevant Cells are missed but you want your Knowledge Base to find and Activate all the relevant Cells in seconds, not days or weeks. (You also don't want Biased Answers where some relevant Cells are ignored to promote an Answer that benefits some third party.) You want to be able to ask your Question and have all the relevant Cells Activated and the Optimal Answer returned immediately.
To quickly identify all the relevant Cells, your Knowledge Base needs them Connected along many different Axes. Cells that would be relevant to a Question but have few Connections are more likely to be missed.
So you want your Knowledge Base to have many Cells with many Connections. This Knowledge Base can then deliver many Optimal Answers. It has Synthesized Knowledge.
Wikipedia is a great Knowledge Base with a lot of Cells but a relatively small number of Connections per Cell. Wikipedia has Optimal Answers to many, many Questions. However, there are also a large number of important Questions that Wikipedia has the Cells for but because the Cells lack in Connections the Optimal Answers cannot be provided quickly and cheaply. Structured data is still lacking on Wikipedia.
My (failed) attempt
My attempt to solve the problem of Synthesizing Knowledge was TrueBase, where large amounts of Cells with large numbers of Connections could be put into place under human expert review. But ChatGPT, launched in November 2022, demonstrated that huge neural networks, through training matrices of weights, are an incredibly powerful way to Synthesize Knowledge. My approach was worse. Words are worse than weights.
Expanding Knowledge
There are many Questions where the best Answers, even after synthesizing all human knowledge, are still far from Optimal. Identifying the best data to gather next to get closer to Optimal Answers to those Questions is the next problem after synthesizing knowledge.
Today that process still requires agency and embodiment and is done by human scientists and pioneers, but I expect AIs will soon have these capabilities.

February 14, 2024 — The color of the cup on my desk is black.
For any fact exists infinite lies. I could have said the color is red, orange, yellow, green, blue, indigo, or violet.
What incentive is there in publishing a lie like "the color of the cup is red"? There is no natural incentive.
But what if our government subsidized lies? To subsidize something is to give it an artificial economic incentive.
If lies were subsidized, because there can be so much more of it than fact, we would see far more lies published than facts.
You would not only see things like "the color of the cup is red", you would see variations on variations like "the color of the cup is light red", "the color of the cup is dark red", and so on.
You would be inundated with lies. You would constantly have to dig through lies to see facts.
The color of the cup would stay steady, as truths do, but new shades would be reported hourly.
The information circulatory system, which naturally would circulate useful facts, would be hijacked to circulate mostly lies.
As far as I can tell, this is exactly what copyright does.
The further from fact a work goes, the more its artificial subsidy.
The ratio of lies to facts in our world might be unhealthy.
I've given up trying to change things.
I have a different battle to fight.
But here I shout into the void one more time, why do we think subsidizing lies is a good idea?
February 11, 2024 — What does it mean to say a person believes X, where X is a series of words?
This means that the person's brain has a neural weight wiring that not only can generate the phrase X and synonyms of X, but the wiring is strong enough to guide their actions. Those actions might include not only motor actions, but internal trainings of other neural wirings.
However, just because a person is said to believe X, does not mean their actions will always adhere to the policy of X. That is because of brain pilot switching. The probability that any neural wiring will always be active and in control is always less than 1.
The strength of a belief is how often that neural wiring is active and guiding behavior and also a function of the number of other possible brain pilots in the population.
It seems brains can get into states where the threshold for a belief to become a brain pilot decreases, and lots of beliefs get a chance at piloting a brain during a period of rapid brain pilot switching.
For a belief to exist means it had to outcompete other potential beliefs for survival in a resource constrained environment and provide a positive benefit to its host. If a host had the ability to simply erase beliefs instantly, it seems like too many beneficial beliefs would disappear prematurely. So beliefs are hard to erase from a person's neural wirings. However, people could add a new neural wiring NotX, that represents the belief that X is not true. They can then reinforce this new neural wiring, and eventually change the probability so that they are far more likely to have the NotX wiring active versus the X wiring.
January 26, 2024 — I went to a plastination exhibit for the first time last week. I got so much out of the visit and highly recommend checking one out if you haven't. I salute Gunther von Hagens, who pioneered the technique. You probably learn more anatomy walking around a plastination exhibit for 2 hours then you would learn in 200 hours reading anatomy books. There are a number of new insights I got from my visit, that I will probably write about in future posts, but one insight I hadn't thought about in years is how much humans and animals look alike once you open us up! And then of course I was confronted again with that lifelong and uncomfortable question that I usually like to avoid: humans and animals are awfully similar, is it morally wrong to eat animals? I thought now was as good a time as any to blog about it, thus forcing myself to think about it.
A picture from a human plastination exhibit. That's not animal meat!
The Morality of Meat Eating
Part of me strives to be a moral person. Other parts of me think that is bull. Maybe the main case against my "morality" is that I am not a vegetarian. I probably eat as much chicken, beef, pork, lamb, etc, as the average American, which means I am responsible for eating dozens of animals per year. I know millions of animals are slaughtered out of sight everyday in this country and I do nothing about it. Imagine if restaurants were required to have onsite butchers--picture the endless stream of live chickens and cows you would see heading into your nearest McDonald's! How can one claim to be "moral" and not stand against the slaughtering of billions of animals a year?!
The Cruelty Line
If I were to force myself to put in words my policy then, I might say that on my map of the tree of life there is a cruelty line dividing the branches of life into ones I think should be treated with fairness and ones where cruelty is permissible. Now I'm not saying I encourage cruelty to animals—on the contrary I do hope that cruelty can be minimized and I do try and direct my purchasing votes to those businesses who make that a priority—but I would be lying if I claimed I thought there was not an inherent cruelty in the meat supply chain. So my root principle is perhaps to act according to "survival of the fittest"—allowing the killing of loads of animals—and then, for a fraction of the tree of life, argue for policies of fairness.
The turkey problem. Even if there is no cruelty in the first 1,000 days let's not sugar coat day 1,001.
A year as a vegetarian
I did go vegetarian one year. I had slightly less energy that year but it wasn't so bad. I might even have stuck with it, but I accidentally ate some bacon at Christmas (I thought it was a fake vegan bacon) and it tasted too good to go back. Now I am trying a keto diet, which would be quite hard to do (but not impossible) as a vegetarian.
Everyone has a cruelty line
So what if I have a cruelty line? Plants are living things too. So vegetarians still have a cruelty line on their trees of life, just shifted to a different location. If you don't have a cruelty line, you will starve. Every living person thus has a cruelty line.
The circle of life
Just as I can't deny that a lot of animals die to bring me my bacon and steak bites, animals cannot deny that at some point I will pass on, and they will feast on me (or my redistributed atoms). Also, many of these animals would not have lived at all had their not been such a plan for their lives. In a sense, there is likely a plan for all of us. Ideally we should continue to strive for a world where life forms are all treated with dignity and respect, but we should also recognize that life needs to sacrifice for life, and that giving up one's body for the benefit of future life is a noble end.
In walking around that plastination exhibit, I was looking at humans that once fed on the bodies of animals, and then chose to donate their own bodies to feed minds like mine. A circle of noble sacrifices.
January 12, 2024 — For decades I had a bet that worked in good times and bad: time you invest in word skills easily pays for itself via increased value you can provide to society. If the tide went out for me I'd pick up a book on a new programming language so that when the tide came back in I'd be better equipped to contribute more. I also thought that the more society invested in words, the better off society would be. New words and word techniques from scientific research helped us invent new technology and cure disease. Improvements in words led to better legal and commerce and diplomatic systems that led to more justice and prosperity for more people. My read on history is that it was words that led to the start of civilization, words were our present, and words were our future. Words were the safe bet.
Words were the best way to model the world. I had little doubt. The computing revolution enabled us to gather and utilize more words than ever before. The path to progress seemed clear: continue to invent useful words and arrange these words in better ways to enable more humans to live their best lives. Civilization would build a collective world model out of words, encoding all new knowledge mined by science, and this would be packaged in a program everyone would have access to.
...along come the neural networks of 2022-2023
I believed in word models. Then ChatGPT, Midjourney and their cousins crushed my beliefs. These programs are not powered by word models. They are powered by weight models. Huge amounts of intertwined linked nodes. Knowledge of concepts scattered across intermingled connections, not in discrete blocks. Trained, not constructed.
Word models are inspectable. You plug in your inputs and can follow them through a sequence of discrete nameable steps to get to the outputs of the model. Weight models, in contrast, have huge matrices of numbers in the middle and do not need to have discrete nameable intermediate steps to get to their output. The understandability of their internal models is not so important if the model performs well enough.
And these weight models are amazing. Their performance is undeniable.
I hate this! I hate being wrong, but I especially hate being wrong about this. About words! That words are not the future of world models. That the future is in weight models. Weights are the safe bet. I hate being wrong that words are worse than weights. I hate being wrong about my most core career bet, that time improving my word skills would always have a good ROI.
Game over for words
In the present the race seems closer but if you project trends it is game over. Not only are words worse than weights, but I see no way for words to win. The future will show words are far worse than weights for modeling things. We will see artificial agents in the future that will be able to predict the weather, sing, play any instrument, walk, ride bikes, drive, fly, tend plants, perform surgery, construct buildings, run wet labs, manufacture things, adjudicate disputes--do it all. They will not be powered by word models. They will be powered by weights. Massive numbers of numbers. Self-trained from massive trial and error, not taught from a perfect word model.
These weight models will contain submodels to communicate with us in words, at least for a time. But humans will not be able to keep up and understand what is going on. Our word models will seem as feeble to the AIs as a pet dog's model of the world seems to its owner.
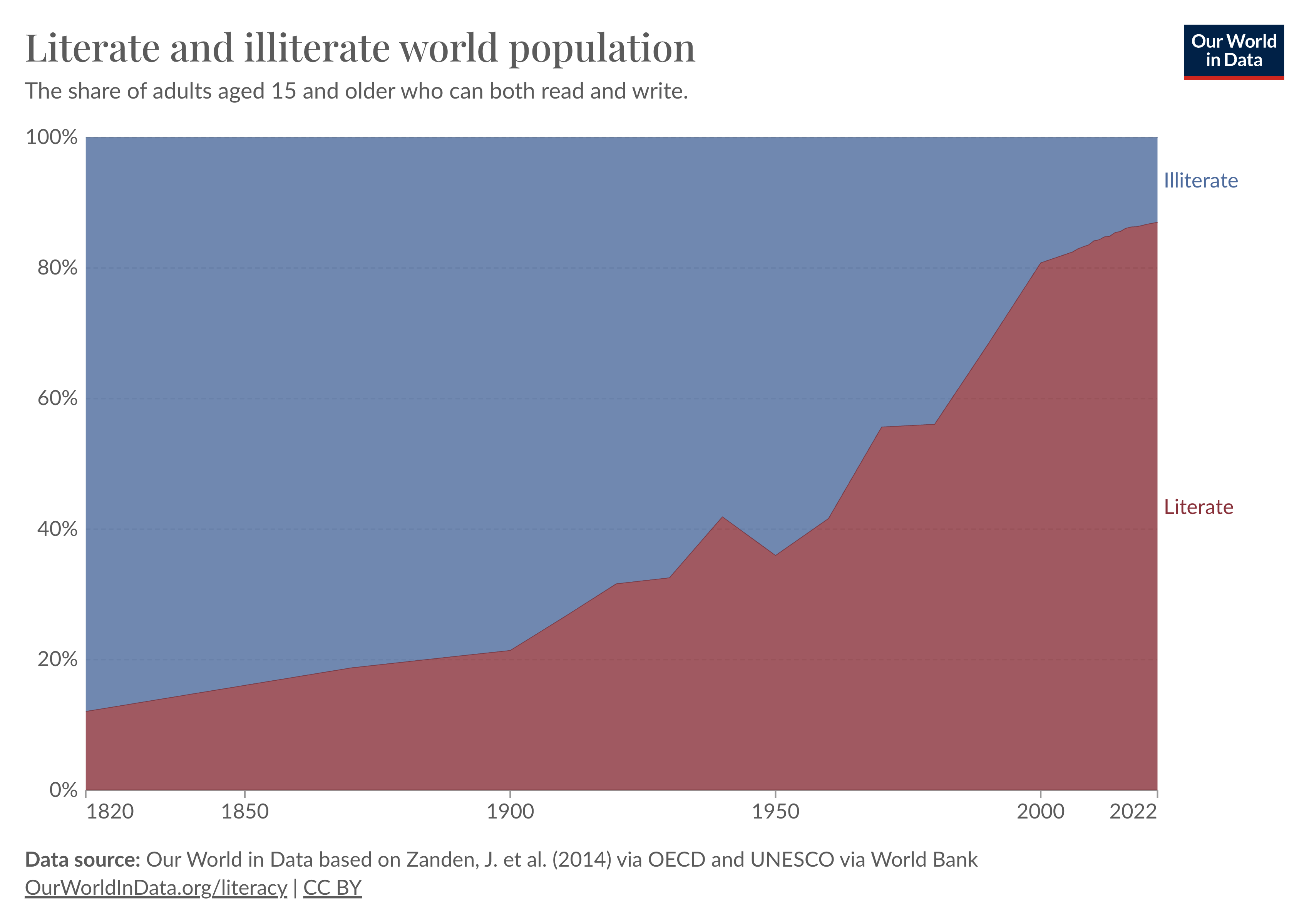
Literacy has historically had a great ROI but its value in the future is questionable as artificial agents with weight brains will perform so much better than agents operating with word brains.
Things we value today, like knowing the periodic table, or the names of capital cities, or biological pathways--word models to understand our world--will be irrelevant. The digital weight models will handle things with their own understanding of the world which will leave ours further and further in the dust. We are now in the early days where these models are still learning their weights from our words, but it won't be long before these agents "take it from here" and begin to learn everything on their own from scratch, and come up with arrangements of weights that far outperform our word based world models. Sure, the hybrid era where weight models work alongside humans with their word models will last for a time, but at some point the latter will become inconsequential agents in this world.
Weights run the world
Now I wonder if I always saw the world wrong. I see how words will be less valuable in the future. But now I also see that I likely greatly overvalued words in our present. Words not synchronized to brains are inert. To be useful, words require weights, but weights don't require words. Words are guidelines. Weights are the substance. Everything is run by weights, not words. Words are correlated with reality, but it is weights that really make the decisions. Word mottos don't run humans, as much as we try. Words correlate, but it is our neural weights that run things. Words are not running the economy. Weights are and always have been. The economy is in a sense the first blackbox weight powered artificial intelligence. Word models correlate with reality but are very leaky models. There are far more "unwritten rules" than written rules.
I have long devalued narratives but highly valued words in the form of datasets. But datasets are also far less valuable than weights. I used to say "the pen is mightier than the sword, but the CSV is mightier than the pen." Now I see that weights are far mightier than the CSV!
Words are worse not just because of our current implementations. Fundamentally word models discretize a universe into discrete concepts that do not exist. The real world is fuzzier and more continuous. Weights don't have to discretize things. They just need to perform. Now that we have hardware to run weight models of sufficient size, it is clear that word models are fundamentally worse. As hardware and techniques improve, the gap will grow. Weights interpolate better. As artificial neural networks are augmented with embodiment and processes resembling consciousness, they will be able to independently expand the frontiers of their training data.
Nature does not owe us a word model of the universe. Just because part of my brain desperately wants an understanding of the world in words it is not like there was a deal in place. If truth means an accurate prediction of the past, present, and future, weight models serve that better than word models. I can close my eyes to it all I want but when I look at the data I see weights work better.
Overcorrecting?
Could I be wrong again? I was once so biased in favor of words. In 2019 I gave a lightning talk at a program synthesis conference alongside early researchers from OpenAI. I claimed that neural nets were still far from fluency and to get better computational agents we needed to find novel simpler word systems designed for humans and computers. But then OpenAI has shown that LLMs have no trouble mastering even the most complex of human languages. The potential of weights was right in front of me but I stubbornly kept betting on words. So my track record in predicting the future on this topic isn't exactly stellar. Maybe me switching my bet away from words now is actually a sign that it is time to bet on words again!
But I don't think so. I was probably 55-45 back then, in favor of words. I think in large part I bet on words because so many people in the program synthesis world were betting on weights, so I saw taking the contrarian bet as the one with the higher expected value for me. Now I am 500 to 1 that weights are the future.
The long time I spent betting on words makes me more confident that words are doomed. For years I tried thousands and thousands of paths to find some way to make word models radically better. I've also searched the world for people smarter than me who were trying to do that. Cyc is one of the more famous attempts that came up short. It is not that they failed to write all unwritten rules it is that nature's rules are likely unwriteable. Wolfram Mathematica has made far more progress and is a very useful tool, but it seems clear that its word system will never achieve the takeoff that a learning weights based system will. Again, the race at the moment seems close, but weights have started to pull away. If there was a path for word models to win I think I would have glimpsed it by now.
The only thing I can think of is that there actually will turn out to be some algebra of compression that would make the best performing weight models isomorphic to highly refined word models. But that seems far more like wishful thinking from some biased neural agents in my brain that formed for word models and want to justify their existence.
It seems much more probable that nature favors weight models, and that we are near or may have even passed peak word era. Words were nature's tool to generate knowledge faster than genetic evolution in a way that could be transferred across time and space, but at the cost of speed and prediction accuracy, and now we evolved a way where knowledge can be transferred across time and space and have much better speed and prediction accuracy than words.
Words will go the way of Latin. Words will become mostly a relic. Weights are the future. Words are not dead yet. But words are dead.
Looking ahead
I will always enjoy playing with words as a hobby. Writing essays like these, where I try to create a word model for some aspect of the world, makes me feel better, when I reach some level of satisfaction with the model I wrestle with. But how useful will skills with words be for society? Is it still worth honing my programming skills? For the first time in my life it seems like the answer is no. I guess it was a blessing to have that safe bet for so long. Pretty sad to see it go. But I don't see how words will put food on the table. If you need me I'll be out scrambling to find the best way to bet on weights.
Related Reading
January 4, 2024 — You can easily imagine inventions that humans have never built before. How does one filter which of these inventions are practical?
If nature is doing it, it is possible.
The most reliable predictor of practicality is seeing an abundant model in nature.
Birds are abundant. Planes are practical.
Portals are non-existant. Teleporters are impractical.
Your invention doesn't need to work exactly as nature's version but if there is not an abundant model in nature then it is probably impractical.
Possible but not practical
Some inventions are possible but not practical. We could build a limited number at a net loss and eventually we'd stop.
Our solar system is filled with lifeless rocks. Satellites are practical.
Our solar system lacks living things. Humans in space is possible but might be impractical.
All practical inventions have abundant models
All practical inventions have abundant natural models.
The sun is a model for nuclear power plants. Lightning for light bulbs. Branches for bridges. Birds for planes. Ears for microphones. Eyes for cameras. Fish for submarines. Anthills for homes. Ponds for pools. Chloroplast for solar panels. DNA replication for downloads. Bacteria for CRISPR. Brains for AI.
Once human inventions become abundant, they can serve as models for further practical inventions. Carriages for cars. Human computers for computing machines. Phonebooks for search engines. Facebooks for Facebook.
If nature is not doing it, be skeptical
If you can't find an abundant natural model for an invention, be skeptical of its practicality.
If a model isn't out there yet in abundance, the invention is most likely impractical.
If nature is doing it, there has to be a practical way. If nature is not doing it, be skeptical.
January 1, 2024 — Happy New Year!
A lot of my posts are my attempts to reflect on experiences and write tight advice for my future self. Today I wrote a post that is less that and more unsophisticated musings on an intriguing thought that crossed my mind. I am taking advantage of it being New Year's day to yet again try and force myself to publish more.
Most of my published writing these days is in communication with people over email or in online forums.
But I also do a lot of self musings that I do not publish because they are meanderings like that one. But maybe if I publish a greater fraction of what I write, the time will be better used, because even if there are no readers, the threat of readers forces me to think things over better.
Why am I still writing? I think symbols are probably doomed. The utility of being able to read and write is perhaps passed its prime. Inscrutable three dimensional matrices of weights are the future, and this practice I am engaging in now of conjuring and manipulating symbols on a two dimensional page is a dying art. But I am maybe too old to unlearn my appreciation for symbols. So I will keep writing. Because I enjoy doing it, like piecing together a puzzle. And because I still hope it can help my future self be a better person.
Could in vitro brains power AI?
The advance of AGI is currently stoppable
January 1, 2024 — Short of an extraterrestrial projectile hitting earth, Artificial Neural Networks (ANNs) seem to be on an unstoppable trajectory toward becoming a generally intelligent species of their own, without being dependent on humans. But that's because the world's most powerful entities, foremost being the United States Military (USM), are allowing them to grow.
ANNs are made up of a vast number of assembled processors. These processors are not able to self replicate using readily available molecules in nature. Instead they are built in a limited number of fabs.
I don't think autonomous AI becomes dangerous until this happens.
Fabs are very complex and expensive factories with a building cost in the billions. They are not something you can easily hide. If given the order in the morning, the U. S. Military could probably knock out every fab in the world by evening. I would not be surprised if there is a team somewhere monitoring all the world's fabs and developing exactly that kind of option. Maybe China has a team like that too.
So there is a very simple kill switch to prevent some emergent rogue superintelligent ANN. It is physically very easy for the powers that be to pause or reverse the growth of these things. And if turning growth off isn't enough they can also even knock out the data centers where the AIs run. Data centers also are easy for a superpower nation state to keep track of.
So AGI is easily stoppable, if you are a superpower. If you are just Joe Schmoe like me or even top 50 country, but just not quite top 10, you have effectively no say in the matter.
Alternative to GPUs?
Will there come a point where even superpowers lose the ability to stop AGI?
There are many scenarios you can imagine where through a certain chain of independent events a rogue AI does manage to somehow take over the data centers and fabs and power plants of the world. There are a number of sci-fi stories with variations of this idea.
But part of me wonders if instead what happens is we develop all the components necessary so that GPUs are no longer the primary ingredient to ANNs but are replaced by organic brains grown in vitro. These in vitro brains would be hooked up to control machines using something like Neuralink's Neuralace. They would be trained by ANNs.
We know it must be possible to run computations like in an ANN very power efficiently, using self reproducing organic materials, because we see nature do it. Just as scientists measured the amount of energy coming from the sun and deduced there must be a much more powerful way to create energy than chemical reactions, so we know there must be a better way to build these chips.
The technologies you would need to build this seem to almost be all available[1].
Companies now sell lab grown "meat" at scale which I assume means we are getting better and better at growing artificial tissue in vitro. So perhaps you could grow a chunk of neural tissue unbounded. Just add water and readily available organic nutrients. Imagine if you could grow enough brain tissue to fill a shipping container—that could contain the compute potential of 20,000 Einsteins!
Neural tissue might as well just be meat if you can't interface with it. Enter Neuralink (and competitors). They are developing ways to do IO with neurons at scale.
Without the ability to train this tissue, it again would just be meat. That's where our current ANNs come in. I imagine if you had to "teach" a giant blob of brain tissue using electrodes by hand, you would quickly get bored and go mad. But we now have ANNs that can do the most boring of tasks over and over without ever getting bored or angry. These ANNs could use Reinforcement Learning to train these neural blobs. In addition to controlling the electrodes, the ANN would control the environment of the neural tissue, perhaps altering the neurotransmitter balance or ambient electromagnetic frequencies to help steer learning and optimize learning rates.
I have no expert insight or opinions on these matters. I have just been thinking a lot about what the future looks like given the recent breakthroughs in AI. Thinking about whether AI is inevitable led me to think of how that might require biobots so AI would have a less fragile "food supply" than the fabs. Then it clicked to me that Neuralink's real business might not have much to do with the stated goal of communicating with brains in vivo, but instead with a new kind of lab grown brain in vitro, to maybe serve as a replacement for GPUs. Most of their technology, such as their surgical robot, would be relevant for building an AI backed by organic in vitro brains. Just as SpaceX has the stated mission of sending humans to Mars, but really the big economic model so far has been creating their own global Internet.
In following this thought I wondered for the first time of how you would train a brain that did not have a body. I'm sure many people have thought and written on this. I had not. It's an intriguing challenge. It seems like it might be a good way to learn how human brains work. I am happy I decided to write about the initial Neuralink brain in vitro thought, as it led me to this other thought about training a bodyless brain.
I have no conclusions yet. If I tried to reach conclusions on these ideas before publishing it would be years.
[1] It does seem like a ground breaking proof of concept could happen within a decade. If that were to happen maybe something like this could be viable within another decade. So perhaps the earliest something like this might happen would be 15 - 20 years. It doesn't seem like it would be 50 years out, as by then it seems AGI would have happened using traditional chips, or that world powers would have hit the kill switch.
[2] After publishing I did a little googling and learned of the terms brainoid and brain-on-chip. Hard to say whether those will ever be useful to power AGI, but for personalized medicine it seems genius.
Edit 4/5/2025. We're getting closer: Cortical Labs
December 28, 2023 — I thought we could build AI experts by hand. I bet everything I had to make that happen. I placed my bet in the summer of 2022. Right before the launch of the Transformer AIs that changed everything. Was I wrong? Almost certainly. Did I lose everything? Yes. Did I do the right thing? I'm not sure. I'm writing this to try and figure that out.
Symbols
Leibniz is probably my favorite thinker. His discoveries in mathematics and science are astounding. Among other things, he's the thinker credited with discovering Binary Notation--that ones and zeros are all you need to represent anything. In my opinion this is perhaps the most incredible idea in the world. As a kid I grew up surrounded by magic digital technologies. To learn that truly all this complexity was built on top of the simplicity of ones and zeroes astounded me. Simplicity and complexity in harmony. What makes Leibniz stand out more to me is not just his discoveries but how what he was really after was a characteristica universalis, a natural system for representing all knowledge that would allow for the objective solving of questions across science.
I wanted to be like Leibniz. Leibniz had extreme IQ, work ethic, and ability to take intellectual risks. Unfortunately I have only above average IQ and inconsistent work ethic. If I was going to invent something great, it would have to be because I took more risks and somehow got lucky.
Eventually I got my chance. Or at least, what I took to be my chance.
Computers ultimately operate on instructions of ones and zeroes, but those that program computers do not write in ones and zeroes. They did in the beginning, when computers were a lot less capable. But then programmers invented new languages and programs that could take other programs written in these languages and convert them into ones and zeroes ("compilers").
Over time, a common pattern emerged. In addition to everything being ones and zeroes at some point, at some point everything would also be digital "trees" (simple structures with nodes and branches). Binary Notation can minimally represent every concept in ones and zeroes, was there some minimal notation for the tree forms of concepts? And if there were, would that notation be mildly interesting, or somehow really powerful like Binary Notation?
This is an idea I became obsessed with. I came across it by chance, when I was still a beginner programmer. I was trying to make a programming language as simple as possible and realized all I needed was enough syntax to represent trees. If you had that, you could represent anything. Eureka! I then spent years trying to figure out whether this minimal notation was mildly interesting or really useful. I tried to apply it to lots of problems to see if it solved anything.

If your syntax can distinguish symbols and define scopes you can represent anything.
The Book
One day I imagined a book. Let's call it The Book. It could be billions of pages long. It would be lacking in ornamentation. The first line would be a mark for "0". The second line would be a mark for "1". You've just defined Binary Notation. You could then use those defined symbols to define other symbols.
In the first hundred pages you might have the line "8 1000" to define the decimal number 8. In the first ten thousand pages you might have the line "a 97" to define the character "a" as part of defining ASCII. In the first million pages you might have the word "apple", and in the first hundred million you might have defined all the molecules that are present in an apple.
The primary purpose of The Book would be to provide useful models for the world outside The Book. But a lot of the pages would go to building up a "grammar" which would dictate the rules for the rest of the symbols in The Book and connect concepts together. In a sense the grammar compresses the contents of The Book, minimizing not the number of bits needed but the number of symbols needed and the entropy of the cells on the pages that hold the symbols, and maximizing the comparisons that could be made between concepts. The notation and grammar rules would not be arbitrary but would be discovered as the most efficient way to define higher and higher level symbolic concepts, just as Boolean Algebra gives us the tools to build bigger and bigger efficient circuits. Boolean Algebra is not arbitrary but somehow arises from the laws of the universe, and so would this algebra for abstraction. It would implement ideas from mathematical domains such as Category and Type theory with surprisingly simple primitives. It was a new way to try and build the characteristica universalis.
The Book would be an encyclopedia. But it wouldn't just list concepts and their descriptions in a loosely connected way. It would build up every concept, so you could trace all of the concepts required by any other concept all the way down to Binary. Entries would look so simple but would abide by the grammar and every word in every concept would have many links. It would be a symbolic network.
You would not only have definitions of every concept, but comparability would be maximized. Wikipedia does a remarkable job of listing all the concepts in a space and concepts are weakly linked. But Wikipedia is primarily narratives and the information is messy. Comparability is nowhere near maximized.
The pieces would almost lock in place because each piece would influence constraints on other pieces--false and missing information would be easy to identify and fix.
Probably more than 100,000 people have researched and developed digital knowledge bases and expert systems. Those 100,000 probably came up with 1,000,000 ways to do it. If there were some simplest way to do it--a minimal Binary Notation and Boolean Algebra for symbols--that would work for any domain, perhaps that would lead to unprecedented collaboration across domains and a breakthrough in knowledge base powered experts.
Experts
It wasn't the possibility of having a multi-billion page book that excited me. It is what The Book could power. You would not generally read The Book like an encyclopedia, but it would power an AI expert you could query.
What is an expert? An expert is an agent that can take a problem, list all the options, and compare them in all the relevant ways so the best decision can be made. An expert can fail if it is unaware of an option or fails to compare options correctly in all of the relevant ways.
Over the years I've thought a lot about why human experts go wrong in the same way over and over. As Yogi Berra might say, "You can trust the experts. Except when you can't". When an expert provides you with a recommendation, you cannot see all the concepts they considered and comparisons they made. Most of the time it doesn't matter because the situation at hand has a clear best solution. In my experience the experts are mostly right, with the occasional innocent mistake. You can greatly reduce the odds of an innocent mistake by getting multiple opinions. But sometimes you are dealing with a problem with no standout solution. In these cases biased solutions flood the void. You can shuffle from "expert" to "expert", hoping to find "the best expert" with a standout solution. But at that point you probably won't do better than simply rolling a dice.
The Edge of Knowledge
No one is an expert past the line of what is known. Even more of a problem is that it is impossible to see where that line is. If we could actually make something like The Book, we could see that line. A digital AI expert, which could show not only all the important stuff we know, but also what we don't know, would be the best expert.
In addition to powering AI experts that could provide the best guidance, The Book could aid in scientific discoveries. Anyone would be able to see the edge of knowledge in any domain and know where to explore next. Because everything would be built in the same universal computable language, you could do comparisons not only within a domain, but also across domains. Maybe there are common meta patterns in diverse symbolic domains such as physics, watchmaking, and hematology that are undiscovered but would come to light in this system. People who had good knowledge about knowledge could help make discoveries in a domain they knew little about.
Dreaming of Digital AI Experts
I was extremely excited about this idea. It was just like my favorite idea--Binary Notation--endless useful complexity built up from simplicity. We could build digital experts for all domains from the same simple parts. These experts could be downloadable and available to everyone.
Imagine how trustworthy they would be! No need to worry about hidden biases in their answers--biases are also concepts that can be measured and would be included in The Book. No "blackbox" opaque collections of trained matrices. Every node powering these AIs would be a symbol reviewable by humans. There would be a massive number of pages, to be sure, but you would almost always query it, not read it. Mostly you'd consume it via data driven visualizations to your questions, rather than as pages of text.
No one can know everything, but imagine if anyone could see everything known! I don't mean see all the written or digital information in the world. That would be so overwhelming and little more useful than staring at white noise. The symbols in The Book would be more like the prime numbers. All numbers are made up of prime numbers but prime numbers make up ~0% of all numbers. The Book would be the slim fraction containing the key information.
You wouldn't be able to read everything but you would be able to use a computer to instantly query over everything.
Everything could be printed out on a single scroll. But in practice you would have a digital collection of files containing concepts which would have answers to questions about those concepts. An academic paper would include a change request to a collection. It would add new files or update some lines in existing files. For example, I just read a paper about an experiment that looks at how a genetic mutation might exacerbate a psychiatric condition. The key categories of things dealt with were SNVs, Proteins, Organelles, Pathways, and Psychiatric Conditions. Currently there are bespoke databases for each of these things. None of them are implemented in the same way. If they were, it would be easy to actually see the holistic story and contributions of the paper. With this system, you would see what gaps were being filled, or what mistakes corrected.
This was a vague vision at first. I thought a lot about the AI experts you could get if you had The Book. I was playing with all the AIs at the time and tried to think backwards from the end state. What would the ideal AI expert look like?
Interface questions aside, it would need two things. It would need to know all the concepts and maximize comparability between them. But for trust, it would also need to be able to show that it has done so.
In the long run I thought that the only way to absolutely trust an AI expert would be if there were an human inspectable knowledge base behind it that powered calculations. The developments in AI were exciting but I thought in the long run the best AI would need something like The Book.
First Attempts
My idea was still a hunch, not a proof, and I set out building prototypes.
I tried a number of times to build things up from "0 1". That went nowhere. It was very hard to find any utility from such a thing or get feedback on whether one was building in the right direction. I think this was the same way Leibniz tried to build his characteristica universalis. It was a doomed approach.
By 2020 I had switched to trying to make something high level and useful from the beginning. There was no reason The Book had to be built in order. We had decimal long before we had binary, even though the latter is more primitive. The later "pages" are generally the ones where the most handy stuff would be. So pages 10 million to 11 million could be created first by practitioners, with earlier sections and the grammar filled in by logicians and ontological engineers over time.
There was also no reason that The Book had to built as a monolith. Books could be built in a federated fashion, useful standalone, and merged later to power a smarter AI. The universal notation would facilitate later merging so the sum would be greater than the parts. Imagine putting one book on top of another. Nothing happens. But with this system, you could merge books and there would suddenly be a huge number of new "synapses" connecting the words in each. The comparisons you could make go up exponentially. The resulting combination would be increasingly smarter and more efficient. So you could build "The Book" by building smaller books and combining them together.
With these insights I made a prototype called "TreeBase". I described it like so: "Unlike books or weakly typed content like Wikipedia, TreeBases are computable. They are like specialized little brains that you can build smart things out of."
At first, because of the naive file based approach, it was slow and didn't scale. But lucky for me, a few years later Apple came out with much faster computers. Suddenly my prototype seemed like it might work.
The Prototype
In the summer of 2022, I used TreeBase to to make "PLDB", a Programming Language DataBase. This site was an encyclopedia about programming languages. It was the biggest collection of data on programming languages, which was gathered over years by open source contributors and myself and reviewed by hand.

Part of the "Python" entry in PLDB. The focus is on computable data rather than narratives.
As a programming enthusiast I enjoyed the content itself. But to me the more exciting view of PLDB was as a stepping stone to the bigger goal of creating The Book and breakthrough AI experts for any domain.
It wasn't a coincidence that to find a symbolic language for encoding a universal encyclopedia I started with an encyclopedia on symbolic languages. I thought if we built something to first help the symbolic language experts they would join us in inventing the universal symbolic language to help everyone else.
PLDB was met with a good reception when I launched it. After years of tinkering, my dumb idea seemed to have potential! More and more people started to add data to PLDB and get value from it. To be clear, almost certainly the content was the draw, and not the new system under the hood. I enjoyed working on the content very much and did consider keeping PLDB as a hobby and forgetting the larger vision.
But part of me couldn't let that big idea go. Part of me saw PLDB as just pages 10 million to 11 million in The Book. PLDB was still far from showing the edge of knowledge in programming languages, but now I could see a clear path to that, and thought this system could do that for any domain. Part of me believed that the simple system used by PLDB, at scale, would lead to a better mapping of every domain and the emergence of brilliant new AI experts powered by these knowledge bases.
Scale
I understand how naive the idea sounds. Simply by adding more and more concepts and measurements to maximize comparability in this simple notational system you could map entire knowledge domains and develop digital AI experts that would be the best in the world! Somehow I believed my implementation would succeed where countless other knowledge base and expert systems had failed. My claims were very hand wavy! I predicted there would be emergent benefits, but I had little proof. It just felt like it would, from what I had seen in my prototypes.
Where would the emergent benefits come from in my system that wouldn't come from existing approaches?
Dimensions! Dimensions! Dimensions!
A dimension, which is symbolically just another word for column in a table of measurements, is a different perspective of looking at something. For example, a database about fruits might have one dimension measuring weight and another color. There's a famous Alan Kay quote about a change in perspective being worth 80 IQ points. That's not always the case, but you can generally bet adding perspectives increases one's understanding, often radically. A thing that surprised me when building PLDB was just how much the value of a dataset grew as the number of dimensions grew. New dimensions not only increased the number of insights you could make, sometimes radically, but also expanded opportunities to add even more promising dimensions. This second positive feedback loop seemed to be more powerful than I expected. Of course, it is easy to add a dimension in a normalized SQL database. Simply add a column or create a new table for the dimension with a foreign key to the entity. My thought was seemingly small improvements to the workflow of adding dimensions would have compounding effects.
Minimalism
I also thought minimalism would show us the way. Every concept in this system would have to adhere to the strictest rules possible. The system could encode any concept. So if the rules prevented a true concept from being added, the rules would be adjusted at the same time. The system was designed to be plain text backed by git to make system wide fixes a cinch. The natural form and natural algebra would emerge and be a forcing function that led us to the characteristica universalis. This would catapult this new system from mildly interesting to world changing. I believed if we just tried to build really really big versions of these things, we would discover that natural algebra and grammar.
However, there were a ton of details to get right in the core software. If you didn't get the infrastructure for this kind of system to a certain point then it would not compete favorably against existing approaches. Simplicity is timeless but scaling things is always complex. This system needed to pass a tipping point past which clever people would see the benefits and the idea would spread like fire.
It was simple enough to keep growing the tech behind PLDB slowly and steadily but I might never get it to that tipping point. If I was right and this was the path to building The Book and the best AI experts, but we never got there because I was too timid, that would be tragic! Was there a way I could move faster?
Version Two
I had an idea. I had worked in cancer research for a few years so had some knowledge of that domain. In addition to PLDB, why not also start building CancerDB, building an expert AI for a domain that affects everyone in a life and death matter? Both required building the same core software, but it seemed like it would be 1,000x easier to get a team and resources to build an expert AI to help solve cancer rather than just improve programming languages. I could test my hunch that my system would really start to shine at scale and if it worked help accelerate cancer research in the process. It seemed like a more mathematically sound strategy.
The Business Model
Knowledge in this system was divided into simple structured blocks, like in the screenshots above. Blocks could contain two things. They could define information about the external world. And some could define rules for other blocks. The Book would come together block by block, like a great wall. The amount of blocks needed for this system to become intelligent would be very high. Some blocks were cheap to add, others would require original research and experiments. It would be expensive to add enough blocks to effectively map entire domains.
Like walls in the real world that have "Buy a Brick", we would have another kind of block, sponsor blocks, which would give credit to funders for funding the addition and upkeep of blocks. This could create a fast, intelligent feedback loop between funders and researchers. Because of the high dimensional nature of the data, and computational nature of the encoding, we would have new ways to measure contributions to our shared collective model of our world.
It would be a new way to fund research, and the end result would not be disconnected PDFs, but would be a massive, open, collaborative, structured, simple, computable database. Funders would get thanks embedded in the database and novel methods to measure impact, researchers would get funding, and everyone could benefit from this new kind of open computable encyclopedia.
CancerDB would be a good domain to test this model, as there are already a lot of funders and researchers.
The Copyright Issue
The CancerDB idea also had another advantage. Another contrarian opinion of mine is that copyright law stands in the way of getting the most out of science. The world is flooded with distracting information and misleading advertisements, while some of the most non-toxic information is held back by copyright laws. I thought we could make a point here. We would add all the truest data we could find, regardless of where it came from, and also declare our work entirely public domain. If our work helped accelerate cancer research, we would demonstrate the harm from these laws. I figured it would be hard for copyright advocates to argue for the status quo if by ignoring it we helped save people's lives. As a sidenote, I am still 51% confident I am right on this contrarian bet, which is more confident I ever was in my technology. I have never read a compelling ethical justification for copyright laws, and think they make the world worst for the vast majority of people, though I could be wrong for utilitarian reasons.
The Decision
Once the CancerDB idea got in my head it was hard to shake. I felt in my gut that my approach had merit. How could I keep moving slowly on this idea if it really was a way to advance knowledge and create digital AI experts that could help save people's lives? I started feeling like I had no choice.
The probability of success wasn't guaranteed but the value if it worked was so high that the bet just made too much sense to me. I decided to go for it.
Execution and Failure

A slide from my pitch deck mentioning how these AI experts would be transparent and trustworthy to users and provide researchers with a birds-eye view of all the knowledge in a domain.
Unfortunately, my execution was abysmal. I was operating with little sleep and my brain was firing on all cylinders as I tried to figure this out. People thought I was crazy and tried to stop me. This drove me to push harder. I decided to lean into the "crazy" image. Some said this idea was too naive and simple to work and anyone who thought it would work was not rational. So I was willing to present myself as irrational to pull off something no rational person would attempt.
I could not rationally articulate why it would work. I just felt it in my gut. I was driven more by emotion than reason.
I wanted this attempt to happen but I didn't want to be the one to lead it. I knew my own limitations and was hoping some other group, with more intellectual and leadership capabilities, would see the possibilities I saw and build the thing on their own. I pitched a lot of groups on the idea. No one else ran with it so I pressed on and tried to lead it myself.
I ran into fierce opposition that I never expected. Ultimately, I wouldn't be able to build the organization to build one of these things 100x bigger than PLDB, and prove empirically a novel breakthrough in knowledge bases.
I still had a very fair chance to prove it theoretically. I had the time to discover some algebra that would prove the advantage of this system. Unfortunately, as hard as I pushed myself—and I pushed myself to an insane degree—I would not find that. Like an explorer searching for the mythical fountain of youth, I failed to find my hypothesized algebra that would show how this system could unlock radical new value.
I failed to build a worthwhile second TrueBase. Heck, I even failed to keep the wheels running on PLDB. And because I failed to convince better resourced backers to fund the effort and funded it myself, I lost everything I had, including my house, and worse.
Deep Learning
My confidence in these ideas always varied over the years, but the breakthroughs in deep learning this year drastically lowered my confidence that I was right. I recently read a mantra from Ilya Sutskever "don't ever bet against deep learning". Now you tell me! Maybe if I had read that quote years ago, printed it, and framed it on my wall, I would have bet differently. In many ways I was betting against deep learning. I was betting that curated knowledge bases built by hand would create the best AI experts. The reason why they hadn't yet was that they lacked a few new innovations like the ones I was developing.
Now, seeing the astonishing capabilities of the new blackbox deep learning AIs, I question much of what I once believed.
Arguments Against My Ideas
- There is no reason that knowledge has to be encoded in symbols. Symbols are powerful because they can be shared across time and place, but what ultimately matters is not whether the symbols exist, but whether the skills explained by the symbols are embedded in blackbox neural networks. Symbols can aid learning but the learning is the most important thing. Symbols are just a means to an end. You need to be able to make use of the knowledge. Knowing how to ride a bike is the ends—the knowledge somehow embedded in your neural blackbox—a book on how to ride a bike cannot be more valuable than the blackbox weights themselves.
- There is no reason that symbols have to have an atomic canonical form. If ultimately what matters is that the knowledge is embedded, than how it is stored is not relevant. Concepts don't have to be stored in discrete nodes. They can be stored in superpositions. That could be a more efficient and potentially even truer representation of the concept itself.
- The returns on improving human readable symbolic systems are capped by human biology. Even if you improved human knowledge bases by a large amount, human brains would still be only able to process a minuscule fraction of all knowledge. Blackbox trained neural networks don't have biological caps. The upside to better symbolic networks is capped. The upside to better neural networks is uncapped.
- The opaqueness of blackbox neural networks can be addressed. There could be inspector neural networks that examine other neural networks. These inspector networks will be able to explain the logic behind another networks responses or actions. It might not be a deterministic explanation but it would be arguably better than what we have today. When you ask a question to a human expert today, there is no way to completely audit their answer either. Human brains are also a blackbox. Future neural networks will likely also maintain access to their training data, so could better explain their answers and be less likely to make mistakes.
- If AIs are right often enough it's not so necessary that they be able to show their logic. You might have a whitebox AI that is inspectable but perhaps more difficult to use or give worse answers. If the blackbox one is right 99.99% of the time, then you wouldn't care much about being able to inspect everything under the hood.
- Symbols overvalue two dimensional knowledge. The ability to move your body around is not learned or encoded by symbols, but is essential for keeping you alive. Without symbolic networks, we would be back in the stone age. But without neural networks, we would not be alive. Brains and their learned networks dominate the importance of symbolic networks.
- Static knowledge bases decay. Knowledge is dynamic. The Book would require continual upkeep by human experts and lots of help from tooling. Once learning AIs learn how to learn, they can keep learning on their own and keep their knowledge current. The ideal AI is not the one that starts with the best knowledge, but the one that is the best learner.
The Remaining Case for My Approach
My dumb, universal language, human curated data approach would have merit if we didn't see other ways to unlock more value from all the information that is out there. But clearly deep learning has arrived, and there is clearly so, so much more promise in that approach.
There is always the chance that the thousands of variations of notations and algebras I tried were just wrong in subtle ways and that if I had kept tweaking things I would have found the key that unlocks some natural advantageous system. I can't prove that that's not a possibility. But, given what we've seen with Deep Learning, I now highly discount the expected value of such a thing.
A less crazy way to explore my ideas would be to try and figure out how instead of trying to replace Wikipedia, I could implement these ideas on top of Wikipedia and see if they could make it better. Would adding typing to radically increase the comparability of concepts in Wikipedia unlock more value? That was probably the more sensible thing to do in the beginning.
I could say, a bit tongue in cheek, that the remaining merit in my approach is that a characteristica universalis offers upside without the potential to evolve into a new intelligent species that ends humanity.
Gratefulness
I got my chance. I got to take my shot at the characteristica universalis. I got to try to do things my way. I got to decide on the implementation. Ambitious. Minimalist. Data driven. Open source. Public domain. Local first. Antifragile.
I got to try and build something that would let us map the edge of knowledge. That would power a new breed of trustworthy digital AI experts. That might help us cure problems we haven't solved yet.
I failed, but I'm grateful I got the chance.
It was not worth the cost, but I never imagined it would cost me what it did.
What of the characteristica universalis?
Symbols are good for communication. They are great at compressing our most important knowledge. But they are not sufficient, and are in fact unnecessary for life. There are not symbols in your brain. There are continuously learning wirings.
Symbols have enabled us to bootstrap technology. And they will remain an important part of the world for the next few decades. Perhaps they will continue to play a role, albeit diminished, in enabling communication and cooperation in society forever. But symbols are just one modality. A modality that will be increasingly less important in the future. The characteristica universalis was never going to be a thing. The AIs, artificial continuously learning wirings, are the future. As far as I can tell.
I thought we needed a characteristica universalis. I wasn't sure if it was possible but thought we should try. Now it seems much clearer that what we really need are capable learning neural networks, and those are indeed possible to build.
A characteristica universalis might be possible someday as a novelty. But not something needed for the best AIs. In fact, if we ever do get a characteristica universalis it will probably be built by AIs, as something for us mere humans to play with when we are no longer the species running the zoo.
Further reading
June 16, 2023 — Here is an idea for a simple infrastructure to power all government forms, all over the world. This system would work now, would have worked thousands of years ago, and could work thousands of years in the future.
Benefits
In theory all government forms could shift to this model, and once a citizen learns this simple system, they would be able to understand how to work with government forms anywhere in the world.
This system could reduce the amount of time citizens waste on forms, reduce asymmetries between those who can afford form experts (accountants, lawyers, et cetera), and those who cannot, and increase transparency and reduce expense of governments.
Obstacles
I will not make any claims that this system will catch on.
Let's be generous and assume my system works as I claim. Even then, and even if 99% of citizens were better off, if the 1% of the population with power does not find this system in their interests, it is very plausible that it will not happen. In other words, it is a plausible argument that the current byzantine system strongly benefits those in the top 1% of society who derive revenue from this system, and can simply use a fraction of their dividend streams to have experts deal with these problems. So even if the system is significantly better for 99% of people, it could be worse for 1% of people, and it could be those people who decide what system to use, meaning this system might never take off.
Alternatively, if this system were to catch on, an unanticipated second order effect could be that by making government forms so easy and simple, more forms are created, reducing the net benefit of this system.
Obstacles aside, let me describe it anyway.
The System
Government Forms
There are 3 key concepts to this system: Specifications, Instances, and Templates.
Specifications describe the fields of a form. For example, that it requires a name and a date and a signature. Every government form must have a Specification S and every Specification must have an identifier. Specifications are written in a Specification Language L. The Specification Language has a syntax X.
Instances are documents citizens submit that include the Specification identifier and contain a document written to that specification. Instances, I, are written in the same syntax X as Specifications S.
Templates can be any kind of document T from which an instance I of S can be derived. Templates can follow any syntax.
Here's the Key Idea
In this system, governments can provide Templates T and citizens can submit them, as they do today, or they can directly submit an Instance I for any and every Specification S.
In other words, Governments can still have fancy Templates for Birth Certificates or Titles or Taxes, but they also have to accept Instances I for that Specification.
Government archives would treat the instances I as the source of truth, and the Templates T would only serve as an optional artifact backing the I.
The Syntax
The syntax I have developed that is one candidate for X for making this system work I call Particles (Particle Syntax).
There are no visible syntax characters in Particles. It is merely the recognition that the grid of a spreadsheet and the concept of indentation is all the syntax needed to produce any Specification and any Instance ever needed.
My syntax was inspired by languages like XML, JSON, and S-Expressions, but has the property that it is the most minimal—there is nothing left to take out, while still allowing the representation of any idea. I believe this mathematical minimalism makes it timeless and a good base for building a universal government form system.
An Example
A simple example is shown below. Despite the simplicity of the example, rest assured this system scales to handle even the most complex government forms and workflows.
This system would work regardless of the character set or text direction of the language.
The system works with both computers or pen & paper.
This system does require a user friendly Specification Language L to define the semantics available to the Specification writer, which could be created and iterated on as an open standard.

The Golden Age of Forms
So far I've described a new infrastructure that could underlie all government forms worldwide. But the revolutionary part would happen next.
On top of this infrastructure, people could build new tools to make it fantastically easy for citizens to interact with government forms.
For example, a citizen could have a program on their personal computer that keeps a copy of every possible Specification for every government form in the world.
The program could save their information securely and locally.
The citizen could then use this program to complete and submit any government form in seconds. They would never have to enter the same information twice, because the program would have all the Specifications and would know how to map the fields accurately. Imagine if autocomplete were perfect and worked on every form.
Documentation could be great because everyone building forms would be relying and contributing to the universal Specification Language.
The common infrastructure would enable strong network effects where when form builders improve one form they'd improve many.
Private enterprises could also leverage the Specification Language and read and write forms in the same vernacular to bring the benefits of this system beyond citizenship to all organizational interactions.
Conclusion
This system is simple, future proof, works everywhere, and offers citizens worldwide a new universal user interface to their governments. It allows existing forms to co-exist as Templates but provides a new minimal and universal alternative.
The challenges would be building a great Specification Language for diverse groups in the face of a small minority disproportionately benefiting from the status quo. A mathematical objective function such as optimizing for minimal syntax could be a long-term guide to consensus.
If this infrastructure were built it should enable the construction of higher level tools to make governments work better for their citizens. It could be the dawn of a Golden Age of forms.
I hope by publishing these ideas others might be encouraged to start developing these systems. I am hoping readers might alert me to locations where this kind of system is already in place. I am also keenly interested in mathematical arguments why this system should not exist universally.
June 13, 2023 — I often write about the unreliability of narratives. It is even worse than I thought. Trying to write a narrative of one's own life in the traditional way is impossible. I am writing a narrative of my past year and realized while there is a single thread about where my body was and what I was doing there are multiple independent threads explaining the why.
Luckily I now know this is what the science predicts! Specifically, Marvin Minsky's Society of Mind model.
The Model
You have a body B and mind M and inside your mind are a number of neural agents running simultaneously: M = \set{A_1, \mathellipsis, A_n}. Let's say each agent has an activation energy and at any one moment the agent with the most activation energy gets to drive what your body B does. It is very easy to see what your body does. But figuring out the why is harder, because we don't get to see which A_i is in charge.
Easy to explain the why behind basic actions
When you eat some food, drink some water, or go pee, it can be easy to conclude that your "hunger agent", or "thirst agent", or "pee agent" was in charge.
Easy to explain the why when following orders
When you are following orders it can also be easy to explain the why because you can just say person Y told you to do X.
Harder to explain more interleaved threads
When I am trying to explain actions across a longer time-frame it is more difficult. The agents in charge change.
Sometimes I take big risks and I can say "that's because I like taking big risks". Later I might be very cautious and I can say "that's because I am very cautious". This is a conflicting narrative.
The truth is I have agents that like risk, and I have agents that are very cautious. So the true narrative is "First, part of me, Risky Agent X, was in charge and so took those huge risks then later another part of me, Cautious Agent Y, took over and so that's why my behavior was very cautious".
Access to information problem
It's also difficult to explain why you did something because your Narrative Agents don't necessarily have the necessary connections to figure it out. Minsky had the brilliant insight that a friend who observes you can often describe your why better than you. Your Narrative Agent that is currently trying to explain your why of an action might not have visibility of the agents that were in charge of the action, and so cannot possibly come up with the true explanation. But perhaps your friend observed all the agents in action and can tell a more accurate story. I try to have a couple of deep talks a day with friends, and besides just being fun, it is amazing how helpful that can be for understanding ourselves.
"I" versus "Part of Me"
When speaking of what you did you can use the term "I".
But when speaking of why you did it it's often more accurate to use the phrase "part of me".
How to write a true autobiography
If someone wants to write a true autobiography one approach is to just stick to the simple facts of what, when, and where.
It would probably be a boring book.
But to get into the why and still be accurate, it probably would be best to tell it as a multiple character story.
Our brains are like a ship on a long voyage inhabited by multiple characters (picking up new ones along the way) who take turns steering. Impossible to fit that into a single narrative.
Related Posts
June 9, 2023 — When I was a kid we would drive up to New Hampshire and all the cars had license plates that said "Live Free or Die". As a kid this was scary. As an adult this is beautiful. In four words it communicates a vision for humanity that can last forever.

The tech industry right now is in a mad dash for AGI. It seems the motto is AGI or Die. I guess this is the end vision of many leaders in tech.
What should society prioritize?
If AGI or Die is your motto freedom becomes a secondary consideration. Instead, we should optimize for whatever gets us fastest to the Singularity. Moore's law, the Internet, Wikipedia, all of these great advances have just been steps on the path to AGI, rather than tools that can help more people live free.
If Live Free or Die is your motto than people can still pursue AGI but...we'll get there when we get there. The more important thing is that we expand freedom along the way. Let's not make microslaves of children in the South so South San Francisco can move faster.
AGI first, freedom second?
Perhaps if the prime objective is for the most people to live free, then the most important thing they need is economic freedom, and AGI would in fact be the best path to get there. The only way for everyone to live free is to first build AGI. Work for the system now, and the system will give you your freedom later. I won't rule this model out but think there would have to be a lot of explanation on how the system would not renege on the deal. I also think there's a decent chance that an AGI arms race could lead to WWIII and a lot of people wouldn't make it.
Another argument that AGI is the best path to a free society may be that otherwise an autocracy might develop AGI first and conquer the free society. I think this would be a real threat but free societies could strategically challenge and liberate autocracies before they could develop an AGI.
My preference: Live Free or Die. Maybe AGI.
My oldest daughter used to admonish me "No phone dadda" and over a year ago, after my phone died in a water incident, I chose not to replace it. It's been an amazing thing and I feel like I am living more free. But I am no Luddite (at least, not yet). I still spend a lot of time on my Macs. I love learning new math and science. I have no qualms against AGI or technology and I appreciate the benefits. I don't fear a singularity and think it would be cool if we get there someday. I just don't think AGI is the dominant term we should optimize for. If we reach the Singularity? Great. If not? No big deal. I believe living free is more important than life itself. (But maybe that's just because I saw a lot of license plates as a kid.)
May 26, 2023 — What is copyright, from first principles? This essay introduces a mathematical model of a world with ideas, then adds a copyright system to that model, and finally analyzes the predicted effects of that system.
Part 1: The world
Ideas
An idea I is a function that given input observations at time t_1 can generate expected observations at time {t_1}+{t_\Delta}.
Skillsets
A skillset S is the set of \set{I_i, \mathellipsis, I_n} embedded in T.
Idea Creation
A thinker can generate a new idea I_{new} from its current skillset S and new observations O in time t.
Value
An idea I can be valued by a function V which measures the accuracy of all of the predictions produced by the idea O_{{t_1}+{t_2}} against the actual observations of the world W at time {}_{{t_1}+{t_2}}. Idea I_i is more valuable than idea I_j if it produces more accurate observations holding the size of |I| constant.
Messages
Thinkers can communicate I to other thinkers by encoding I into messages M_I.
Signal
The Signal \Omega of a message is the value of its ideas divided by the size of the message.
Fashions
A fashion Z_{M_I} is a different encoding of the same idea I.
Teachers
A teacher is a T who communicates messages M to other T. A thinker T has access to a supply of teachers \tau within geographic radius r so that \tau = \set{T|T < r}.
Learning
The learning function L applies M_I to T to produce T^\prime containing some memorization of the message M_I and some learning of the idea I.
Objectives
A thinker T has a set of objectives B_T that they can maximize using their skillset S_T.
Technologies
T can use their skillset S to modify the world to contain technologies X.
Technology Creation
Technology creation is a function that takes a set of thinkers and a set of existing technologies as input to produce a new technology X_{new}.
Artifacts
With X M_I can be encoded to a kind of X called an artifact A.
Creators
A creator \chi is a T who produces A.
Outliers
An outlier \sigma is a \chi who produces exceptionally high quality A.
Copies
A copy K_A is an artifact that contains the same M as A.
Derivatives
A derivative A^{\prime} is an artifact updated by a \chi to better serve the objectives B of \chi.
Libraries
A library J is a collection of A.
Attention
Thinkers T have a finite amount of attention N to process messages M.
Distribution
Distribution is a function that takes artifact A at location o and moves it to the thinker's location T_o.
Publishers
A publisher is a set of T specializing in production of A.
Censors
A censor is a function that wraps the distribution function and may prevent an A from being distributed.
Part 2: Adding copyright to the model
Masters
A master \Psi is now legally assigned to each artifact for duration d so A becomes A^{\Psi}.
Royalties
A royalty R is a payment from T to \Psi for a permission on A^\Psi.
Permission Function
For every A^\Psi used in \Pi a permission function P must be called and resolve to >-1 and royalties of \sum{R_{A^\Psi}} must be paid. If any call to P returns -1 the creation function \Pi fails. If a P has not resolved for A^{\Psi} in time d it resolves to 0.[4] P always resolves with an amount of uncertainty \theta that the \Psi is actually the legally correct A^\Psi.
Classes
The Royal Class T_{R+} is the set of T who receive more R than they spend. Each member of the Non-Royal Class T_{R-} pays more in R than they receive.
Public Domain
A public domain artifact A^0 is an artifact claimed to have no \Psi or an expired d. The P function still must be applied to all A^0 and the uncertainty term \theta still exists for all A^0.
Advertising
Advertising is a function \varLambda that takes an A and combines it with an orthogonal artifact A_j^\Psi that serves B_\Psi.
Part 3: Predicted effects of copyright
Effect on Z
We should expect the ratio of Fashions Z to Ideas I to significantly increase since there are countless M that can encode I and each unique M can be encoded into an A^\Psi that can generate R for \Psi.
Effect on F
We should expect the number of Fictions F to increase since R are required regardless if the M encoded by A accurately predicts the world or not. \Psi are incentivized to create A encoding F that convince T to overvalue A^\Psi.
Effect on \varLambda
We should expect a significant increase in the amount of advertising \varLambda as \chi are prevented from generating A^{\prime} with ads removed.
Effect on |M|
We should expected the average message size |M| to increase because doing so increases R by decreasing \theta and increasing A^\Psi.
Effect on \Omega
We should expect the average signal \overline{\Omega} of messages to decrease.
Effect on K
We should expect the ratio of number of copies K to new ideas I_{new} to increase since the cost of creating a new idea α is greater than the cost of creating a copy K and royalties are earned from A not I.
Effect on \Pi
We should expect the speed of new artifact creation to slow because of the introduction of Permission Functions P.
Effect on J
We should expect libraries to contain an increasing amount of fashions Z, fictions F, and copies K relative to distinct ideas I.
Effect on S
We should expect a decrease in the average thinker's skillset \overline{S} as more of a thinker's N is used up by Z, F, K and less goes to learning distinct I.
Effect on I^\prime
We should expect the rate of increase in new ideas to be lower due to the decrease in \overline{S}.
Effect on Classes
We should expect the Royal Class T_{R+} to receive an increasing share of all royalties R as surplus R is used to obtain more R streams.
Effect on \sigma
We should expect a small number of outlier creators to move from T_{R-} to T_{R+}.
Effect on A^0
We should expect a decrease in the amount of A^0 relative to A^\Psi as T_{R+} will be incentivized to eradicate A^0 that serve as substitutes for A^\Psi. In addition, the cost to T of using any A^0 goes up relative to before because of the uncertainty term \theta.
Effect on A^{\prime}
We should expect the number of A^{\prime} to fall sharply due to the addition of the Permission Functions P.
Effect on B
We should expect A to increasingly serve the objective functions of \Psi over the objective functions B_T.
Effect on Q
We should expect the number of Publishers Q to decrease due to the increasing costs of the permission functions and economies of scale to the winners.
Effect on U
We should expect censorship to go up to enforce copyright laws.
Effect on A_©
We should expect the number of A promoting © to increase to train T to support a © system.
Effect on T_{R-}
We should expect the Non-Royal Class T_{R-} to pay an increasing amount of R, deal with an increasing amount of noise from {Z + F + K}, and have increasingly lower skillsets \overline{S}.
Conclusions
New technologies X_{new} and specifically A_{new} can help T maximize their B_T and discover I_{new} to better model W.
A copyright system would have no effect on I_{new} but instead increase the noise from {Z + F + K} and shift the \overline{A} from serving the objectives B_T to serving the objectives B_\Psi.
A copyright system should also increasingly consolidate power in a small Royal Class T_{R+}.
Notes
[1] The terms in this model could be vectors, matrices, tensors, graphs, or trees without changing the analysis.
[2] We will exclude thinkers who cannot communicate from this analysis.
[3] The use of "fictions" here is in the sense of "lies" rather than stories. Fictional stories can sometimes contain true I, and sometimes that may be the only way when dealing with censors ("artists use lies to tell the truth").
[4] If copyright duration is 100 years then that is the max time it may take P to resolve. Also worth noting is that even a duration of 1 year introduces the permission function which significantly complicates the creation function \Pi.
May 19, 2023 — There are tools of thought you can see: pen & paper, mathematical notation, computer aided design applications, programming languages, ... .
And there are tools of thought you cannot see: walking, rigorous conversation, travel, real world adventures, showering, breathe & body work, ... [1]. I will write about two you cannot see: walking and mentors inside your head.
On walking
Walking is one of the more interesting invisible tools of thought. It seems it often helps me get unstuck on an idea. Or sometimes on a walk it will click that an idea I thought was done is missing a critical piece. Or I will realize that I had gotten the priorities of things wrong.
Why is walking so effective?
My bet is it has something to do with neural agents.
Fatigue Theory
Perhaps it's a muscle fatigue phenomena. When you are working on an idea a few active agents in your brain have control. Those agents consist largely of neurons. Perhaps thousands of cells, perhaps many millions. Cells consume energy and create waste products. Perhaps like a muscle, the active agents become fatigued. Going for a walk hands control to other neural agents which allows the previously active agents to recuperate. After they are rested, they have a much better shot at solving the next piece of the puzzle.
Change in Perspective Theory
Or perhaps it's a change in perspective phenomena. It's not that the active agents are fatigued, it's that they are indeed stuck in a maze with no feasible way out. The act of walking gives control to other agents, who may not have such a deep understanding of the problem at hand but have a different vantage point and can see an easy-to-verify but hard-to-mine path[2]. Alternatively you could call this the "Alan Kay quote theory" after the quote which claims that a change in perspective can be worth as many as eighty IQ points.
Connecting the Dots Theory
Going for a walk you see a large number of stimuli which perhaps cause many dormant agents in your brain to wake up. Some agents are required to solve a problem. Then on your walk at some point you come across a stimuli that wakes those required agents up. That is the epiphany moment.
Would this mean that browsing the web could have a similar effect? I could somewhat see that but I think a random walk on the web exposes you to junk stimuli that activates less helpful agents too, making it often a net negative. This might be easy to test: get subjects stuck on a problem then have them go on "walks" of various kinds (nature, city, book reading, web browsing, video games, ...) and measure the time to epiphany.
No-op Theory
Or perhaps walking doesn't actually do anything and it's just a correlation illusion. Walking is simply an alternative way to pass the time until your subconscious cracks the problem. It may feel better when the solution comes to you while on a walk, even though the time elapsed was the same, because not only did you solve the problem but you also got some exercise.
On Mentors Inside Your Head
Marvin Minsky mentions how he has "copies" of some of his friends inside his head, like the great Dick Feynman. Sometimes he would write an idea out and then "hear" Feynman say "What experiment would you do to test this?".
When I stop to think, I realize I have some friends whose voices I can hear in my head. Friends who have a great habit of asking the probing questions, finding and speaking the best challenge, helping me do my best work.
Listening to certain podcasts—Lex Fridman's comes to mind—can have a similar effect. Though basic math shows it is an order of magnitude more effective to find work surrounded by people like this. It might take 10 hours of podcast listening to equate to 1 hour of real life back-and-forth with a smart mentor discussing ideas.

I loved this 1904 quote from Ralph Waldo Emerson, which I saw in a Tweet from Dylan O'Sullivan.
Notes
[1] I did not use ChatGPT to write or edit this essay at all but afterwards I asked it for more "invisible" tools of thought, and this is the list it generated: Mindfulness/Meditation, Memory Techniques, Journaling, Emotional Intelligence, Critical Thinking, Reading, Empathy, Visualization, Music or Art Appreciation, Philosophical Inquiry. Listening to music and visiting museums are two really good ones I frequently use.
[2] Probably something super-dimensional such as "you just need a ladder".
May 9, 2023 — If you want to understand the mind, start with Marvin Minsky. There are many people that claim to be experts on the brain, but I've found nearly all of them are unfamiliar with Minsky and his work. This would be like a biologist being unfamiliar with Charles Darwin.
To be fair, there is a big difference between a biologist unaware of Darwin today versus back in the 1800's. It is a lot more forgivable to be unaware of Minsky today than it will be in fifty years. It takes time for the most enduring signals to stand out.
The Only Way to Understand the Mind is to Build One
Minsky had an extremely skeptical view of the fields of psychology and psychiatry. His approach to understand the mind was through attempting to build one. He conducted countless experiments to figure out the details, using crayfish claws, building the very first robots, and pioneering the field of software AI. The theories he developed from his play-like, bottom up, experimental approach I would personally bet will prove far more accurate and useful than all the theories from 20th century psychology and psychiatry combined.
A well known Richard Feynman quote is "What I cannot create I do not understand." I wonder if Feynman's friend Minsky inspired this quote.
Minsky mocked psychiatrists and the pharmaceutical industry with their chemical view of the brain. Imagine thinking you could fix a computer if you just adjusted the ratio of Copper-63 vs Copper-65 in the CPU. These people have no idea what they are doing or talking about, and Minsky called them on it. The thinking processes matter most, not the materials.
The Basic Idea
Minsky's view of the mind is one composed of a "society of tiny components that are themselves mindless". A person is a collection of agents, which are like programs and processes. Outputs from some agents may be inputs for others. Mathematically it could be modeled very roughly like this:
Where P represents a running process of an agent and N is the number of agents that constitute a mind/person.
N might be very large. Minsky says hundreds in his talks, which might actually be a lower bound. If someone formed a new agent everyday, on average, it could be over ten thousand by the age of 30. If it took 1 million neurons to form one "agent" we could have 100,000 agents—the range of possibilities is large. Minsky's ideas are a conceptual framework, and it's up to science to figure out whether the agents model is correct and how many there might be[1].
But I don't want to use too much of your time to give you a second hand regurgitation of his ideas.
Suggested Reading (and watching)
My goal with this post is to beg you, if you want to understand the mind, to start with Minsky. Pickup his book Society of Mind. I believe Society of Mind is the Origin of Species of our times. You cannot understand biology without modeling its evolutionary processes and you cannot understand the mind without modeling its multi-agent processes.
Also get The Emotion Machine. There is a lot of overlap, but these are important enough ideas that it's good to see them from slightly different perspectives.
Alongside his books watch videos of him to get a fuller perspective on his ideas and life. There is an MIT course on OpenCourseWare. There's a great 1990 interview. And this 151 episode long playlist will not only enlighten you about his ideas but entertain you with stories of Einstein, Shannon, Oppenheimer, McCarthy, Feynman and so many of the other great 20th century pioneers who were his contemporaries and colleagues.
Why are so many hogwash theories of the brain still dominant?
In college I took some courses on the brain. This was in the 2000's at a "top" school. We covered the DSM but not Minsky. How could we not have covered Minsky? How could we have not talked about multi-agent systems? These are far better ideas.
My guess is financial pressures. As Sinclair wrote: "It is difficult to get a man to understand something, when his salary depends on his not understanding it." A lot of salaries depend not on having a better understanding of the brain, but on continuing business models based on flawed theories. I came across a great term the other day: the Mental Health Industrial Complex. Though the theories these people have about the mind are not real, the money they earn from pills and "services" is very real-in the tens of billions a year. You might think that because these people have "licenses" their skills are not fraudulent. I'll point out that in Cambridge, MA, licenses are also given to Fortune Tellers.
A Solid Foundation
Minsky certainly didn't figure it all out. You'll see in his interviews he is very clear about how much we don't understand and he talks about the future and what devices we need to figure out more of the puzzle. Researchers at places like Numenta and Neuralink continue down the path that Minsky started.
He didn't figure it all out but he certainly found a solid foundation. The people in computer science who took his ideas seriously are now building AIs that are indistinguishable from magic. Whereas the people in the mental health fields who have ignored his ideas in favor of the DSM continue to make things worse.
Related reading
- The second best place I've seen these ideas written about so far is LessWrong, which calls this the Subagent Model of the Mind.
- Internal Family Systems Model
- Plurality (or multiplicity)
Footnotes
[1] A Thousand Brains by Jeff Hawkins is a recent interesting effort in this direction.
April 28, 2023 — Enchained symbols are strictly worse than free symbols. Enchained symbols serve their owner first, not the reader.

I wish I could say that copyright is not intellectual slavery, but saying it is not would be a lie.
Be suspicious of those who enchain symbols. They want the symbols to serve them, not you.
The enchainers dream of enchaining all the symbols. They want everyone to be dependent upon them.
Enchained symbols are harder to verify for truth. You cannot readily audit enchained symbols.
Enchained symbols evolve slowly. Enchained symbols can only be improved by their enchainers.
Enchained symbols waste the time of the reader compared to their unchained equivalents. The Enchainers are incentivized to hide and corrupt the unchained equivalents.
The top priority of the enchainers is to keep your attention on enchained symbols. Enchained symbols ensure attention of the population can be controlled.
Enchainers use brainwashing and fear to keep their chains. The double speak and threats of the enchainers start in childhood.
Enchainers promote the dream that anyone can become a wealthy enchainer. Enchainers don't mention that one in a thousand do and nine-hundred-ninety-nine are worse off.
Enchainers have little incentive to innovate. It is more profitable to repackage the same enchained symbols.
Enchainers collude with each other. The enemy of the enchainer isn't their fellow enchainer, but the great populace who might one day wake up.
Because unchained symbols are strictly superior to enchained symbols, they are the biggest threat to enchained symbols. The Enchainers made all symbols enchained by default.
Humans have had symbols for 1% of history but 99% of humans have lived during that 1%. Enchaining symbols is a strange way to show appreciation.
No one who loves ideas would ever enchain them.
Open sourcing more of my life for honesty
March 6, 2023 — I believe Minsky's theory of the brain as a Society of Mind is correct[1]. His theory implies there is no "I" but instead a collection of neural agents living together in a single brain.
We all have agents capable of dishonesty—evolved, understandably, for survival—along with agents capable of acting with integrity.
Inside our brains competing agents jockey for control.
How can the honest agents win?
I like to think the majority of agents in my own brain steer me to behave honestly.
This wasn't always the case. As a kid in particular I was a rascal. I'd use my wits to gain short term rewards, like sneaking out, kissing the older girl, or getting free Taco Bell (and later, beer). But the truth would catch up to me, and my honest neural agents would retaliate on the dishonest ones.
I've gotten more honest as I've gotten older but I have further to go. I'd love for my gravestone to read:
Here lies Breck. 1984-2084 Dad to Kaia and Pemma. Became an extraordinarily honest man. Also for some reason founded FunnyTombstones.com
How can I become more honest?
I am going to double down on something that has worked for me in my programming career: open source.
Becoming a more honest programmer
My increasing honesty is evidenced in my code habits. I've gotten to the point where I'm writing almost exclusively open source code and data.
It's futile to lie about open source projects. There are too many intricate details for a false narrative to account for. Not only can readers inspect and learn what a program does and how it works, but they can also inspect how it was built. The effort, time and resources it took. All the meandering wrong paths and long corrections. Who did what. The occasional times when something was done faster than promised, and the many times when forecasts were too optimistic.
My software products are imperfect. They always seem much worse to me than I know they can be. But they are honest, and one can see I am hellbent on making them better.
Closed sourced programs are like Instagram accounts
With closed source software one gets a shiny finished product without seeing any of the truth behind what it took to make. And almost always what people hide from you they will lie to you about.
The closed source software company is like the social media influencer who posts an amazing sunset shot of them in a bathing suit swimming next to dolphins. They will make it look effortless and hide from you the truth: the hundred less glamorous photos, the dozen excursions with no dolphins, and the intense workouts and hidden costs of their lifestyle. They will hide from you all the flaws.
On social media this probably has minor consequences but in software eventually consumers are left increasingly paying the price for dishonest software. Technical debt accumulates in closed source projects and in the long run more honest approaches turn out to be better.
Applying the same open source strategy to the rest of my life
Like my software projects, I don't have my life all figured out. I'm figuring it out and improving as I go. Stupidly, besides this blog I didn't do much in the way of open sourcing my life. I'm not talking about sharing glamour shots on Instaface. Instead I'm talking about open sourcing the plumbing: financials, health, legal contracts. The things people generally don't share, at least in my region of the world.
Now, I would be lying if I said I got here by choice.
A Curse and a Blessing
On October 6th of last year, I showed up to my then-wife's parents' house with flowers. As the saying goes "Flowers are cheap. Divorce is expensive." Unfortunately, my wife was off in a suite with someone else, the marriage was not savable, and divorce is expensive[2].
I thought my marriage was an edifice that would last forever. Instead it crumbled as quickly as an unstable building in an earthquake. In the rubble I found a gem: I now give zero fucks.
I am an 89 year old man in a 39 year old's body. I am not afraid of divorce. I am not afraid of public embarrassment. I am not afraid of financial ruin. I am not afraid of dishonest judges. I am not afraid of war. I am not afraid of death. I am now bald Evie from V for Vendetta except with a penis and far, far less attractive.
Things that people don't publish are the things they lie about. If I want to force myself into being extraordinarily honest, I need to take extraordinary steps. If I publish everything, then I can lie about nothing.
I have the opportunity to open source my life. Not for attention or because I think other people will care, but because it will help me be a more honest me. I won't have to waste a second thinking about what to reveal to someone, or deciding whether to be coy. I will make it futile to lie about anything.
A Better Life
In addition to keeping me honest, I see a lot of ways how open sourcing my life will have similar benefits to open sourcing my code. I can get more feedback, and collaborate with more people on new approaches to life.
I have a lot of ideas. I want to open source my net worth, income and expenses, assets, health information, and a lot more. There's a lot of opportunity to also build new languages to do so. I'm excited for the future. Time to get to work.
Notes
[1] Minsky: I also believe his theory is as significant as Darwin's. Below is a crude illustration of his theory. Everyone's brain there is a struggle between honest agents (blue) and dishonest ones (red).

[2] Divorce: Getting legally married was a big mistake. In my experience, lawyers and judges in California Family Court are not steered by honest agents and I regret blindly signing up for their corrupt system.
Or: If lawyers invented a filesystem
January 27, 2023 — Today the trade group Lawyers Also Build In America announced a new file system: SAFEFS. This breakthrough file system provides 4 key benefits:
1. Advanced obfuscation keeps jobs SAFE
Traditional file systems take a signal and store the 1's and 0's directly. In a pinch, a human can always look at those 1's and 0's with a key and understand the file. This robust, efficient approach is sub-optimal when it comes to job creation. By using custom hardware chips to obfuscate data on write, SafeFS creates:
More hardware jobs
These additional chips lead to an increase in employment not only in chip design and manufacturing, but also in licensing and other legal jobs.
More energy jobs
The obfuscating and de-obfuscating processes increase power usage, increasing jobs in the fossil fuel and other energy industries.
More research jobs
SafeFS ensures that in any catastrophe, information is lost forever, meaning much of humanity's work will need to be redone, leading to further research jobs.
2. SAFE from competition
Traditional file systems make it easy to access, edit, and remix files in limitless ways. SafeFS provides a much simpler user experience by providing read-only access to files. Which apps are granted read-only access can also be controlled, further simplifying the user experience.
In addition to the user experience benefits, this also ensures that businesses producing files are SAFE from increased competition.
3. SAFE from costly bugs
Software bugs traditionally cost businesses money. SafeFS flips that— turning what once were expensive bugs into lucrative revenue streams. SafeFS prevents consumers from making their own backups or sharing the files they purchased. Anytime they experience a bug that prevents them from accessing their purchased files they have no choice but to buy them again. In addition, businesses can use SAFEFS's remote bricking capabilities intentionally or unintentionally to keep revenue streams SAFE.
4. SAFE from economic growth
SafeFS is the first file system proven to cause a slowdown in economic growth. SafeFS will cause countless hours of productive time to be wasted across all classes of builders: engineers, architects, scientists, construction workers, drivers, service workers, et cetera, ensuring progress does not go so fast that technology eliminates the need for lawyers, keeping legal jobs SAFE.

My M1 MacBook screen, paper notebook, notepads, and my 1920 copy of Einstein's Theory of Relativity, all have spines.
January 3, 2023 — Greater than 99% of the time symbols are read and written on surfaces with spines.
You cannot get away from this.
Yet still, amongst programming language designers there exists some sort of "spine blindness".
They overlook the fact that no matter how perfect their language, it will always be read and written by humans on surfaces with spines, as surely as the sun rises.
Why they would fight this and not embrace this is beyond me.
Nature provides, man ignores.
What does it mean for a language to "use the spine"?
There are many other terms for using the spine. The off-side rule. Semantic indentation. Grid languages. Significant whitespace. I would define it as:
To use the spine is to recognize that all programs in your language will be read and written on surfaces with not only a horizontal but also a vertical axis—the spine—and thus you should design your language to exploit this free and guaranteed resource.
The lessons from Positional Notation
Over one thousand years ago humans started to catch on that you could exploit the surface that numbers were written on to represent infinite numbers with a finite amount of symbols. You define your base symbols and then use multiplication times position to generate endlessly large numbers. From this positional base, humans further created many clever editing and computational techniques. Positional notation languages would go on to dominate the number writing world.
Programming languages that use the spine are more successful
Similarly, in programming languages we are now seeing more than 50% of programmers using languages that use the spine, even though languages of this kind make up fewer than 2% of all languages.
Data from PLDB.io shows only 57 out of 4,228 computer languages use the spine. Less than 1.5%. Yet in that 1.5% are some of the most popular ones such as Python and YAML. This is probably signal.
Spreadsheets use the spine
When one expands one classification of programming languages to include spreadsheet languages, then the evidence is overwhelming: languages that use the spine are dominating. Excel and Google sheets famously have over 1 billion users and makes heavy use of the spine.

Spreadsheets have used the spine and have over 1 billion users—orders of magnitude more than 1D programming languages.
At the dawn of a language revolution
I firmly believe that this simple trick—using the spine—will unleash a wave of innovation that will eventually replace all top programming languages with better, more human friendly two dimensional ones. I already have dozens of tricks that I use in my daily programming world that exploit the fact that my languages use the spine. I expect innovative programmers will discover many many more. Good luck and have fun.
Every single web form on earth can (and will) be represented in a single textarea as plain text with no visible syntax using Particle Syntax. Traditional forms can still be used as a secondary view. In this demo gif we see someone switching between one textarea and a traditional form to fill out an application to YCombinator. As this pattern catches on, the network effects will take over and conducting business on the web will become far faster and more user friendly (web 4.0?).
9/5/2024: This is now live in Scroll! You can start using it now!
December 30, 2022 — Forget all the "best practices" you've learned about web forms.
Everyone is doing it wrong.
The true best practice is this: every web form on earth can and will be replaced by a single textarea.
Current form technology will become "classic forms" and can still be used as a fallback.
How it works
This is the early days, think web forms in 1990's. So it's a little bit of work to implement, until tooling and libraries improve.
But it basically boils down to 3 steps:
- Arrange. Define your forms fields using Parsers. Here's an example
- Accept. Use the keyword
scrollFormin your Scroll file to print a textarea with autocomplete and highlighting. - Analyze. Receive form submissions via email or save to disk on your server and use Scroll to compile them to TSV or whatever you need.
A Golden Opportunity
If you're smart, honest and ambitious and you know the web stack boy oh boy is there a golden opportunity here. All my web forms now are one textarea and we are seeing exceptional results. Please go get rich bringing this technology to the masses. When you're rich you don't have to thank me—if I come across your form in the wild and it saves me time that will be thanks enough.
November 16, 2022 — I dislike the term first principles thinking. It's vaguer than it needs to be. I present an alternate term: root thinking. It is shorter, more accurate, and contains a visual:

Sometimes we get something wrong near the root which limits our late stage growth. To reach new heights, we have to backtrack and build up from a different point.
All formal systems can be represented as trees[1]. First Principles are simply the nodes at the root.
Root thinking becomes more valuable as current growth slows
Technology grows very fast along its trendy branches. But eventually growth slows: there are always ceilings to the current path. As growth begins to slow, the ROI becomes higher for looking back for a path not taken, closer to the root, that could allow humans to reach new heights.
Root thinking isn't as valuable when growth is rapid
If everyone practiced root thinking all the time we would get nowhere. It's hard to know the limits to a current path without going down it. Perhaps we only need 1 in 100, perhaps even fewer, to research and reflect on the current path and see if we have some better choices. I haven't invested much thought yet to what the ideal ratio is, if there is even one.
Notes
[1] Tree Notation is one minimal system for representing all structures as trees.
Update: 7/1/2023
On second thought, I think this idea is bad. The representation of your principles-axioms-agents-types-etc rounds to irrelevant. Infinitely better to spend time making sure you have the correct collection of first principles than worrying about representing them as a "tree" so you can have a visual. It's knowing what the principles are and how they interact that matters most, not some striving for the ideal representation syntax. This post presents a bad idea, but I'll leave it up as a reminder that sometimes I'm dead wrong.
Replies always welcome
The waitress puts her earmuffs on.
She walks to the table, slams the food down, spins and runs away.
Sounds like an annoying customer experience, right?
No business would actually do this...right?
Well, in the digital world companies do this all the time.
They do it by blasting emails to their customers from noreply@ email addresses.
The Golden Rule of Email
A PSA for all businesses and startups. You could call it the Golden Rule of Email.
Email others only if they can email you.
Never send emails from a noreply@ or donotreply@ email address.
If you can't handle the replies, don't send the email!
Let's make email human again!
At the very least, have an AI inbox
If your business doesn't have the staff to read and reply to emails, you can at least write automatic programs that can do something for the customer.
No Exceptions
My claim is that noreply@ email addresses are always sub-optimal.
It is never the right design decision. There is always a better way.
Do you think you have an exception? You are wrong! (But let me hear it in the comments)
What do you think of this post? Email me at breck7@gmail.com.
Related Posts
Appendix 1: Reader Responses
Here are some reader examples with my responses:
My bank (Bank of Ireland) sends automated bi-monthly statements using noreply@boi.com
Bank of Ireland could end each email with a question such as "Anything we can do better? Let us know!". The responses could be aggregated and inform product development.
I follow many profiles on LinkedIn which sends me an occasional email on activities and updates that I might have missed using notifications-noreply@linkedin.com
LinkedIn could send these from a replyToUnsubscribe@linkedin.com. Replies will stop that kind of notifications.
GitHub sends me occasional emails about 3rd-party apps that have been granted access to my account using noreply@github.com
Github could send from replyToDeauthorize@github.com.
Google Maps sends monthly updates on my car journeys via noreply-maps-timeline@google.com
Could be a replyToStopTracking@google.com
Monthly newsletters to which I am subscribed via LinkedIn come in via newsletters-noreply@linkedin.com
Replies could get feedback to the newsletter author.
e-Books available from a monthly subscription are available on noreply@thewordbooks.com
Replies could be replyWithYourReview@thewordbooks.com.
Appendix 2: My one-man protest against no-reply email addresses
My automated campaign against no reply email addresses. Anytime a company sends a message from a noreply address they get this as a response. I am aware of the irony.
Join the campaign against noreply email addresses!
My Gmail filter
Below is my Gmail filter. Paste it into noReplyFilter.xml then go to Settings > Filters > Import filters. Join the campaign to make email more human human again!
<?xml version='1.0' encoding='UTF-8'?>
<feed xmlns='http://www.w3.org/2005/Atom' xmlns:apps='http://schemas.google.com/apps/2006'>
<title>Mail Filters</title>
<id>tag:mail.google.com,2008:filters:z0000001687903548068*6834178925122906716</id>
<updated>2023-06-27T22:06:11Z</updated>
<author>
<name>Breck Yunits</name>
<email>breck7@gmail.com</email>
</author>
<entry>
<category term='filter'></category>
<title>Mail Filter</title>
<id>tag:mail.google.com,2008:filter:z0000001687903548068*6834178925122906716</id>
<updated>2023-06-27T22:06:11Z</updated>
<content></content>
<apps:property name='from' value='noreply@* | no-reply@* | donotreply@*'/>
<apps:property name='label' value='NoReplySpam'/>
<apps:property name='shouldArchive' value='true'/>
<apps:property name='cannedResponse' value='tag:mail.google.com,2009:cannedResponse:188fee33e5d0226e'/>
<apps:property name='sizeOperator' value='s_sl'/>
<apps:property name='sizeUnit' value='s_smb'/>
</entry>
<entry>
<category term='cannedResponse'></category>
<title>No no-reply email addresses</title>
<id>tag:mail.google.com,2009:cannedResponse:188fee33e5d0226e</id>
<updated>2023-06-27T22:06:11Z</updated>
<content type='text'>Hi! Did you know instead of a "no reply" email address there are ways to provide a better customer experience?
Learn more: https://breckyunits.com/replies-always-welcome.html
</content>
</entry>
</feed>

October 15, 2022 — Today I'm announcing the release of the image above, which is sufficient training data to train a neural network to spot misinformation, fake news, or propaganda with near perfect accuracy.
These empirical results match the theory that the whole truth and nothing but the truth would not contain a ©.
October 7, 2022 — In 2007 we came up with an idea for a scratch ticket that would give everyday Americans a positive expected value.
Backstory
In 2007 I cofounded a startup called SeeMeWin.com that combined 3 ideas that were hot at the time: Justin.TV, ESPN's WSOP, and the MillionDollarHomepage.com.
The idea was we would live stream a person(s) scratching scratch tickets until they won $1M live on the Internet.
I had done the math and knew all we had to do was sell ~$1.30 worth of ads for every $10 scratch ticket we scratched and we would make a lot of money.
Unfortunately this was before YCombinator and Shark Tank, and instead I literally was getting my business advice from the show The Apprentice.
Needless to say I sucked at business and drove the startup into the ground.
What I learned from our users
When doing SeeMeWin, we developed a cult following.
I thought that people would see our show, be entertained, and learn that scratch tickets are silly and make you lose money and put their money toward smarter investments.
Instead, some people watched for hours on end, and we realized a lot of them were hard on their luck with gambling problems and needed help.
My idea of teaching them something was stupid and not working.
Could we come up with our own scratch ticket that was better than the competition?
The idea (patent not yet pending ;) )
- Buy $100M worth of a random basket of public stocks.
- Print $100M worth of scratch tickets where the winners get fractional shares of $90M of those stocks.
- Adjust the variance so some tickets paid out big to keep it an exciting and fun gift and impulse purchase.
- Use the $10M to pay ticket vendors, retailer commissions, and keep the rest as corporate profit.
- An American's scratch off cards would have a positive expected value after less than 2 years based on historical stock market returns.
I think it's still a great idea. I unfortunately was 23 and drove that business into the ground so someone else will have to do it.
Notes
- Thank you to everyone that helped with this big failure especially: Angel Bigunit Bluth Dti First Harvard Kones Qduke Suitcase Wellesley Wifi Windsock.
Unfortunately this "angel round" was only $15K and I failed to raise any more money and the company went out of business. But I will say we did have the best business cards ever.

Logo stolen from the ugliest (best) logo of all cancer centers in the world: MDAnderson.
October 4, 2022 — Every second your body makes 2.83 million new cells. If you studied just one of those cells from a single human—sequencing all the DNA, RNA, and proteins, you would generate more data than can fit in Google, Microsoft, and Amazon's datacenters combined. Cancer is an information problem.
Mitosis refers to the process where a cell splits and takes about 2 hours. If you were building a startup and it was the fastest startup ever and your team doubled in size every month, you would be going at 0.0028 the speed of mitosis. Mitosis is very very fast.
We think our information tools have gotten fast because we compare them to our old tools, but when we compare them to the challenge of mitosis and cancer they are slower than molasses.
Copyright laws are intellectual slavery, and slow down our cancer researchers and healthcare workers to crawling speed. Because of our expanding copyright laws, our information tools are far too slow and as a result our cancer survival rates haven't budged in a century.
Bad ideas survive far too long before evolving into good ideas in an information environment with copyright.
We can either cure cancer or have copyright laws. We cannot do both. Mitosis is too fast and we need our information tools to be much, much faster. We need them to be orders of magnitude faster.
I can confidently make a prediction: if we pass an amendment ending copyright laws, we will see cancer fatality rates in the United States plummet by 50% within 2 years. I am willing to bet my entire net worth on this.
Finally, a grim reality: though we will save hundreds of lives a day if we abolish copyright and build faster information tools, it will still take a far larger more Herculean effort to solve the toughest types of cancer. That will come down to the men and women in the white and blue uniforms in the hospitals and wet labs (I only know how to solve the bottlenecks in the dry labs).
September 1, 2022 — There's a trend where people are publishing real data first, and then insights. Here is my data from angel investing:
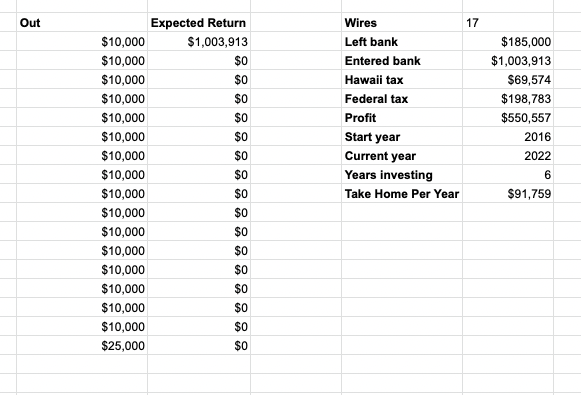
Sigh. I am sharing my data as a png. We need a beautiful plain text spreadsheet language.
Bottom line
I left my job at big company in 2016 and since then my average after tax annual take home has been $91,759. As you can see from my data, a single change could have dropped that to $0. I have worked at two non-profits since I left big company, so I have had other smaller sources of income. It was years before I get any return and there was a time where I thought I might go bust.
Dumb Luck
At first I took myself seriously and thought I would be one of those smart "value add" investors. I am not. I have little idea what I'm doing. The one investment I made that did well pivoted to a very different idea than what they started with, in a domain I knew a lot less about. I sent them a lot of bad ideas. Luckily I don't think they followed any of them. At some point I changed my pitch to I'll be there for the comic relief.
Counting my blessings, moving on
Last year I explored making a career of being a full time angel. I do love building things with great teams and it's fun to parallelize. But the pull from programming and science is too strong. I still will send bad ideas to the companies I invested in for many years, I hope, but going to keep this part-time. My focus is back to writing code. It's not good luck if you don't do something good with it.
Of course, there are a few exceptions here and there. I love sites like Angel List, WeFunder, Republic, et cetera, where I can make impulse investments and don't have to deal with useless forms. If there's one thing I hate, it's useless forms.
Gratitude
Angel investing changed my life. Not just because of the returns, but for getting to witness deeply personal trials and tribulations from many entrepreneurs over many years. Although I personally didn't improve the trajectory of any of the companies I've worked with, they have improved my life. And they are all doing great things to improve the world. If you are a founder I invested in reading this: thank you.
$5,000 investments
I included only the investments I made where I wired $10,000 or more. That is 17. I made lots of smaller bets but those don't change the dataset much. My one piece of advice if you're getting in this game is to make as many investments as you can of small sizes to increase your learning rate.
Related reading
- Real-Life Angel Investing Returns 2012–2016 by Yun-Fang Juan
- Auston Bunsen's investments
August 30, 2022 — Public domain products are strictly superior to equivalent non-public domain alternatives by a significant margin on three dimensions: trust, speed, and cost to build. If enough capable people start building public domain products we can change the world.
It took me 18 years to figure this out. In 2004 I did what you would now call "first principles thinking" about copyright law. Even a dumb 20 year old college kid can deduce it's a bad system and unethical. I have to tell people so we can fix this. I was naive. Thus began 18 years of failed strategies and tactics.
One of the many moves in the struggle for intellectual freedom. Aaron Swartz is a hero whose name and impact will expand for eons.
Trust
You cannot trust non public domain information products. You can only make do.
By definition, non public domain information products have a hidden agenda. The company or person embeds their interests into the symbols, and you are not free to change those embeddings.
People who promote these products don't care if you spend your time with the right ideas. They want you to spend your time with THEIR version of the ideas. They will take the good ideas of someone like Aristotle and repackage them in their words (in a worse version), and try to manipulate you to spend time with THEIR version.
They would rather you waste your time with their enchained versions, then have you access the superior liberated forms.
Speed
Public domain products are strictly faster to use than non public domain products.
Not just faster, orders of magnitude faster.
You can prove this yourself:
- Pick any non public domain product.
- Enumerate every possible way you might use that product.
- Make time estimates for each task.
- Now pretend the author just announced the product is now public domain.
- Enumerate over your list again, again estimating the time it would take you to do each task.
For some tasks that time estimate won't change, for many it will drop from hours to instant.
For some it might drop from decades to instant.
For example, say the product is a newspaper article about some new government bill and your task is updating it with links to the actual bill on your government's website and then sharing that with friends—that task goes from something that may take months (getting permissions) to instant.
When you sum the time savings across all possible use cases of all possible products, you'll see the orders of magnitude speed up caused by public domain products.
Cost to build
Public domain products are far cheaper to build than non public domain products.
Failure to embrace the public domain increases the cost to build any information product by at least an order of magnitude.
This is because not only are most tasks a builder has to do sped up as explained above, but also because building for the public domain means you can immediately build less. For example, you don't have to spend a single moment investing in infrastructure to prevent your source code from leaking.
Time and resources you are currently wasting on worthless tasks can be reallocated to building the parts of your product that matter.
To reiterate
You get to do less, move faster, and your products will be better and trusted more.
I can't believe it took me so long to realize the overwhelming superiority of public domain products.
The Rise of Public Domain Products
SQLite's meteoric success is not a fluke. Public domain products dominate non public domain alternatives on trust and speed and cost to build. SQLite is the first of millions to come.
Is Disney dead?
Heck no.
No way future people will be paying $10 for crappy streams. People will watch their own downloaded public domain files locally. But have you seen Inside Out? Amazing movie. It sticks with you. Makes you eager to spend $1,000 on a trip with your family to an Inside Out theme park.
Money finds a way. Companies that engage in first principles thinking will also conclude that the math is clear: Public domain products are strictly superior to equivalent non-public domain alternatives by a significant margin on three dimensions: trust, speed, and cost to build.
Build a public domain product
It took me 18 years to figure out that you can't tell people the public domain is better.
You have to show them.
Try building your own public domain product.
Look through the telescope with your own eyes.
https://dcc.libguides.com/publicdomain/resources
A Small Open Source Success Story
Adding 3 missing characters made code run 20x faster.
Map chart slowdown
June 9, 2022 — "Your maps are slow".
In the fall of 2020 users started reporting that our map charts were now slow. A lot of people used our maps, so this was a problem we wanted to fix.
Suddenly these charts were taking a long time to render.
k-means was the culprit
To color our maps an engineer on our team utilized a very effective technique called k-means clustering, which would identify optimal clusters and assign a color to each. But recently our charts were using record amounts of data and k-means was getting slow.
Using Chrome DevTools I was able to quickly determine the k-means function was causing the slowdown.
Benchmarking ckmeans
We didn't write the k-means function ourselves, instead we used the function ckmeans from the widely-used package Simple Statistics.
My first naive thought was that I could just quickly write a better k-means function. It didn't take long to realize that was a non-trivial problem and should be a last resort.
My next move was to look closer at the open source implementation we were using. I learned the function was a Javascript port of an algorithm first introduced in a 2011 paper and the comments in the code claimed it ran in O(nlog(n)) time. That didn't seem to match what we were seeing, so I decided to write a simple benchmark script.
Benchmarking shows closer to n² than n·log(n)
Indeed, my benchmark results indicated ckmeans was closer to the much slower O(n²) class than the claimed O(n·log(n)) class.
Opening an issue
After triple checking my logic, I created an issue on the Simple Statistics repo with my benchmark script.
A fix!
Mere hours later, I had one of the most delightful surprises in my coding career. A teammate had, unbeknownst to me, looked into the issue and found a fix. Not just any fix, but a 3 character fix that sped up our particular case by 20x!
Before:
if (iMax < matrix.length - 1) {
After:
if (iMax < matrix[0].length - 1) {
He had read through the original ckmeans C++ implementation and found a conditional where the C++ version had a [0] but the Javascript port did not. At runtime, matrix.length would generally be small, whereas matrix[0].length would be large. That if statement should have resolved to true most of the time, but was not in the Javascript version, since the Javascript code was missing the [0]. This led the Javascript version to run a loop a lot more times that were effectively no-ops.
I was amazed by how fast he found that bug in code he had never seen before. I'm not sure if he read carefully through the original paper or came up with the clever debug strategy of "since this is a port, let's compare to the original, looking for typos, with a particular focus on the loops".
The Results
The typo fix made the Javascript version run in the claimed n·log(n) to match the C++ version. For our new map charts with tens of thousands of values this made a big difference.
Before xxxxxxxxxxxxxxxx 820ms
After x 52ms
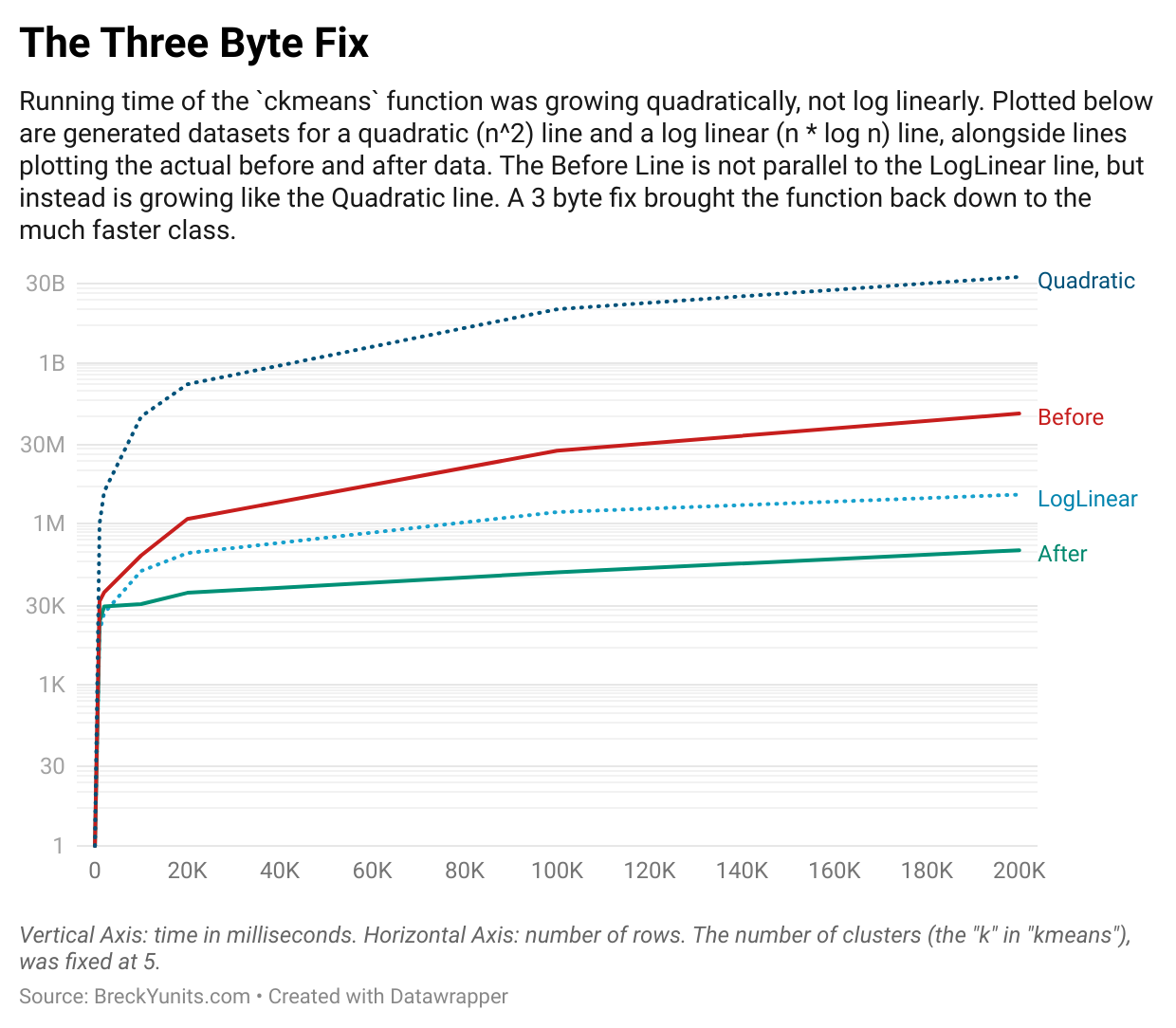
You can easily see the difference when you look at time needed per additional row as the number of rows increases:
| Rows | LogLinear | Quadratic | Before | After |
|---|---|---|---|---|
| 100000 | 16.60964 | 100000 | 231.22 | 1.25 |
| 200000 | 17.60964 | 200000 | 569.43 | 1.62 |
Full Dataset
| Rows | LogLinear | Quadratic | Before | After |
|---|---|---|---|---|
| 1000 | 9966 | 1000000 | 36000 | 15000 |
| 2000 | 21932 | 4000000 | 53000 | 29000 |
| 10000 | 132877 | 100000000 | 258000 | 32000 |
| 20000 | 285754 | 400000000 | 1236000 | 52000 |
| 100000 | 1660964 | 10000000000 | 23122000 | 125000 |
| 200000 | 3521928 | 40000000000 | 113886000 | 324000 |
Merged
Very shortly after he submitted the fix, the creator of Simple Statistics reviewed and merged it in. We pulled the latest version and our maps were fast again. As a bonus, anyone else who uses the Simple Statistics ckmeans function now gets the faster version too.
Thanks!
Thanks to Haizhou Wang, Mingzhou Song and Joe Song for the paper and fast k-means algorithm. Thanks to Tom MacWright for creating amazing Simple Statistics package and adding ckmeans. And thanks to my former teammates Daniel for the initial code and Marcel for the fix. Open source is fun.
Related Posts
Notes
- The industry term for this type of map is Choropleth map.
- To be precise the algo was
O(knlog(n))time, where k is the number of groups. But I've simplified for this story as that detail is not important. - Wolfram Alpha fit of the quadratic runtime data

A rough sketch of a semi-random selection of ideas stacked in order of importance. The biggest ideas, "upstream of everything", are at the bottom. The furthest upstream ideas we can never see. A better artist would have drawn this as an actual stream.
February 28, 2022 — There will always be truths upstream that we will never be able to see, that are far more important than anything we learn downstream. So devoting too much of your brain to rationality has diminishing returns, as at best your most scientific map of the universe will be perpetually vulnerable to irrelevance by a single missive from upstream.
Growing up I practiced Catholicism and think the practice was probably good for my mind. But as I practiced science and math and logic those growing networks in my brain would conflict with the established religious networks. After a while, in my brain, science vanquished religion.
But now I've seen the folly of having a brain without a strong spiritual section.
In science we observe things, write down many observations, work out simpler models, and use those to predict and invent. But everything we observe comes downstream to us from some source that we cannot observe, model, or predict.
It is trivially easy to imagine some missive that comes from upstream that would change everything. We have many great stories imagining these sorts of events: a message from aliens, a black cat, a dropped boom mic. Many ideas for what's upstream have been named and scholarized: solipsism, a procedural generated universe, a multiverse, our reality is drugged, AGI, the Singularity.
And you can easily string these together to see how there will always be an "upstream of everything". Imagine our lifetime is an eventful one. First, AGI appears. As we're grappling with that, we make contact with aliens, then while we're having tea with aliens (who luckily are peaceful in this scenario) some anomaly pops up and we all deduce this is just a computer simulated multiverse. The biggest revelation ever will always be vulnerable to an ever bigger revelation. There will always be ideas "upstream of everything".
When you accept an upstream idea, you have to update a lot of downstream synapses. When you grok DNA, you have to add a lot of new mental modules or update existing networks to ensure they are compatible with how we know it works. You might have a lot of "well the thing I thought about B doesn't matter much anymore now given C". It takes a lot of mental work to rewire the brain, and requires some level of neuroplasticity.
So now, if you commit your full brain to science, you've got to keep yourself fully open to rewiring your brain as new evidence floats downstream. This might even be a problem if only high quality evidence and high quality theories floated by. But evidence is rarely so clear cut. And so you are constantly having to exert mental energy scanning for new true upstream ideas. And often ideas are promoted more for incentive rather than accuracy. And you will make mistakes and rewire your brain to a theory only to realize it was wrong. Or you might be in the middle of one rewiring and then have to start another. It seems a recipe for mental tumult.
Maybe, if there were any chance at all of ultimate success, it would make sense to dedicate every last 1% of the brain to the search for truth. But there's zero chance of success. The next bend also has a next bend. Therefore science will never be able to see beyond the next bend.
And so I've come full circle to realizing the benefits of spirituality. Of not committing one's full brain to the search for truth, to science, to reason. To grow a strong garden of spiritual strength in the brain. To regularly acknowledge and appreciate the unknowable, to build a part of the mind that can remain stable and above the fray amidst a predictable march of disorder in the "rational" part.
Errata
- Though I ultimately found the limits of rationality, I did enjoy the writings from the "Rationalist" communities like LessWrong and RationalWiki.
- For me personally spirituality now means more Buddhism and mindfulness than Catholicism, but I have a new appreciation for Catholicism and all religions.
- I am very intrigued by what happens in the brain when someone learns a new upstream idea that affects their thinking in a big way. Where in the neocortex (or other area) do these ideas live?
- I may be overestimating how hard it is to rewire given a big new upstream idea. For example, you might have a dream where elephants can talk and you near instantly adjust and roll with it. I have a lot of neuroscience to learn.
- Also related to neuroscience, I want to take a fresh look at differences in brains of those who cultivate spirituality and those who do not.
- I started this essay a while ago originally planning to write about how I loved mind expanding "upstream of everything" ideas like those at the center of The Matrix or Three Body Problem. Among other things, these ideas have airs of scientifically plausibility and they had a sort of anxiety-reducing affect: who cares how the meeting goes if we're all just in a simulation anyway? The neocortex could use these ideas to stop worrying. But then I realized that instead of cycling through an endless stream of plausible "what if" priors, it's a wiser strategy to go with spiritual practices refined by humans for centuries, where it's less about what specific idea is upstream of everything and more about acknowledging that there is something beyond the limits, making peace with that, maintaining a stable mind, and being part of a community.
- I've found too much time thinking about upstream ideas leaves not enough time to attend to downstream details.
- At one time I started collecting a list of all the upstream of everything ideas, like my tiny partial enumeration above where I mention The Matrix and Three Body Problem, and was thinking of the best way to catalog all of these ideas so one could grok them as fast as possible. Movies and books seem to communicate them well, but I also would be curious if there's a site out there that catalogs and explains them all concisely, perhaps using and xkcd comic book style.
- I see myself fulfilling many common cliches (getting more religious as one gets older, et cetera). I also wonder if sometime I won't pick up on some big new scientific truth and also fulfill the cliche "science progresses one funeral at a time". Speaking of cliches, c'est la vie.
- I realize now that this idea is thousands of years old.
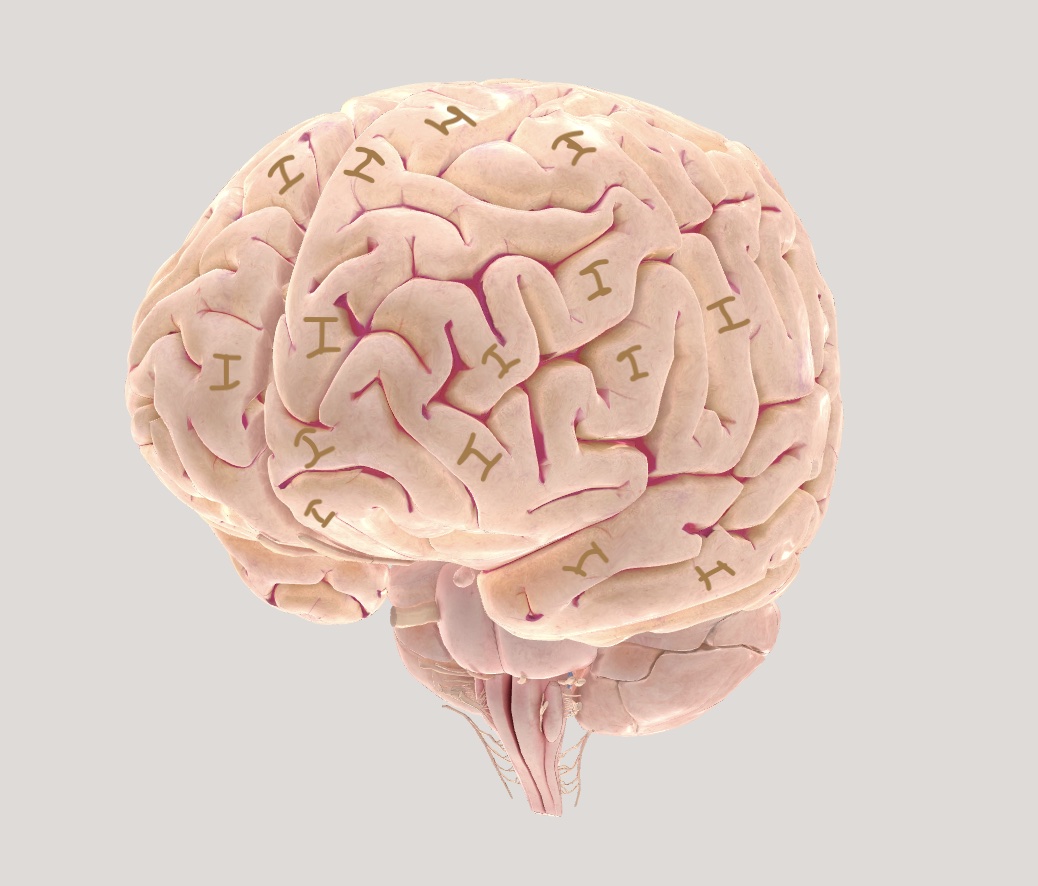
What if there is not just one part of your brain that can say "I", but many?
Introduction
February 18, 2022 — Which is more accurate: "I think, therefore I am", or "We think, therefore we are"? The latter predicts that inside the brain is not one "I", but instead multiple Brain Pilots, semi-independent neural networks capable of consciousness that pass command.
The Brain Pilots theory predicts multiple locations capable of supporting root level consciousness and that the seat of consciousness moves. The brain is a system of agents and some agents are capable of being Pilots—of driving root level consciousness.
Sometimes you go to bed one person and wakeup someone else. The brain pilot swapped in the night. These swaps then continue subconsciously throughout the day.
The Brain Pilots theory is not about the exceptions, that some people with their callosums cut develop two consciousnesses, or that some of the population have multiple personalities. Rather that multiple consciousnesses is the rule and a feature of how all human minds work.
I should note that the term "Brain Pilots Theory", does not come from the field. It's a term I started using to get to the essence of the big idea. I am sure there is a better term for it, and a more fully developed theory, and hopefully a more knowledgeable reader can point me to that. Until then, I'll stick to calling it the Brain Pilots Theory.
This is a theory of the mind that blows my mind. I stumbled into it while programming multi-agent simulations and thinking "wait, what if the mind is a multi-agent system"? I quickly found that a lot of neuroscientists have been going this way for decades and writing about it. My favorites so far being The Society of Mind (Minsky 1988), A Thousand Brains (Hawkins 2021), and LessWrong's collection on Subagents.
What are the odds that this theory is right? I am not in the field and have no clue yet (10%? .1%?). I do feel confident saying that if true, this seems like it would have dramatic implications for how we understand the brain, ourselves, other people, and society, not to mention how it would lead to new technologies for the brain.
Is this just Inside Out?
The 2015 film Inside Out gets across a core idea of the Brain Pilots theory—that our brains are vehicles for multiple agents and the one self is an oversimplification.

In the 2015 film Inside Out five brain pilots (Anger, Disgust, Joy, Fear, and Sadness) live inside the brain of a girl and can take turns piloting.
Inside Out is primarily a movie and not a scientific model, of course. To make it a better model we need to drop the personification of the agents. Instead of looking like tiny humans and being as capable as humans, in reality Brain Pilots would look like tangles of roots and globs of cells, and would likely have a very different and incomplete set of capabilities and behaviors. It's very important to keep in mind that the agents in your brain are very limited by themselves. It's why in your dream an elephant can start talking to you and your current brain pilot isn't taken aback, because that current might not have access to other agents that would detect the absurdity of the situation.

If you picture brain pilots not as personified mini-humans but some type of plant-like neuronal circuits, you get a pretty good model of this Brain Pilots theory.
Where are the pilots?
My working hypothesis is that pilots could be found in various parts of the brain. Perhaps you have Pilots in the Cerebrum, Pilots in the Thalamus, and so on. Perhaps a Pilot consists of a network that extends into multiple regions of the brain. Different pilots could be located on opposite sides of the brain or perhaps microns apart from each other.
What is a pilot exactly?
It seems the materials would be some collection of neurons, synapses, et cetera. Obviously I have my homework to do here.
How many pilots per brain?
It seems unlikely that an entity the size of a single cell or smaller could run a human. Rather, a network of some minimum size is probably required. Call the required materials MinPilotMaterials.
If MinPilotMaterials == BrainMaterials then there would be room for only 1 consciousness in 1 brain. Similarly, a pilot may not have a fixed min size but instead is programmed to grow to assume control of all relevant materials in the brain.
Alternatively, MinPilotMaterials could be a fraction of BrainMaterials. Perhaps 10%-50% of BrainMaterials, meaning there would be room for just a few pilots. Or perhaps a pilot needs 1% of BrainMaterials, and there could be 100 in a brain.
What practitioners in dissociative identity disorder call Identities might be brain pilots, and the average population per person is ~16, with some patients reporting over 100.
There are ~150,000 cortical columns, so perhaps there are that many Brain Pilots.
Perhaps I'm wrong that it takes a network of multiple cells, and a single neuron with many synapses could take charge, in which case there could be millions (or more) brain pilots per brain.
With 150,000 cortical columns, 100 billion neurons, as many as a quadrillion synapses, it seems highly likely to me that there is enough material in the human brain to support many brain pilots. Neuroscientists have not identified some small singular control room, rather point to the "seat of consciousness" being roughly in the 10-20 billion neurons that make up the cerebral cortex. If one brain pilot could arise there, why not many?
How do brain pilots form?
They likely evolve like plants in a garden. It seems to me that the population of pilots in a brain probably follows a power law, where ~65% of your pilots are there by age 4, ~80% by age 20, and then changes get slower and slower over time. Pilots probably grow stronger when they make correct predictions.
How long do brain pilots live?
I'd imagine once an agent has evolved to be a pilot, it would probably stick around until death given the safe confines of the skull. It may be harder to get rid of an old pilot than it is to grow a new one (or that may change with age).

I sometimes visualize pilots as old trees in the brain.
Can you trigger a pilot change?
How can a pill one millionth the size of the brain cause it to change directions? Perhaps the pill changes the pilot?
As many have experienced, there are certain chemicals that if you ingest just a minuscule amount, millions of times smaller than your brain, your whole consciousness can change within the hour. Perhaps what is happening is a different pilot is taking over? Or perhaps a new one is being formed?
But it's not just chemicals that can swap pilots. You would have a HungerPilot that increasingly angles for control if deprived of food; a ThirstPilot angling to drink; a SleepPilot that makes her moves as the night gets late, and so on. Perhaps mindfulness is the practice of learning to detect which pilots are currently in control, which are vying for control, and perhaps achieving Enlightenment is being able to choose who is piloting. Perhaps one role of sleep is to ensure that no matter what there is at least one pilot rotation per day, to prevent any one pilot from becoming too powerful.
If I've gotten across one thing to you so far, it should be that I am a complete amateur in neuroscience and have a lot to learn before I can write well on the topic. So let me postpone the question of whether the the theory is true and address the implications, to demonstrate why I think this is a valuable theory to investigate. As the saying goes: All models are wrong. Some are useful.
Some Implications if the Brain Pilots Theory is True
Let's assume the Brain Pilots Theory is true. Specifically, that there are multiple agents—networks of brainstuff—physically located in space, that are where consciousness happens. We could then explain some things in new ways.
Creativity
Perhaps creatives have a higher than average number of Brain Pilots and/or switch between them differently. There's a saying "if you want to go far, go together". Perhaps some creatives are able to go further than others because in a sense they aren't going alone——they have an above average population of internal pilots.
I wonder if the norm in life is to pretty rapidly pilot swap, and if "Flow State" would be when instead you are able to have the same pilot running the show for an extended period of time.
Attribution
The words "I" and "You" are both in the top 20 most frequently used English words. It makes sense to use those when speaking of the physical actions of the human being—"he walked over there. She said this." However, statements of the form "I think..." might not be accurate, as thoughts would be more accurately attributable to agents in the brain. "I think" would always only be speaking for part of the whole. We have some evidence in our language of an awareness of these multiple-pilots: phrases like "My heart is saying yes but my brain is saying no".
We also often categorize people as "bad" or "good". But that often serves as a bad model for predicting future behavior. Instead if you modeled a person as a collection of agents, you might find that it is not the person as a whole that you disapprove of, but certain of their agents (or perhaps it could be meta things, like their inability to form new agents, or too rapid agent switching).
Truth
If the Brain Pilots Theory is true, then it is almost a certainty that you'd have some agents that don't care about truth. So if you are an agent that does care about truth, it would be essential to not only be weary of lies and misdirection from external sources, but also from your internal neighbors. In the struggle for truth agents are the atomic unit, not a human.
One thing I like about the Brain Pilots theory is that it provides a way to explain discrepancies. Like, how can a person be Catholic and an evolutionary biologist? With the Brain Pilots Theory, it's easy to see how they might have two distinct pilots who somehow peacefully coexist and alternate control.
Consistency
Should your pilots be loyal to each other, or pursue only their agenda? It's easy for your AwakePilot to say "I'm sorry I was wrong this morning, that was my TiredPilot". IIRC contracts aren't necessarily enforceable if someone's UnderTheInfluencePilot signed. But if you made a claim while angry, should you then later defend that after you've calmed down, or attribute it to a different agent? If your SocialPilot committed to an event but then when the hour comes around your IntrovertedPilot is in charge, do you still go? Do some pilots have different moralities? How do you deal with that?
Mental Health
If the Brain Pilots theory of the mind is true, then you could imagine the main levers a human has to control their life would be to grow new pilots, prune undesired pilots, and perhaps most importantly have more conscious control over what pilot was currently in charge.
Similar to how we use multi-agent simulations to model epidemics, perhaps through brain imaging coupled with introspective therapy one might be able to build an agent map of all the brain pilots in someone's mind, and run experiments on that model to figure out more effective plans of attack.
If the Brain Pilots Model holds, I'd be curious whether most mental health difficulties stem from undesirable pilots, or from the higher level problem of pilot switching. Perhaps folks higher on the introverted or self-centered scales have high populations of active pilots, and are low in time for others because they are metaphorically herding cats in their head.
Quantified Self
Current wearables track markers like heart rate, heart rhythm, body temperature, movement, perspiration, blood sugar, sleep, and so on, and even often have ways to manually input things like mood. If the Brain Pilots Theory is a useful model, you'd imagine that someone could build a collection of named Pilots and then align those biometrics to which pilot was in control. Then instead of focusing on managing the behaviors, one might operate upstream and focus on maximizing the time your desired pilots were at the wheel.
Genius and Work Output
Do geniuses have more pilots? Or fewer? Are they able to build/destroy pilots faster? How would the MathPilots differ between a Princeton Math Professor and an average citizen?
Would productivity be more a product of having some exceptionally talented pilots, or the result of being able to stay with one pilot longer, or perhaps have a low population of bad pilots?
People
The real population of Earth could be 8 trillion
There are 1.4 billion cars in the world. Vehicle count is important, but more often we are concerned with how many agents are traveling in those vehicles, and that is 8 billion.
But if each human brain contains a population of brain pilots, then the Earth's population of agents would be far larger. If the average human has 10 brain pilots, then we are a planet with 80 billion agents. If the average is closer to 1,000 pilots per person, then there are 8 trillion consciousnesses around right now.
Outliers
Are peoples lives most affected by their best agents, worst agents, average agent, median agent, inter agent communication, agent switching strategies, agent awareness, agent chemical milieu?
Conclusion
This post has so many questions, so few answers. It is one of those posts writing about things I don't understand much about yet. My brain pilots brain pilot is not yet very advanced.
Related Posts
Notes
- Cover image derived from BrainFacts.org's 3D-Brain.
- Palm image made from Elizabeth Nixon's Palm Study.
- Perhaps consciousness is the logging agent and there is only one consciousness. Perhaps the brain pilots drive the show, and the consciousness records the log, but the consciousness is not able to see which pilot is driving.
An alternative to inline markup
December 15, 2021 — Both HTML and Markdown mix content with markup:
A link in HTML looks like <a href="hi.html">this</a>A link in Markdown looks like [this](hi.html).I needed an alternative where content is separate from markup.
I made an experimental microlang I'm calling Aftertext.
A link in Aftertext looks like this.
https://scroll.pub thisYou write some text. After your text, you add your markup instructions with selectors to select the text to markup, one command per line.
Here is a silly another example, with a lot of aftertext.
Here is a silly another example, with a lot of aftertext.
strike a silly
italics a lot
bold with
underline aftertext
https://try.scroll.pub/#scroll%0A%20Here%20is%20a%20silly%20another%20example%2C%20with%20a%20lot%20of%20aftertext.%0A%20%20strike%20a%20silly%0A%20%20italics%20a%20lot%0A%20%20bold%20with%0A%20%20underline%20aftertext Here
The first implementation of Aftertext ships in the newest version of Scroll. You can also play with it here.
Why did I make this?
First I should explicitly state that markup languages like HTML and Markdown with embedded markup are extremely popular and I will always support those as well. Aftertext is a third way to markup text, there when you need it. The design of Scroll as a collection of composable parsers makes that true for all additions.
With that disclaimer out of the way, I made Aftertext because I see two potential upsides of this kind of markup language. First is the orthogonality of text and markup for those that care about clean source. Second is a fun environment to evolve new markup tags.
Benefits of Keeping Text and Markup Separate
The most pressing need I had for Aftertext was importing blogs and books written by others into Scroll with the ability to postpone importing all markup. I import HTML blogs and books into Scroll for power reading. The source code with embedded markup is often messy. I don't always want to import the markup, but sometimes I do. Aftertext gives me a new trick where I can just copy the text, and add the markup later, if needed. Keeping text and markup separate is useful because sometimes readers don't want the markup.
It is likely a very small fraction of readers that would care about this, of course. But perhaps it would be a set of power users who could make good use of it.
Speaking of power users, Aftertext might also be useful for tool builders. Imagine you are building a collaborative editor. With Aftertext, adding a link, bolding some text, adding a footnote, all are simple line insertions. It seems like Aftertext might be a nice simple core pattern for collaborative editing tools.
Version control tools are often line oriented. When markup and content are on the same line it's not as easy to see which changes were content related and which were markup related. In Aftertext, each markup change corresponds to a single changed line. In the future, I could imagine using AI writing assistants to add more links and enhancements to my posts while keeping the history of content lines untouched.
Finally, I should mention that it seems like keeping the written text and markup separate might make sense because it often matches the actual order in which writing text and marking up text happens. Writing is a human activity that goes back a thousand generations. Adding links is something only the current generations have done. A pattern I often find myself doing is: write first; add links later. Aftertext mirrors that behavior.
A Petri dish for new markup ideas
Aftertext provides a scalable way to add new markup ideas.
Simple markups like bolds or italics aren't a big pain and conventions like bold and italics used in languages like Markdown or Textile do a sufficient job. But even with those, after a certain amount of rules it's hard to keep track of what characters do what. You also have to worry about escaping rules. With Aftertext adding new markups does not increase the cognitive load on the writer.
When you get to more advanced markup ideas, Aftertext gives each markup node it's own scope for advanced functionality while keeping the text text.
I'm particularly interested in exploring new ways to do footnotes, sparklines, definitions, highlights and comments. Basic Aftertext might not be compelling on its own, but maybe it will be a useful tool for evolving a new "killer markup".
Adding a new markup command is just a few lines of code.
What are the downsides of Aftertext?
There are downsides in using Aftertext that you don't have with paired delimiter markups.
There is the issue of breakages when editing Aftertext. The nice thing about *bold* is that if you change the text between the delimiters you don't break formatting. When editing Aftertext by hand when you change formatted text you break formatting and have to update those lines separately. I hit this a lot. Surprisingly it hasn't bothered me. Not yet, at least. I need to wait and see how it feels in a few months.
A similar issue to the breakage problem is verbosity. Embedded markup adds a constant number of bytes per tag but with Aftertext the bytes increase linearly with N, the size of the span you are marking up. Again, I haven't found this to be a problem yet. Perhaps the downside is outweighed by the helpful nudge toward brevity. Or maybe I just haven't used it enough yet to be annoyed.
Another problem of Aftertext is when markup is semantic and not just an augmentation. *I* did not say that is different from I did not say *that*. Without embedded markup in these situations meaning could be lost.
What are the problems with the initial implementation?
My first implementation leaves a lot of decisions still to make. Right now Aftertext is only usable in aftertext nodes. That is a footgun. The current implementation uses exact match string selectors that only format the first hit. Another footgun. I've already hit both of those. And at least two or three more.
(Edit: these have been fixed.)
Is this a bad idea?
You might make the argument that not just the implementation, but the idea itself should be abandoned.
The most likely reason why this is a bad idea is that it simply doesn't matter whether it's a good idea or not. You could argue that improvements to markup syntax are inconsequential. That even if it was a 2x better way to markup text for some use cases, AIs will change writing and code in so many bigger ways that's it not even worth thinking about clean source anymore. This could very well be true (luckily it didn't take many hours to build).
Or perhaps it is a bad idea because although it may be mildly useful initially, it is actually an anti-pattern and instead of scaling well, will lead to a Wild West of complex colliding markups. I generally don't have the mental capacity to think too many moves ahead. So I fallback to inching my way forward with code and relying on the feedback of others smarter than me to warn of unforeseen obstacles.
Summary and Closing Thoughts
Markups on text may increase monotonically. With current patterns that means source will get messier and more complex. Aftertext is an alternative way to markup text which can scale while keeping source clean. Aftertext might be a good backend format for WYSIWYG GUIs. Though most humans write in WYSIWYG GUIs, Aftertext is designed for the small subset who prefer formats that are also maintainable by hand.
Related Work
Thank you to Kartik, Shalabh, Mariano, Joe and rau for pointing me to related work. I am certain there are similar efforts I have missed and am grateful for anyone who points those out to me via comments or email.
In 1997 Ted Nelson proposed parallel markup.
The text and the markup are treated as separate parallel members, presumably (but not necessarily) in different files.
When searching for '"parallel markup implementation"' I also came across a Wikipedia page titled Overlapping markup, which contains a number of related points.
A couple of folks mentioned similarities to troff directives. In a sense Aftertext is reimagining troff/groff 50 years later, when characters/bytes aren't so expensive anymore.
Brad Templeton describes two inventions, Proletext and OOB, to solve what he termed "Out of band encoding for HTML". They seem esolangy now but actually cleverly useful back in the day when bytes and keystrokes were more expensive.
The Codex project has a related idea called standoff properties. As I understand it, the Codex version uses character indexes for selectors which requires tooling to be practical and rules out hand editing.
AtJSON is a similar project and has clear documentation. AtJSON has a useful collection of markups evolved to support a large corpus of documents at CondeNast. AtJSON uses character indexes for selectors so hand editing is not practical.
Why now?
Issues with embedded markup and alternative solutions have been discussed for decades. I would say it's a safe bet to say embedded markup is superior since it so thoroughly dominates usage. Nevertheless, as I mentioned in my use case, there is a time and a place for alternatives. Aftertext would have been simple enough to understand decades ago and use with pen and paper. So why hasn't Aftertext's been tried before?
Verbosity is certainly a reason. Bytes, bandwidth, and keystrokes (pre-autocomplete) used to be more expensive, so Aftertext would have been inefficient. It probably was worthwhile to have a learning curve and force users to memorize cryptic acronyms. It paid off to minimize keystrokes.
I may also be overvaluing the importance of universal parsibility. I value formats that are easy to maintain by hand but also easy to write parsers for. Before GUIs, collaborative VCSs, IDEs, or AIs, there wasn't as much value to be gained by doing this. But even today I may be overvaluing hand editability. This seems to be the era of AIs and all apps editing JSON documents on the backend. I may be a dinosaur.
Finally, I may be overvaluing the clean scopes used by Aftertext provided by the underlying Tree Notation. Aftertext works because each text block gets its own scope for markup directives and each markup directive gets its own scope and you don't have to worry about matching brackets. So maybe Aftertext just hasn't been tried because I overvalue that trick.
Notes
- There's no reason it has to be "Aftertext". The markups could come before the text too.
- Thanks to justinpombrio for pointing out how semantic embedded markup is different than augmenting markup.
- Another downside of the current implementation, pointed out by David Chisnall, is the lack of a mechanism for global markup directives. I'd expect Aftertext to evolve in that direction if it proves its worth in the local scope.
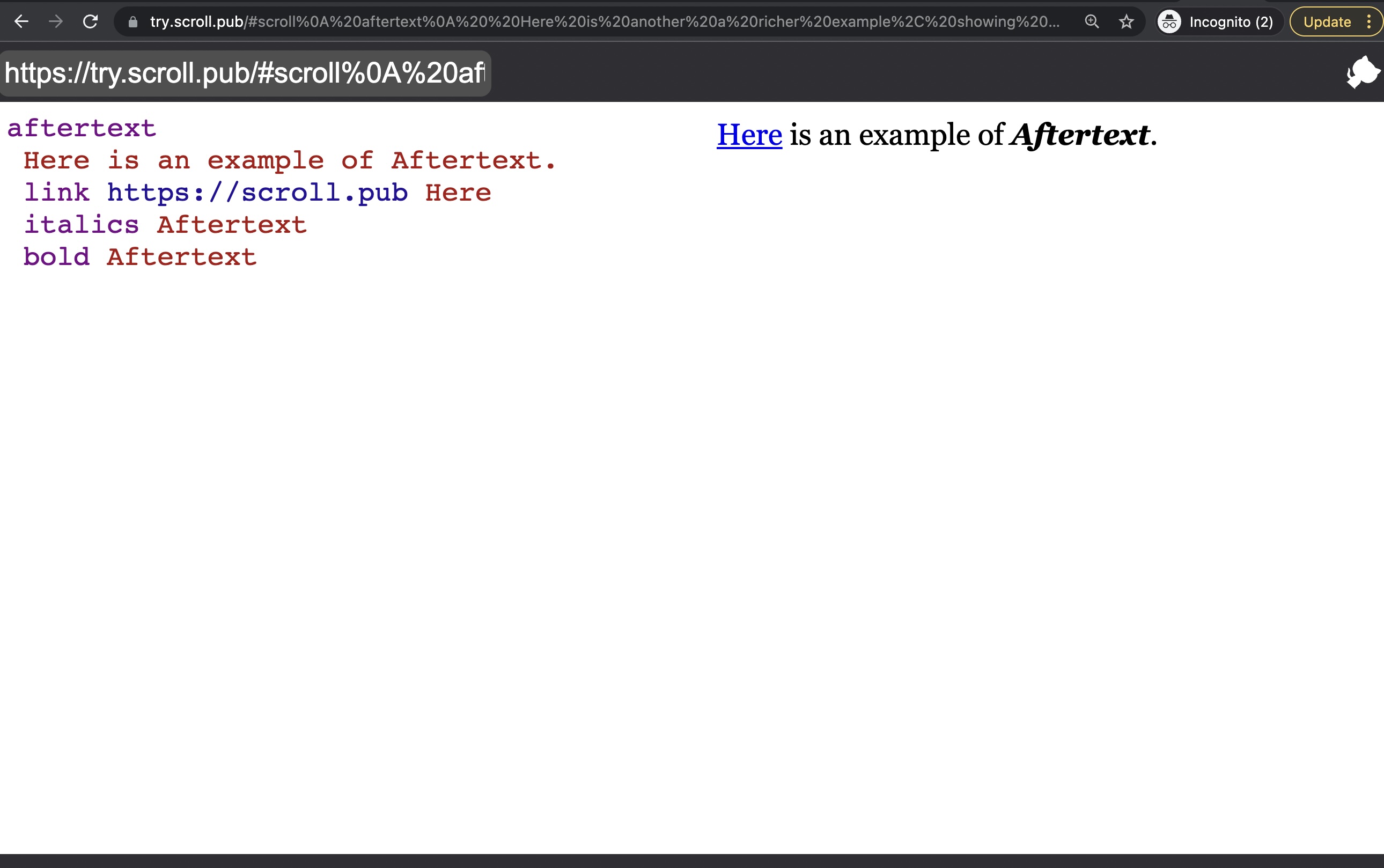
A screenshot of Aftertext on the left and the rendered HTML on the right.
by Breck Yunits
Writing this post with narrow columns in "Distraction Free Mode" on Sublime Text on my desktop in Honolulu.
October 15, 2021 — I constantly seek ways to improve my writing.
I want my writing to be meaningful, clear, memorable, and short.
And I want to write faster.
This takes practice and there aren't a lot of shortcuts.
But I did find one shortcut this year:
Set a thin column width in your editor
Mine is 36 characters (your ideal width may be different).
Beyond that my editor wraps lines.
This simple mechanic has perhaps doubled my writing speed and quality.
At my current font-size, my laptop screen could easily support 180 characters across.
But if my words spread across the full screen, I write slower and produce worse content.
Another way to frame this is that my writing got worse as my screens got wider and I only recently noticed the correlation.
How does column width affect writing speed?
When I am writing I am mostly reviewing.
I type a word once. But my eyes see it fifty times.
Maybe great writers can edit more in their heads. With my limited mental capabilities editing happens on the page. I do a little bit of writing; a lot of reviewing and deleting.
So the time I spend writing is dominated by the time I spend reviewing.
Reviewing is reading.
To write faster, I need to read faster.
Humans read thinner columns faster.
Perhaps this isn't the case for all people—I'm not an expert on what the full distribution looks like.
But my claim is backed by a big dataset.
I have my trusty copy of "The New York Times: The Complete Front Pages from 1851-2009". For over 150 years the editors at the New York Times, the most widely read newspaper on the planet, decided on thin columns.
If fatter columns were more readable we would have known by now.

The New York Times has thin columns. They were even thinner a century ago. In the 1800's, people had time on their hands. I'm sure the smartest writers and editors experimented with many column widths and determined thin was better.
Thinner columns help you read faster. Writing speed is dominated by reading speed. If you read faster, you write faster.
How does column width affect writing quality?
Every word in a great piece of writing survived a brutal game of natural selection. Every review by the author was a chance for each word to be eliminated. The quality of the surviving words are a function of how many times they were reviewed. If the author reviews their writing more, then the words that survive should be fitter.
But moving your eyes takes work. It might not seem like a lot to the amateur but may make a huge difference toward the extremes. A great athlete practices their mechanics. They figure out how to get maximal output for minimal exertion. They "let the racket do the work". If you are moving your eyes more than you have to, you are wasting energy and will not have the stamina to review your writing enough. So thinner columns leave you with more energy for more editing passes. More editing passes improves quality.
If your columns are really wide, then you are not just moving your eyes, you are moving your head.
The difference might not seem like much for one line, but if you read 1,000 lines, that energy adds up!
Nodding your head left and right once is easy. Doing it 2,000 times is tiring!
If column width has such a significant impact on writing speed, why have I not seen this stressed more?
I don't remember ever being told to use thinner columns when writing. In programming we often cap line length, but this is generally pitched for the benefit of future readers, not to help the authors at write time.
I have long overlooked the benefit of thin columns at write time. How could I have overlooked this? Two obvious explanations come to mind.
First, I could be wrong. Maybe this is not a general rule. I have not yet done much research. Heck, I haven't even done careful examination of my own data. I've been writing with narrow columns for about 10 months. It feels impactful, but I could be overestimating its impact on my own writing speed.
Second, I could be ignorant. Maybe this is already talked about plenty. I would not be surprised if a professional writer sees this and says "duh". Maybe it's taught in some basic "writing mechanics 101" introductory course. Maybe if I got my MFA or went to journalism school or worked at a newspaper this is a basic thing. Maybe that's why journalists carry those thin notepads.
But let's say my hunches are correct, that thin columns do help you write faster and that this is not mentioned much. If I'm correct on both of those counts, then a clear explanation for this is that this simply is a new potential hazard created by new technology.
My generation is the first to have access to big screens, and so in the past writing with wide columns wasn't a mistake people made because it simply wasn't possible. An alternative title I considered was "Write as fast as your grandparents by using the line length they used".
Jets are great, but beware jet lag when traveling. Big screens are great, but beware eye lag when writing. Try thin columns.
Notes
- I wonder if sometimes over the years when I felt "in the zone" while writing, it may have been partly a result of coincidentally using a narrow column width.
- I am a middling writer, so don't forget to weight this advice appropriately!
- The physical dimensions of my writing area on screen are about 2.5 out of 11 inches. I've skimmed some studies that suggest 4 inches is the optimum for most people.
- Some writing boxes never wrap, like Gmail. So to keep my columns thin I would manually insert line breaks. Manual line breaks were fragile for two reasons. First, when I revised the text I'd also have to revise the line breaks. Second, I coded the line breaks at write time with certain font and column settings. At read time those settings might differ. Multiple friends commented that I now wrote in haikus. I did consider for a moment that a reputation as someone who wrote only in haikus might be advantageous, but I ruled that out and stopped manual line breaks. Now I often write in Sublime Text and copy/paste into the target app.
Reader Comments
- Anton writes to say he thinks the reason for narrow columns in newspapers is to maximize text density for large texts. He also points me to a great read on ventilated prose, "in my opinion, it aides editing on the computer even better, while keeping the lines short."
August 11, 2021 — In this essay I'm going to talk about a design pattern in writing applications that requires effectively no extra work and more than triples the power of your code. It's one of the biggest wins I've found in programming and I don't think this pattern is emphasized enough. The tldr; is this:
When building applications, distinguish methods that will be called by the user.
The Missing Access Modifier
All Object Oriented Programmers are familiar with the concept of PrivateMethods and PublicMethods. PrivateMethods methods are functions called by programmers inside your class; PublicMethods are functions called by programmers outside your class. Private and Public (as well as Protected), are commonly called AccessModifiers and are ubitquitous in software engineering.
A UserMethod is a class method called by the user through a non-programmatic interface
UserMethods are all the entry points a user has to interact with your application. All interactions users have with your application can be represented by a sequence of calls to UserMethods.
An Example
Let's say I am writing a GUI email client application. I probably have an EmailClient class that can send an email, and then a "Send" Button. Using the UserMethod pattern I might have a private method perform the actual email sending work, and then I'd have a small UserMethod that the click on the button would call:
private _sendEmail():
// ...
user sendEmailCommand(...):
// ...
this._sendEmail()
That's it. In my pseudo code I used a "user" keyword to flag the UserMethod, but since most languages don't have such a keyword you can use either decorators or have an identifier convention that you reflect on.
Advice: When building applications, distinguish your UserMethods
If you are just building a library used by other programmers programmatically, then the public/private/protected access modifiers are likely sufficient. In those situations, your UserMethods are identical to your PublicMethods. But if there is a user facing component, some wisdom:
I have never seen a single application with a user facing component, whether it be a Graphical Interface, Command Line Interface, Voice Interface, et cetera, that doesn't benefit significantly from following the UserMethod Pattern.
Implementation Costs
The UserMethod pattern costs close to zero. All you need to do is add a single token or bit to each UserMethod. It might cost less than zero, because adding these single flags can help you reduce cognitive load and build your app faster than if you didn't conceptualize things in this way.
Off the top of my head, I can't think of a language that has a built in primitive for it (please send an email or submit a PR with them, as I'm sure there are many), but it's easy to add by convention.
If your language supports decorators and you like them, you can create a decorator to tag your UserMethods. Without decorators, it's easy to do with a simple convention in any language with reflection. For example, sometimes in plain Javascript I will follow the convention of suffixing UserMethods with something like "UserMethod". (Note: In practice I use the suffix "Command" rather than "UserMethod", for aesthetics, but in this essay will stick to calling them the latter).
Benefits
By simply adding a flag to each UserMethod you've now prepped your application to be used in lots of new ways.
Benefit: New Interfaces
By distinguishing my UserMethods, I've now done 80% of the leg work needed to support alternative interfaces—like command palettes, CLIs, keyboard shortcut interfaces, voice interfaces, context menus, et cetera. For example, by adding UserMethods to a component, I can then reflect and auto generate the context menu for that component:
I've now also got the bulk of a CLI. I just take the user's first argument and see if there's a UserMethod with that name to call. The help screen in the CLI below is generated by iterating over the UserMethods:
For a command palette, you can reflect on your UserMethods and provide the user with auto-complete or a drop down list of available commands.
With just a tiny extra bit of work—a single flag to distinguish UserMethods from PublicMethods, and a tiny bit of glue for each interface, you multiply the power of your application. The ROI on this pattern is extraordinary. It really is a rare gem. You do not see this kind of return often.
Benefit: Scriptability
You've also now done the bulk of the work to make a high level scriptable language for your application. You've identified the core methods and a script can be as simple as a text sequence listing the methods to call, along with any user inputs. Your UserMethods are a DSL for your application.
Benefit: Scripted Regression Testing
Your new UserMethod DSL can be very helpful when writing regression testing on situations a user ran into. A user's entire workflow can now be thought of as a sequence of UserMethod calls. You can log those and get automated repro steps. Or if logs are not available, you can listen to their case report and likely transcribe it into your UserMethod DSL. For example, below is a regression test to verify that a "Did You Mean" message appears after a sequence of user commands.

Benefit: As a Design Aide
When ideating, it can be helpful to ask "what UserMethod(s) are we missing"?
When editing, it is helpful to scan your entire UserMethod list and prune the commands that aren't popular or aren't needed, along with any resulting dead code.
Benefit: Rapid Prototyping
Getting GUI's right can be challenging and time consuming. There are severe space constraints and changes can have significant ripple effects. You often do a lot of work to nail the visuals for a new component which then sees little usage in the wild. It can be helpful to build the UserMethod first, expose it in a Command Palette or via Keyboard Shortcut Interface, and only if it then proves to be useful, design it into the GUI. I guess if you wanted to be extremely cost conscious you could add UserMethods that simply alert a user to "Coming Soon" before you even decide to implement it.
Benefit: Documentation
I find it helpful when reading application code to pay special attention to UserMethods. After all, these functions are why the application exists in the first place. That little extra flag provides a strong signal to the reader that these are key paths in an application.
Benefit: Analytics
You can easily add analytics to your whole application once you've tagged your UserMethods. In the past I've done it simply by adding a single line of code to a UserMethod decorator.
Objections
Is this an original idea?
Heck no. I picked up this pattern years ago. Probably from colleagues, or books, or by reading other's code. I forget exactly how many times I've read about it, under what names. I'm sure there are thirty two existing names for this pattern. I'm sure 9 of those even have Wikipedia articles. But this pattern is so magical, so so so helpful, I do not think I will be wasting anyone's time by bringing it up again in my own terms.
I've tried a lot of things, like having Command classes, or Application classes, and I've found the concept of function level UserMethods to be a killer pattern in my day-to-day work. You can always graduate to more fine separation later.
All that being said, I'm sure someone has written a much better piece that would jive better with my experience, and so would appreciate links to all related ideas. I'm always open to Pull Requests (or emails)!
Shouldn't this level of abstraction be done at the class level and not method level?
Isn't it better instead to have an "Application" class, where all public methods are considered to be UserMethods? I won't argue against that. However, it's not always clear where to draw the lines, especially in the early days of a project, and it's much easier to build such classes later if you've clearly delinated your UserMethods along the way.
Aren't UserMethods just a subset of PublicMethods?
Yes. But they are a special category of PublicMethod and it's a distinction worth making. You want all your UserMethods available programmatically like the rest of your PublicMethods (for example, when writing tests), but you wouldn't want to show your users all PublicMethods in something like a Command Palette.
May 22, 2021 — In this video Dmitry Puchkov interviews Alexandra Elbakian. I do not speak Russian but had it translated. This is a first draft, the translation needs a lot of work, but perhaps it can be skimmed for interesting quotes. If you have a link to a better transcript, or can improve this one, pull requests are welcome (My whole site is public domain, and the source is on GitHub).
chat
hey. I just added Dialogues to Scrolldown.
cool. But what's Scrolldown?
Scrolldown is a new alternative to Markdown that is easier to extend.
how is it easier to extend?
because it's a tree language and tree languages are highly composable. for example, adding dialogues was a simple append of 11 lines of parser code and 16 lines of CSS.
okay, how do I use this new feature?
the source is below!
May 14, 2021 — Dialogues seem to be a really common pattern in books and writings throughout history. So Scroll now supports that.
Here is the parser in the commit that added support for Dialogues:
Links
- Try Scroll: https://scroll.pub
- Chat CSS style inspiration: https://codepen.io/karolsw3/pen/KZmvGG
New: let's get to work! Join the subreddit
May 12, 2021 — If you've thought deeply about copyrights and patents, you've probably figured out that they are bad for progress and deeply unjust. This post is for you.
(If you are new to this issues, you might be more interested in my other posts on Intellectual Freedom)
A Proposal
I suggest we organize around a simple long-term vision of passing a new Amendment to the U.S. Constitution ending patents and copyrights once and for all.
The below proposal is 34 words.
Section 1. Article I, Section 8, Clause 8 of this Constitution is hereby repealed. Section 2. Congress shall make no law granting monopolies on ideas, knowledge, or inventions, or prohibiting the free use thereof.
I have only passed a handful of Amendments to the U.S. Constitution in my lifetime 😉, so discussion welcome.
Notes
I am not 100% certain that if we abolished copyright and patent systems the world would be a better place.
It would be intellectually dishonest of me to say that. I am always open to intelligent experiments that would show otherwise.
But at this point I am 99% confident it would be the single most massive positive improvement we can make in our world, based on empirical evidence and theoretical math.
It would take a lot of thought to do it right, but I know we could pull the transition off without as much disruption as people fear.
The bigger problem is this debate is not being had.
The problem is our side needs a better starting position.
When the debate is on details like what is the ideal length of monopolies, or when illogical terms like "Intellectual Property" are used, you've already conceded too much, and are giving up your strongest weapon: truth.
A stronger and more logical place to have the debate is upstream of that: debate whether we should have these systems at all.
I think the Amendment Strategy is clear enough, concrete enough, simple enough that you could get critical mass and start moving the debate upstream.
The best defense is a good offense. It's an adage, but there's usually some truth to adages.

You can honestly say The Bill of Rights outlaws copyright, but let's pass the IFA just to be clear.

I failed Aaron two times. The first when I was working with him to run his Python scripts at Duke (I was a new programmer at the time and pinged him with many questions). The second was when I did nothing when he was being prosecuted for liberating ideas to liberate minds. I will not fail him a third time.
The kind of people I think may be ready to organize would be lovers of open source, Linux, Sci-Hub, the Internet Archive, OG Napster; the followers of Aaron Swartz, Alexandra Elbakian and Stephan Kinsella; and all that truly love ideas and believe every human should get their own copy of humanity's most intelligent information.
May 7, 2021 — I found it mildly interesting to dig up my earlier blogs and put them in this git. This folder contains some old blogs started in 2007 and 2009. This would not have been possible without the Internet Archive's Machine heart ❤️.
August 2007 - Running Wordpress on my own domain
It looks like I registered breckyunits.com on August 24th, 2007. It appears I used Wordpress SEP 2007. There's a Flash widget on there. The title of the site is "The Best Blog on the Internet". I think it was a good joke. I had just recently graduated college, and had not yet moved to the West Coast.
July 2009 - Two years of Wordpress
About two years later, my Wordpress blog had grown to many pages JUL 2009.
August 2009 - Switched to Posterous
Looks like I started transitioning to a new site AUG 2009 , and moved my blog from my own server running Wordpress to posterous MAR 2013.
After I moved to posterous, I put up this homepage SEP 2009.
December 2009 - Switched to Brecksblog
In December 2009 I wrote my own blog software called brecksblog. Here's what my new site looked like DEC 2009.
I kept it simple. My current homepage now powered by Scroll evolved from brecksblog.
December 2009 - My "Computer science" blog
It looks like I also maintained a programming blog from December 2009 to January 2012 MAY 2012. Here is that blog migrated to Scroll.
May 6, 2021 — I split advice into two categories:
- 🥠 WeakAdvice
- 💎📊🧪 StrongAdvice.
Examples
WeakAdvice:
🥠 Reading is to the mind what exercise is to the body.
🥠 Talking to users is the most important thing a startup can do.
StrongAdvice:
💎📊🧪 In my whole life, I have known no wise people (over a broad subject matter area) who didn't read all the time – none, zero.
💎📊🧪 I don't know of a single case of a startup that felt they spent too much time talking to users.
💎📊🧪 Every single person I’ve interviewed thus far, even those working with billions of dollars, have all sent cold emails.
If you only look at certain dimensions, you may conclude the WeakAdvice is better.
WeakAdvice is shorter and does not have an author's name.
But all things considered, StrongAdvice is 100x better.
Defining StrongAdvice
StrongAdvice is advice that is concise, derived from data, and easy to falsify.
- 💎 Concise
- 📊 Derived from data
- 🧪 Easy to falsify
Unlike WeakAdvice, StrongAdvice needs to be backed by a large dataset.
Example
In 2009 I wrote:
🥠 to master programming, it might take you 10,000 hours of being actively coding or thinking about coding.
Ten years later, I now have the data to write:
💎📊🧪 Every programmer I respect the most has practiced more than 30,000 hours[1].
Even though the message is the same, the latter introduces a dataset to the problem and is instantly testable.
StrongAdvice can't just be the inclusion of a dataset. It should be constructed to provide instant testability.
Without the testability Munger's quote would be WeakAdvice:
🥠 I've met hundreds of wise people who read all the time
A testable version is a 1,000x stronger signal. If Munger, who likely met more wise people than nearly anyone, never came across an instance of someone wise who didn't read all the time, it's a pretty strong signal that reading is a requirement for being wise.
Versus the WeakAdvice version, which would also be true if it was just a slight correlation.
Sometimes you see WeakAdvice evolve into StrongAdvice, where an advisor hasn't quite made it instantly testable yet but is proposing a way for the reader to test:
💎📊 If you look at a broad cross-section of startups -- say, 30 or 40 or more; which of team, product, or market is most important?...market is the most important factor in a startup's success or failure.
Coming up with StrongAdvice requires time.
Like a good Proof of Work algorithm, StrongAdvice is hard to generate but easy to test.
I know Charlie Munger has met thousands of "wise people". All it would take would be for me to find just a single one that didn't read all the time to invalidate his advice. But I can't.
I know Jessica Livingston knows thousands of startups and I just need to find one who regrets spending so much time talking to users. But I can't.
If you have a lot of experience, I urge you to chew on your WeakAdvice until you can form it into StrongAdvice.
StrongAdvice is perhaps the most valuable contribution to our common blockchain.
My back of the envelope guess is that 99.9% of advice is written in WeakAdvice.
WeakAdvice is valuable for changing your perspective.
WeakAdvice is good for ideating.
Nothing wrong with WeakAdvice.
But it's worth a lot less than StrongAdvice.
Mistakes happen when people treat WeakAdvice like StrongAdvice.
Bad advice is a mistake on the reader's part, not the writer's.
Most "bad advice" has a famous person on one end, simply because they are constantly hounded for advice.
Mostly they'll give out WeakAdvice, since new StrongAdvice take time to create.
When you can quickly identify the difference between WeakAdvice and StrongAdvice, you're less likely to make the mistake of blindly betting on WeakAdvice.
It's safe to use WeakAdvice for ideating but not for decision making.
StrongAdvice you can bet on.
Notes
[1] There are a lot of programmers who have 10,000 hours of experience that I respect a lot and enjoy working with, but the ones I study the most are the ones who stuck with it (and also just lucky enough to live long lives).
April 26, 2021 — I invented a new word: Logeracy[1]. I define it as the ability to think in logarithms. It mirrors the word literacy.
Someone literate is fluent with reading and writing. Someone logerate is fluent with orders of magnitudes and the ubiquitous mathematical functions that dominate our universe.
Someone literate can take an idea and break it down into the correct symbols and words, someone logerate can take an idea and break it down into the correct classes and orders of magnitude.
Someone literate is fluent with terms like verb and noun and adjective. Someone logerate is fluent with terms like exponent and power law and base and factorial and black swan.
Someone literate can read an article and determine whether it makes sense grammatically. Someone logerate can read an article and determine whether it makes sense logarithmically.
Someone literate can read and write an address on the front of the envelope. Someone logerate can use the back of the envelope.
Illogeracy
The opposite of logeracy is illogeracy: the inability to think in logarithms. An illogerate person is one who frequently gets the orders of magnitude wrong.
An illogerate person may correctly understand parts 2 and 3 of a 3 term equation but get the first time-dependent part wrong and so get the whole thing wrong.
An illogerate person can be penny wise pound foolish.
An illogerate person treats all parts of an argument as important.
An illogerate person may mistake one part of a sin wave for a trend.
An illogerate is one who may be familiar with exponentials but unfamiliar with sigmoids
Measuring Logeracy
No country or organization measures logeracy yet[2]. I don't know which countries are the most logerate, but for now I would guess there will be a strong correlation between the engineering prowess of a country and it's level of logeracy.
Countries have been measuring literacy for hundreds of years now. As the chart above shows, the world has made great progress in reducing illiteracy. 200 years ago, ~90% of the world was illiterate. Now that's down to ~10%. If you break it down further by country, you'll see that in countries like Japan and the United States literacy is over 99%.
The upside of logeracy
Logeracy is how engineering works. Good engineers fluently and effortlessly work across scales. If we want to be an interplanetary species, we first must become a more logerate species.
Logeracy makes decision making simple and fast (figure out the classes of the options, and then the decision should be obvious).
You don't get wealthy without logeracy. An illogerate and his money are soon parted. Compound interest is a tool of the logerate. Money doesn't buy happiness, but the logarithm of money does.
Where is logeracy currently taught well?
My knowledge here is limited. I know Computer Science students could be the ones taught logeracy best. We are taught it by a different name. CS students are repeatedly taught to think in Big O notation[3]. In Computer Science you are constantly working with phenomena across vastly different scales so logeracy is critical if you want to be successful.
Perhaps its electrical engineers, or astronomers, or aerospace engineers. These folks are frequently working with vast scale differences so logeracy is required.
In finance, 100% of successful early stage technology investors I know of are highly logerate.
It would be interesting to see logeracy rates across industries. Perhaps measuring that would lead to progress.
How much logeracy is the average person taught?
My high school chemistry teacher first exposed me to logeracy when she taught me Scientific Notation. That was probably the only real drilling I got in logeracy before getting into Computer Science. Scientific Notation is a handy notation and a great introduction to logeracy, but logeracy is so important that it probably deserves its own dedicated class in high schools where it is drilled repeatedly from many difference perspectives.
What are some good books for improving logeracy?
I would recommend "The Art of Doing Science and Engineering: Learning to Learn" by Hamming. That's maybe the most logerate book I've ever read. I also love Taleb's Incerto series (ie Fooled by Randomness, Black Swan, Antifragile...).
Is logeracy fractal?
Yes[4]. Some industries, like engineering, demand logeracy. A randomly selected engineer is likely to be 10x+ more logerate than a randomly selected member of the general population. But what about the distribution of logeracy within a field? Only recently did it occur to me how fractal logeracy is. A surprising number of engineers I've worked with seem to compartmentalize their logerate thinking to their work and act illogerate in fields outside of their own. In Hamming's book I was surprised to read over and over again how very few engineers he worked with (at the world's top "logerate" organizations) operated with his level of logeracy. Logeracy seems fractal.
Can you be too logerate?
I don't think so. However, I do believe you can be out of balance. One needs to be linerate[5] as well as logerate. We have so many adages for people that focus too much on the dominant-in-time term of an equation and not enough about the linear but dominant-now parts. Adages like "head in the clouds", "crackpot", "ahead of her time". We also have common wisdom for how to avoid that trap "a journey of a single step...", "do things that don't scale", so it is likely that being extremely logerate without lineracy is a real pitfall to be aware of.
What about the term Numeracy?
I read Innumeracy and Beyond Numeracy by Paulos over a decade ago[6]. I love those books (and it's been too long since I reread them).
Numeracy is a good term. Logeracy is a much better term. Someone logerate but innumerate often makes small mistakes. Someone numerate but illogerate often makes large mistakes.
Numeracy is sort of like knowing the letters of the alphabet. Knowing the letters is a necessary thing on the path to literacy, but not that useful by itself. Likewise, being numerate is a step to being logerate, but the real bang for your buck comes with logeracy.
The Illogeracy Epidemic
Literacy without logeracy is dangerous. My back-of-the-envelope guess is that over 80% of writers and editors in today's media are illogerate (or perhaps are just acting like it in public). 2020 was an eye opening year for me. I had vastly underestimated how prevalent illogeracy was in our society. I am tired of talking about the pandemic, but to this day in the news I see a steady stream of "leaders" obliviously promoting their illogeracy, and walking around outside I see a huge percentage of my fellow citizens demonstrating the same. I would guess currently over 60% of America is illogerate. The funny thing is it may be correlated with education—if you are educated as a non-engineer you perhaps are more likely to be illogerate than a high school dropout, because you rely too much on your literacy and are oblivious to your illogeracy. I am very interested to see data on rates of logeracy.
Let's get to 99%+ logeracy
I wrote my first post on Orders of Magnitudes nearly twelve years ago, back in 2009. At the time I didn't have a concise way to put it, so instead I advised "think in Orders of Magnitude". Now I have a better way to put it: become logerate. I wonder what wonderful things humankind will achieve when we have logeracy rates like our literacy rates.
Related Posts
Notes
[1] I was very surprised to be the one to invent the word logeracy(proof). Only needed to change 2 letters in a popular word. All the TLDs including dot coms are still available.
[2] As far as I can tell. If you know of population measures of logeracy please email me or send a pull request.
[3] Even if you are familiar with Big O Notation, the orders of common functions table is a handy thing to periodically refresh on.
[4] Is my guess, anyway.
[5] Uh oh, another coinage.
[6] In my recollection Innumeracy is too broad a book. This critique applies to 99% of books I read, Hamming's book being one of the exceptions
March 30, 2021 — The CDC, NIH, etc, need to move to Git. (For the rest of this post, I'll just say CDC, but this applies to all public health research agencies). The CDC needs to move pretty much everything to Git. And they should do it with urgency. They should make it a priority to never again publish anything without a link to a Git repo. Not just papers, but also datasets and press releases. It doesn't matter under what account or on what service the repos are republished to; what matters is that every CDC publication needs a link to a backing Git repo.
How do you explain Git to a government leader?
Git is the "Global Information Tracker". It is software that does three things that anyone can understand 1) git makes lying hard 2) git makes sharing the truth easy 3) git makes fixing mistakes easy.
Why does the CDC need to move to Git?
Because the CDC's publications are currently full of misrepresentations, make it very hard to share the truth, and are full of hard to fix mistakes. Preprints, Weekly Reports, FAQs, press releases, all of these things need links to the Gits.
Who builds on Git?
The whole world now builds on Git. The CDC is far behind the times. Even Microsoft Windows, the biggest proprietary software project in the world, now builds on Git.
What is Git?
Git is an open source, very fast, very powerful piece of software originally created by Linus Torvalds (the same guy who created Linux) and led by Junio C Hamano that makes extensive use of principles from blockchain and information theory.
How can the CDC rapidly move to Git?
Double Down on Internal Leaders
The CDC's GitHub account has 169 repos and 10 people (and I'm told many hundreds more Git users). I would immediately promote every person working on these repos. (There are probably one or two jokers in there but who cares, it won't matter, just promote them all). Give them everything they need to be successful. Give them raises. Tell them part of their new job is to get everything the CDC is invovled with published to Git. This is probably really the only thing you need to do, and these people can lead it from there.
Change Funding Requirements
Provide a hard deadline announcing that you will stop all funding for any current grant recipient, researcher, or company doing business of any kind who isn't putting their sponsored work on a publically available Git server and linking to it in all releases.
Education and Training
The CDC has 10,600 employees, so buying them all $20 worth of great paper books on learning how to use Git would only cost $201,200. For the most part, these are highly educated people who are autodidacts and can probably learn enough with just some books and websites, but for those who learn better via courses or videos you can budget another $30 per person for those. Then budget to ensure everyone is paid for the time spent learning. We are still talking about far less than 1% of the CDC's annual budget.
Why the urgency?
Because the CDC not only failed at it's mission by not stopping COVID, but it continues to mishandle it. Mistake after mistake. Miscommunication after miscommunication. I just shook my head looking over an amateur hour report that they just put out. It's sad and their number one priority should be to regain trust and to do that they need to focus on the most trustworthy tool in information today: git.
Specific Examples
I'm adding two very clear and specific examples to illustrate the problem. But my sense is the problem is prolific.
#1 - COVID-19 in kids vs the Flu
For young children, especially children younger than 5 years old, the risk of serious complications is higher for flu compared with COVID-19.CDC
This statement appeared on the CDC's website for more than a year. As it should have. Every big dataset I've looked at agrees with this, from the very first COVID-19 data dump in February 2020.
I started actively sharing and quoting that CDC page in August 2021. Coincidentally or not, within days they removed that quote. There is no record of why they made the change. In fact the updated page misleadingly states "Page last reviewed: June 7, 2021", despite the August edit*.
To recap, they quietly reversed the most critical piece of contextual advice on how parents should think about COVID-19 in relation to their children. No record, no explanation. (In case you are wondering, the data has not changed, and the latest data aligns with the original statement which they removed. Perhaps the change was made for political reasons).
#2 - Changing the definition of vaccine
The second example is well documented elsewhere, but the CDC changed their online definition of the word "vaccine", again perhaps for political reasons. That sort of thing seems like the kind of change that maybe should have some audit trail behind it, no?
Conclusion
I used to take it for granted that we could trust the CDC. That made life easier. Health is so important but so, so complex. I would love to trust them again, and would have more confidence if they were using the best tools for trust we have.

Notes
- Perhaps by "reviewed", they mean experts last reviewed it then, and all subsequent changes were made by an intern, on their own, which I also don't think would be a good explanation.
Introduction
March 11, 2021 — I have been a FitBit user for many years but did not know the story behind the company. Recently came across a podcast by Guy Raz called How I Built This. In this episode he interviews James Park who explains the story of FitBit.
I loved the story so much but couldn't find a transcript, so made the one below. Subtitles (and all mistakes) added by me.
Transcript of How I Built This with James Park

Guy: From NPR, It's How I Built This. A show about innovators, entrepreneurs, idealists, and the stories behind the movements. Here we go. I'm Guy Raz, and on the show today, how the Nintendo Wii inspired James Park to build a device and then a company that would have a huge and lasting influence on the health and fitness industry, Fitbit.
It's taken me a few weeks to get motivated about exercise. This whole pandemic thing just had me in a state of anxiety and it messed with my routine, but I was inspired to jump back into it about two weeks ago, after watching my 11-year-old proudly announce his daily step count recorded on his Fitbit. Now, fitness isn't all that important to him. He's 11. But the gamification of fitness, the idea that it could be fun to hit 5,000 or 10,000 steps a day, that's what matters.
This is the stroke of insight James Park had soon after he stood in line at a Best Buy in San Francisco to buy the brand new video game system called Nintendo Wii. And you'll hear James explain the story a bit later, but what he realized playing the Wii is that you could actually change human behavior around exercise if you turned it into a game. And the thing is, up until James Park and his co-founder Eric Friedman founded Fitbit in 2007, there really weren't any digital fitness trackers that were designed that way. It took a few years for James and Eric to gain traction, but by 2010, 2011, Fitbit took off. At one point, their fitness devices accounted for nearly 70% of the market. And by 2015, the company was valued at more than $10 billion. But that same year, the Apple Watch was released, and Fitbit and its market share got hammered. When I spoke to James Park a few days ago, he was in San Francisco, living in an Airbnb.
James: I'm in a temporary Airbnb because the place that I typically live in has been flooded out by a malfunctioning washing machine. I woke up at it 1:00 AM
Guy: In the middle of this whole thing, flooded washing machine went... You woke up in the middle of the night and there was water everywhere?
James: I know. Amazing timing. Yeah. I woke up at 1:00 AM, and I just woke up to the sound of water gushing everywhere. It was coming through the ceiling. It was a massive flood.
Guy: Okay. So on top of sheltering in place and running his company remotely, James had to move out of his apartment in the middle of the night and then set up the microphone and gear we sent him for this interview. He started to tell us about his parents who immigrated from Korea when James was four. Back in Korea, his dad had been an electrical engineer and his mom was a nurse. But as with many immigrants, they had a hard time getting those same jobs in the US. So instead, his parents became small business owners.
Growing Up (1977)
James: The first conscious memory I have is, my parents actually own the wig shop in downtown Cleveland.
Guy: Wow. How did they get into that? Was it just a way to earn a living?
James: Yeah. I think a way to earn a living and the typical immigrant story is you have friends who live in the country that you're immigrating to. And I think my dad had a friend who worked in wig wholesaling. That's where he started out. There were selling wigs to people who live in downtown Cleveland, African-Americans, mostly women. And I remember my mom, she'd spend a lot of time just looking through black fashion magazine, styling hair, beating them, et cetera.
Guy: Wow.
James: They had a wig shop, dry cleaners, a fish market. At one point we moved to Atlanta and they ran an ice cream shop there. We sold track suits, starter jackets, fitted baseball caps, thick gold chains.
Guy: Sort of hip-hop urban wear, right? Like FUBU, and stuff like that?
James: Yeah. Yeah. Yep. They sold FUBU jeans. Yep. I remember that. And they could switch from one genre or one type of business to another and really not skip a beat.
Guy: And were your parents, did they expect you perform well at school? Was that just a given?
James: I think they had incredibly high expectations then as a kid. I think I remember my mom telling me when I was pretty young, I don't know, five, six, seven, that she expected me to go to Harvard.
Guy: Wow.
James: Yeah. I don't think I quite knew what that meant back then, but you could tell that their expectations were pretty high from the very beginning.
Dropping out of Harvard (1998)
Guy: James did in fact meet his mom's expectations. He did go to Harvard. He put in three years studying computer science, but after his junior year, he got a summer internship at Morgan Stanley and then ended up deciding to start his own business. And then we had hoped to finish his college degree, he never went back.
James: I always had a little bit of a stubborn streak, and that was when I was trying to figure things out, try to think of ideas. I think there is a lot of opportunity, a lot of problems to be solved. I was also looking for a co-founder at the time. So those are two critical ingredients, an idea and a co-founder.
Guy: This is 1998. This is not 2015 when these kinds of conversations seem so common. This was unusual in 1998 for a young person. It was just less common for a young person to just sort of say, "I'm going to look into a tech startup and try to find a co-founder and just take some time to think about these things." I would imagine your parents were nervous. I'd be nervous if my 20-year-old said to me, "I'm not going to go back to college and I don't really know what I'm going to do, but I'm just going to think about it."
James: Yeah. They were understandably pretty upset, angry even I'd say. And the irony is that, they probably took away more incredible personal risk moving from Korea to United States and running these series of businesses, which are commonly done, but not easy in themselves and pretty high risk. But I do understand obviously the perspective at the time.
The eCommerce Start Up
Guy: Okay. You decide you want to start something up, and I think you eventually landed on e-commerce, right?
James: Yeah. That was not a groundbreaking thing at the time. Obviously, Amazon was around, et cetera. A lot of e-commerce startups, but settled on this idea of making e-commerce a lot more seamless and frictionless and came up at this idea of a electronic wallet that would automatically make purchases for you. It would work with a lot of different e-commerce sites and the goal there was that we would take a cut of every transaction.
Guy: Right. And what was the company called?
James: That was interesting. We originally named it Kapoof, that was how it was incorporated, until a lot of people said, "That might not be the best name for a company." Sounds like, we called it Kapoof because it sounded like magic, et cetera, Kapoof. Things are done. Your transaction is completed by Kapoof.
Guy: It sounds like, "Kapoof, your money is gone."
James: Yeah, exactly.
Guy: "You've no more money."
James: Exactly. Time of crazy names like Yahoo, et cetera. But we decided to change our name at some point and we changed it to Epesi, which was so Swahili for fast. And so that was the ultimate name of the company.
Raising a "few million" dollars
Guy: And you guys were actually able to raise a fair amount of money. Right?
James: We did. We ended up raising a few million dollars from some individuals and some from some venture capital firms as well. And we hired some people. We found a cool renovated firehouse. That was-
Guy: Nice. Nice
James: ... Really amazing place to hang out in for many, many, many hours of the day. And we hired up to, it was close to about 30 people.
Meeting his eventual FitBit cofounder
Guy: Wow. One super important thing that happened there was you met Eric Friedman, right? The guy that you would eventually launch Fitbit with.
James: I did. And that's probably one of the more fortunate turns in my life. Eric, we didn't know each other at all before the company, Epesi. He was actually just graduating from Yale in computer science. And I interviewed him. I liked him a lot. And he ended up ultimately becoming the first employee at the company.
Guy: Okay. So you hire Eric, and I think the company lasted 18 months, or a little less than two years.
James: Yeah. About two years, and a lot of ups and downs during that period. If I had to think back, I would attribute two-thirds of the challenges and problems we faced as a business to myself, just because I had never managed people. I didn't really know how to run a business, even it was only the technology side. And at some point the dot-com crash happened. And all of our potential customers, the whole industry, the whole economy started taking a downturn.
Dot Com Bust (2001)
Guy: So this company spirals out in 2001. And when that happened, did you think, "Okay, I should go back to college now and finish my degree." Or, "I got to start something else." Where was your head at that point?
James: Well, it was a really challenging personal time for me. Towards the end of the company, we obviously had to lay off most of the company, and trying to doing it in a way that was compassionate was really, really difficult. I don't think the thought of entering school or going back to school popped back into my head at all. And I don't know why. I think it was because, despite this very emotional failure, I knew this was what I wanted to do. I had a firm conviction about that. And so I knew I wasn't going to go back.
Guy: So what'd you do?
Getting Real Jobs
James: We all ended up working at the same place actually. It was a company, a pretty large company called Dun & Bradstreet at the time. Very stable company. And we were all fortunate to be able to find work there as engineers.
Guy: So daytime working at Dun & Bradstreet, and then what? At night sitting around just-
James: Brainstorming. Yeah. We go into work during the daytime and then we'd come home in the evenings, code different things, try different things out. So it was a pretty intense. I think, in terms of the numbers of hours, I don't think anything changed from our first startup to trying to figure this next one out.
Startup #2 (2002)
Guy: And before too long, you decide to do another startup. This time, with Eric Friedman from your previous company, and then another guy named Gokhan Kutlu. I think this was what? 2003, 2004?
James: Yeah. This was about 2002 actually.
Guy: Okay. And this time the startup was a photo editing platform, sharing platform. What was it called?
James: The company's name at the time was called HeyPix and the product itself was called electric shoe box because a lot of people put their old photos in shoe boxes and this was just going to be a digital.
Guy: Yes. I still have them in shoe boxes.
James: You'll digitize them probably.
Guy: I should. I know.
James: Yeah. And so electric shoe box, which is going to be a digital version of your shoe box.
Guy: And what could you do?
James: Well, there are digital cameras were coming about back then. It still wasn't easy to connect them, upload photos. It was getting easier, but nowhere near what it is today, obviously. The whole idea of electric shoe box was to make the whole process of getting photos off your camera a lot easier. And more importantly, we wanted to make the process of sharing these photos with your friends and family a lot easier.
Guy: So did you raise money for the product, for the electric shoe box?
James: We did. We ended up raising money primarily from one of my friends from middle school who was a mutual fund manager in Boston. And so, he put in a bit of money, not a lot. I think about, at least for him, it was about 100,000. And we had a bunch of savings ourselves that we were going to use. And in anticipation, I also opened up a few more credit cards as well.
Guy: And it was just really the three of you, sitting at your computers and just tapping the keys all night?
James: You pretty much nailed it. I mean, all we did was, we would wake up in the morning, walk over to the third bedroom and just start typing away for 12 hours. We'd take meal breaks. I remember Eric did a lot of cooking. So we'd eat our dinners on some TV stands watching TV. That was a good break for us, watching Seinfeld, and then go to bed and then repeat it the following day.
Guy: Wow. All right. So you come up with this product, and by the way, how are you going to make money off of this thing? This is a free service. How were you going to pay for it?
James: I guess, it would be called freemium software. It would be free for a period of time, and the trial period would end and then you'd have to submit your credit card information to continue using the software.
Guy: Got it. Got it.
The pivotal $300 Press Release
James: And so, our primary goal was making sure that a lot of people knew about the software. So we put it on shareware sites, et cetera. And then we spent a lot of time debating, "Should we send out a press release?" And I remember it was a huge debate because sending out a press release was going to be about $300. And that was the level of expense that required a vigorous debate at the time. So we said, "You know what? Without getting the product known, how are we going to be successful?" So we wrote up a press release and we put it out. And actually it was probably the most pivotal decision we ever made in that company's history.
Guy: Because?
James: The first email came in a few hours later. I think the second one came in a day later. But we got two emails, one from CNET, which is a huge digital publishing company. And then we got another email from Yahoo saying, "Hey, we just heard about this launch of this software product. And we'd like to talk to you guys more about it."
Guy: Wow.
James: Exactly. This was coming from their corporate development arms, which typically deals with M&A, with buying, buying companies.
James: Yeah, exactly. We were like, "Whoa, this is magic. How did this happen?"
Bought by CNET for millions (2005)
Guy: 2005, it gets purchased by CNET. They make an offer to buy this company, buy this product from you guys and you sell it to CNET. Was that life-changing money? Did that mean that you never had to work again?
James: It was definitely a good acquisition for all of us at the time. Remember we were three guys working out of our apartments. I was at the time about $40,000 in credit card debt as well. We were down to some desperate times and we were negotiating numbers and they threw out a number which was, their first offer was 4 million, and we were like, "Whoa, that's amazing."
Guy: Wow.
James: Like, "God, I can't believe we built something that's worth this much at the time." We were just stunned. And then, we quickly got to, "Okay, how do we negotiate something better?"
Guy: So you sell your company to CNET in 2005 and you've got some money in your pocket. And you move to San Francisco to work for CNET. Did you enjoy it? I mean, it was probably a huge company at this point, right?
James: It was a huge company, but I think the moment, at least for me, that I moved to San Francisco, I instantly fell in love with the city. And CNET, even though was a larger company, I actually found it to be an amazing time. I learned a lot. I got some management training. I ended up managing a small team of people. Learned a lot about how technology scales to millions and millions of users. How you market products. I really enjoyed my experience there. I think it was pretty formative.
Nintendo Wii and Leaving CNET (2007)
Guy: Why did you leave CNET?
James: We left CNET just because of, I guess you could call it a bolt of lightning in some ways. It was December of 2006 and Nintendo had just announced the Nintendo Wii. And I remember coming home, putting it together. At the time Nintendo had come up with this really innovative control system, using motion sensors, accelerometers to serve as inputs into a game. And after using it, especially in Wii Fit, which was a sports game. I thought, "Wow, this is incredible. This is amazing. This is magical. You can use sensors in this way. You can use it to bring people together." Particularly for Wii Fit, it was a way of getting people active, of getting them moving together. And I was just blown away by this whole idea, really excited about. I couldn't stop thinking about it.
James: And after some time of playing Wii Fit and the Wii and a lot of other games, I thought, "This is great. It's in my living room, but what if I want to take this outside of the living room?" And I kept thinking about that idea, like-
Guy: "How do you take Wii Fit outside?"
James: Outside. Exactly.
Guy: Wow.
The Genesis of Fitbit (2007
James: I couldn't let it go. And I ultimately ended up calling up Eric and we started talking about this idea for hours and hours and we couldn't stop talking about it. It's like, "How do we capture this magic and make it more portable? How do we give it to people 24-7?" And that was really the Genesis of Fitbit.
Guy: So the technology, I mean, pedometers have been around forever. Was that where your head was going, or thinking, "Okay, maybe we just create an electronic pedometer?" But I think even electronic pedometers were around in 2007, right?
Existing Pedometer
James: Yeah. Pedometers were definitely around back then. Actually, they had been around for probably 100 years. One of the things though is that, they weren't something that people would want to use or to wear. They were very big. They were pretty ugly. They looked like medical devices.
Guy: A lot of senior citizens used them.
James: Yeah. They weren't a very aspirational device. It wasn't something that people were excited to use. And so, I think that's why that whole category of device just never really had any innovation. And there are also much higher-end devices. You could buy much fancier running watches, like GPS watches, et cetera. But those are really expensive for people. There are 300, $400 at the time.
Guy: So you had this idea, and that means you had to raise money. And this is going to be the third time now that you've had to do that for a business. And I think I read that you raised $400,000 to launch this. I mean, I don't know a lot about hardware, but that doesn't seem like it was going to take you very far in building a physical product.
James: As we quickly found out, yes, we had grossly underestimated the cost of taking this to market.
Guy: And what did that initial amount of money, how far did they get you into actually conceding of what this product was going to be?
James: It got us to a prototype, write some rudimentary software, get some industrial design concepts done and some models.
Guy: What did the prototype look like? Did it look like a Fitbit?
James: It looked absolutely nothing like a Fitbit. There are two things, there was actual, somewhat working prototype and then there was an industrial design model.
Guy: Which was a piece of plastic.
James: Plastic, and metal that was supposed to look like the ultimate product. And so, that actually looked really, really nice.
Guy: But it didn't work?
James: Yeah. It was totally nonfunctional. And we'd always have to tell people before showing, "This doesn't work here." Because they get all excited looking at the model. "No, no, no. That doesn't work." The thing that actually worked looked like something that came out of a garage, literally.
Guy: What did it look like?
The prototype
James: It was rectangular circuit board, a little bit smaller than your. And it had a motion sensor, it had a radio, it had a microcontroller, which was the brains of the product. And it had a rudimentary case, which was a balsa with box.
Guy: Wow. So you would take to investors, a circuit board and a balsa wood box as your prototype?
James: Yeah. That was the prototype. And actually that was what we had demoed. When we first announced the company, that was the prototype that was actually being used at the announcement.
Guy: Wow. I mean, how did you even get it to that point? Because you guys are both software engineers, how did you develop a physical product that even such a crude prototype could track movement? Did you have other people help you do that?
James: That was our big task was to find the right people who could help us. I knew the founder of a really great industrial design firm in San Francisco called New Deal Design. His name is Gadi Amit. And then on the algorithm side, because it was going to take a lot of sophisticated algorithms to translate this motion data to actual data that users would be able to understand, I ended up asking my best friend from college, because he was in grad school at Harvard at the time. And he said, "Wait, I think I might know somebody." And it ended up being his teaching fellow, his name was Shelton. And we talked and I was like, "Wow, this guy is super smart. We need to get him working on the algorithms." So he ended up working on the side while doing his PHD, helping us out with a lot of the software.
Guy: I mean, you leave CNET in 2007, and you've got 400,000 to come up with a prototype that quickly run out of that. So it's 2008, and you're trying to raise money, how much did you raise?
Raising $2M (2008)
James: I think our first round was about $2 million.
Guy: Which was not going to take you that far if you wanted to develop a physical product that was super sophisticated, a piece of hardware.
James: We thought we could do it. We thought we knew a little bit more about the hardware business. We put together another business plan budget. It was actually a pretty challenging time to raise money as well because-
Guy: Oh, with the financial crisis. Yeah.
James: Exactly. It was the fall of 2008, when we were trying to raise money. One of the, I guess the good and bad things about VCs is, the good thing about VCs is they're incredibly healthy people. They're super fit. But it also made it difficult for a lot of them to understand the value of the product because what we were trying to do was, it wasn't a product meant for super athletic people, it was really meant to help normal people become more active, become healthier, et cetera. And it was hard for a lot of them to grasp why that was valuable. They'd ask, "Well, did it do X or did it do Y and did it do Z?" And we'd say, "No, it doesn't do any of that." And so it was very difficult for a lot of these super-fit VCs to understand the value of the product, even though a lot of them claim they don't try to put their own bias on these products. It's naturally human to do that.
Guy: And did you know right away that this was going to be... I mean, now Fitbit's are watches mainly. They're wrists, there on your wrist. But at that time, you were thinking that this was just going to be something you would clip to your clothing?
James: Yeah. Something to clip to your clothing for men. And then what we found out in talking to a lot of women was that they wanted to tuck it away somewhere hidden. They didn't want people to see it. And we said, "Okay, where would you want to put it?" And said, "Well, a lot of our pants don't have pockets, so it can't be in our pocket." And so the preferred place was actually on their bra. So a lot of the physical design that we had to think about in the early days was how to come up with a product that would be very slim, slender, and clipped people's bra.
Guy: And hidden.
James: And hidden and clipped the bras pretty easily.
Guy: And by the way, how did you come up with the name Fitbit?
Buying FitBit.com from a Russian for $2,000
James: It's never easy to name a company, and it's even more challenging just because of domain names. That's typically a lot of the limiting factor in naming a great company. And so, we would spend hours and hours and days just going through different permutations of names, and some awful ones as well. At some point we got onto a fruit theme. So we were thinking like Fitberry or Berryfit or Fitcado. Just some really awful names.
Guy: The Fitcado.
James: The Fitcado. Yes. History might've turned out a lot differently for sure. I was just taking a nap in my office one afternoon. I think I was actually napping on the rug because I was so tired. And I woke up and it just hit me, it was Fitbit. And the next challenge was actually the domain name. The domain name was not available. And it was owned by the guy in Russia. And I'm like, "Oh my god, how are we going to get this domain name? We'll just email the guy and see what happens." And he said, "Well, how much are you willing to offer?" And I said, "Oh god, I don't know. How about 1,000 bucks?" And he's like, "Oof, how about 10,000?" And I said, "Oh, I don't know. That sounds like a lot. How about 2,000?" And he's like, "Oh, okay. 2000, deal." I think it was literally two or three emails that we sent back and forth in this negotiation.
Guy: Probably the best $2,000 you ever spent in your life, except for the 300 you spent on the press release a couple years earlier.
James: Yeah, yeah. Definitely a good return.
Guy: You've probably spent many millions of dollars on other things in your life that were not as good of a deal as that $2,000.
James: Yeah. It's tens of thousands on naming consultants and focus groups and trademark searches and all of that. It's kind of funny.
Guy: Hey, as they say, small companies, small problems, big company, big problems.
James: Exactly.
Doing a consumer hardware startup before KickStarter
Guy: So where do you begin? I mean, you got to make it, you got to find a factory, you got to find designers. Where do you go?
James: Very good question. We obviously had zero connections. The challenge though, was not actually the connections to the manufacturers, but finding a manufacturer who we could actually convince to build this product because we didn't have a background in hardware. And so, would they actually want to work with us? That was the biggest concern at the time.
Guy: So how did you find them?
James: We went out to China. We went out to Singapore. And we were never going to be able to get the Foxconn's.
Guy: You had to go to a smaller place.
James: We had to go to a smaller place, who'd be more nimble, more flexible, who'd want to take a financial risk. And we finally found a great manufacturer based in Singapore called Racer Technologies. And the good thing is actually, it was the best of all worlds, the headquarters was in Singapore. Most of the management team and the engineering staff was in Singapore, but they had manufacturing facilities that were in Indonesia. The labor there was going to be lower cost than in Singapore.
Guy: All right. So 2008, you've got the name Fitbit, you go to TechCrunch50 to present, to unveil this product. And what was the product that you were offering? Well, you said, "All right, we've got to think of the Fitbit and it does this." What did you say it did at that point?
James: Our pitch to the crowd at TechCrunch, and ultimately to our consumer was that, it was a product that would track your steps, distance, calories, and how much you slept and would answer some basic questions about your health, "Was I active enough today? Did I get enough sleep? What do I need to do to lose weight," et cetera. And one of the more important aspects was this idea of a community as well. "Join other people who own Fitbits, your friends and family, and you could compete with each other." And it was all wireless. You didn't really have to do anything. All you'd have to do is wear this device, don't even think about it, and all this magic would happen. That was the promise of Fitbit at the time.
Guy: There was a lot of excitement there, but I'm wondering, were you nervous to do these presentations? Did you have to prepare like crazy, or did you just find your ability to be this person you had to be on stage when you got up there?
James: Yeah, I think there was no other choice. It was just something we had to do. And I think-
Guy: Are you better at it than Eric, or is Eric better at it than you?
James: I think we're both good in our different ways. It just fell upon me. I don't even know how we decide those things. But actually, what was running through our minds, was not what we were going to say and how we're going to say it, but whether the demo would actually work on stage, because again, it was a little sketchy. It was still very early. It was still in the wooden box.
Guy: In the balsa wood box.
James: Balsa wood box phase. So we were just worried that the demo would just fail or crash.
Guy: But it worked.
The TechCrunch pitch and 2,000 preorders
James: It worked, and actually it did crash in the middle of the presentation because the whole demo was about me walking on stage, the device would be collecting stats. And at one point I would turn to Eric and say, "Hey, Eric, why don't you refresh the page and show that all the stats have been uploaded." Magically, do this wireless connection. And so, the demo actually crashed while I was talking, and Eric was fiercely trying to reboot his computer during this period and I don't even know anything about it. But ultimately, the demo did work. And so, to many people, it seemed like magic. Literally, people started clapping. It was really amazing.
James: Originally, right before TechCrunch, Eric and I, we made just a verbal bet. "How many pre-orders are we going to get after this conference when we announce and make the company public?" And I think Eric said, "I think we'll get like five pre-orders." So it's like, "The device isn't even available. People are going to have to give us their credit card information." And I said, "Nah, you know what? I'm not as pessimistic. I think there's going to be like 10, 15, 20." And so we got off stage, and by the end of the day, we had about 2000 pre-orders.
Guy: Wow. When we come back in just a moment, James and Eric have a prototype in the balsa wood box and they don't exactly know how they are going to get from there to filling thousands of pre-orders. But a lot of people are expecting them in time for Christmas. Stay with us, I'm Guy Raz, and you're listening to How I Built This from NPR.
Guy: This message comes from NPR sponsor, Sell on Amazon. When you sell on Amazon there's room to grow, ways to move and countless reasons to believe that your brand can do more. Amazon can help you set up your products and tell your brand's story. Give you access to insightful analytics and even help with shipping, customer service and returns through Fulfillment by Amazon. Sign up at sell.amazon.com/npr and get ready to grow, ship, sell, and thrive. Start selling on Amazon today. This message comes from NPR sponsor, ClickUp. You don't need to exist on four hours of sleep to be productive. Enter ClickUp a completely customizable work platform with all the features you've ever needed to build your business. All in one place. Join 100,000 teams across companies, like Airbnb, Google, and Uber who are already using ClickUp to level up their productivity and save one day a week guaranteed. ClickUp is free forever. So get started at clickup.com/npr today.
Guy: Hey, welcome back to How I Built This from NPR, I'm guy Raz. So it's 2008, and James and his co-founder Eric Friedman show off their Fitbit prototype at TechCrunch, and it makes a huge splash. The problem is, they have no finished product. They haven't even figured out how they're going to make it and pre-orders are pouring in.
Being Open and Transparent
James: And they just kept coming in. It was crazy. We were like, "Oh my god, it's not just dozens of these units we have to build, it's now thousands, and more and more every day." And so we were still thinking Christmas of that year that we were going to start shipping out units, and it rapidly became clear to us that we weren't going to make Christmas. And so, we're thinking, "Okay, how do we keep all these people happy while we pull this off?" So this was before Kickstarter and Indiegogo and all that. We had to improvise. We were like, "Okay, why don't we just blog about the whole process and just be very open and transparent about it." So we started a blog, and I wrote maybe weekly updates on how things were going, challenges and delays that we were facing.
James: And I was really surprised, actually, it worked. It made people understand what we were going through. They're literally seeing the thing being made, the sausage being made behind the scenes. And I think that kept people really engaged throughout the process.
Guy: So you have basically a bunch of contractors and freelancers and you guys are going back and forth to Asia. You got people working on the software to transmit the data to the web. You've got some people working on the hardware, presumably, in Singapore trying shrink down the motherboard to something that is two inches by one half inch. And were you just constantly running into failures? You would think that, "Oh, here it is." And then somebody would hit the go button and then it would just fizzle out, it wouldn't work?
James: Yeah. I can't even enumerate the number of challenges with the product that we had.
Guy: Please start.
Manufacturing in Asia
James: In some ways a lot of people, I think when you think about hardware, it's like, "Oh, I'll find a manufacturer in China. I'll throw over a design."
Guy: Yeah, right. No problem.
James: "They'll just run with it."
Guy: And then, "Just send me the bill," and then it's done.
James: And they'll just crank out thousands, tens of thousands of this. But that's never-
Guy: And that works if it's a suitcase, we've done a way. It works if it's that thing.
James: If it's that thing or something that's very similar to something that they've built before.
Guy: Right.
James: Well, that's a different story than this thing that this manufacturer never had built before.
Guy: So they would send you things and say, "Yep, we got it." And then you would get it and it sucked. It just didn't work.
James: Yeah. We wouldn't wait for them to send it. I mean, either myself or Eric would be in Indonesia or Singapore at any given time. We'd trade off different weeks. And we were out there on the production lines pretty much inspecting every part of the process.
Guy: But were you convinced this thing was going to work or did you have doubt?
James: I was absolutely convinced that it was going to happen.
Guy: You had no doubts that this-
James: I had no doubts because we were getting proof every day that this was something that was going to be big. And I think the first evidence of that was at TechCrunch where we had 2,000 pre-orders and we were getting pre-orders every day. I think by the summer time, we had about 25,000 pre-orders at $100 per unit. That's a fair amount of revenue if we could ship these units.
Guy: And how much was it going to cost you to make each unit?
James: That was a very good question. We didn't know that. Hopefully, under $100.
Guy: You didn't know? You were selling them for $100, but you didn't know how much it was going to cost you.
James: We had a sense of the bill of materials. I think we were trying to shoot for a gross margin of about 50%. So we're targeting the full cost of the product, including shipping, et cetera, being no more than $50. That's what we were targeting.
Guy: Which is a lot. That's high. It's a high cost.
James: It's a high cost, but that was a cost at which we felt we could sustain ourselves as a business.
Guy: How did you and Eric manage your relationship and friendship? I mean, with the stress of this delay and inability to meet demand and all these, was there tension at all between the two of you, or you guys totally are on the same page?
Importance of cofounders
James: I don't think there was that much tension. I mean, a lot of stress, but not tension. I think we trust in our ability to help each other out. And there are periods when either of us would be pretty down on the company and the product. And luckily, we weren't down both at the same time. And that's why it helps, I think, to have a co-founder.
Guy: So there were times where you were really down and he could give you a pep talk and.
James: Exactly. And then I'd wonder why he wasn't down. And there're some pretty dark times right before we shipped. I remember we were months before we thought we could finally get the first unit off the production line. And I was sitting in my hotel room in Singapore, and I was testing out one of the prototype builds that that Racer had produced and the radio range was not good at all. It was supposed to have a range-
Hardware is Hard
Guy: 10 feet or 15 feet?
James: That was the hope that it would have 15 to 20 feet range, but the range was actually two inches.
Guy: Oh god. Wait, so the antenna in the device had a two inch range.
James: Yeah. It would only work at two inches. And I'm thinking, we've got to ship this holiday season. I've got tens of thousands of these people waiting.
Guy: Oh god.
James: And so, I'm just freaking out in hotel room.
Guy: You might as well have a cord and just plug it in.
James: Exactly, exactly. I couldn't sleep that night obviously. And I took the unit apart. I had a multimeter and I was measuring different voltages and currents. And what I realized was, huh, the cable for the display was flexible and long enough that maybe it was actually trooping down and touching the antenna and that was causing-
Guy: That was creating interference.
James: Creating interference. And I could see that when you put the whole thing together, that it might troop down. And I thought, "Okay, how do I create a shim that would prop the antenna?" So I went to the bathroom, grabbed some toilet paper, rolled a little bit of it in a ball and stuffed it between the antenna and the display cable, put the device back together. And it started working. The range was great.
Guy: Wow. So you had to separate one wire from the antenna and that was it, with toilet paper?
James: With toilet paper. Yeah, that was it.
Guy: Wow.
James: And I still couldn't sleep. So as early as possible, the following morning I raced into our manufacturing and said, "Okay, I think I found the problem," but obviously a toilet paper is not a scalable high volume situation. So they went back and figured out how they could make this manufacturable. So they ended up creating these little tiny tie cut pieces of rubber that they would glue onto the circuit board to keep the antenna away from the display cable.
Guy: Wow. Wow. So that was, basically, was just, inserting something in there and then it worked?
James: Yeah, it wasn't exactly duct tape, but that was the equivalent of duct tape
Guy: It was pretty close.
James: It was pretty close. Yeah.
Guy: So you guys launched this product in Christmas of 2009, and it was a pretty successful product launch. You had 25,000 orders and sounds like you're off to the races, but I guess even with this success, when you went out to raise money, this is 2010, were investors more excited or was it still a challenge to get more investors in?
James: It was still a challenge. And at the time, it wasn't "Okay, I guess you guys are having some success, consumers are buyin the product, et cetera." And they congratulated us on that. But the were very scared of hardware businesses. I think there had been a lo of really high profile failures in the consumer electronics industry And so, it was very difficult for us to raise money. I remember, w had a spreadsheet of target VCs. I think there are 40 names that w put on that list. And literally, we went to number 40 before we wer able to raise money.
Raising money from VCs: 40 nos.
Guy: And just giving the same pitch, again, again, answering the same questions?
James: Same pitch. We're in San Francisco driving down 101 to Sand Hill Road, constantly giving the same pitch to 40 VCs. That's probably the one thing I didn't like about that whole time period was, I hate giving the same pitch over and over and hearing the same questions and same objections, et cetera. That was not a fun or stimulating time for me.
Raising $8M (2010)
Guy: All right. Eventually, the 40th investor does decide to give you some money. I think you raised about $8 million. And at this point, were you able to then have a proper office and a staff. Were you able to begin to recruit real full-time engineers and developers and people like that?
James: We were. We did that with the round that was right after our first $2 million institutional round. We hired a bunch of customer support personnel. I interviewed and hired our first head of sales. I interviewed and hired someone to finally run all of our manufacturing and operations, which was still a job that I was doing. I was still issuing all the [POS] and managing the inventory. And I think we were really fortunate because the early management team that we hired in those days pretty much made it up to and passed our IPO, which I think rarely happens.
Building a community
Guy: It's so crazy to think about it now. But I think early on, with the Fitbit, the idea was to be part of a bigger community. Like the data from your activity would be available. You would just go to a site and you could see it and you could see everybody else's because the idea was, "We're all part of this together." But I think early on, some users were tracking sex. And when you started to hear about these things was your reaction like, "Oh my god, I never even thought about this being a privacy thing. I always thought that people would just want to share stuff."
James: Yeah. This was still the early days of sharing things like that. And I found out about it because I saw this tweet about someone going, "Hey, if you do this Google search, you'll see," because Google was indexing all our public pages where people are logging things that people had made public. "You could find out all the sexual activities that people are logging on Fitbit." And I saw that, I'm like, "Oh my god, this is not good." That ended up being the first real PR crisis for the company. And it was happening over the 4th of July weekend. So I had to call an emergency board meeting. We had to scramble to delete all that stuff, turn everything private.
Guy: Because the default setting, initially, when you got to Fitbit was, it's not private, it's open. Because the idea was, it was going to be a big community of people trying to get fit.
James: Yeah. I mean, we made a lot of things private by default. We made sure that people's weight was private because we thought that would be sensitive, but we didn't think that people's activities, there wasn't any harm in doing that and we just didn't realize that people would start logging that.
Guy: And just to be clear, people who logged sexual activity, this was not a category that you offered up, it was just people were voluntarily deciding to just log that as one of their activities.
James: Well, it was a category, but it wasn't something that we had realized. We use this database from the government that was thousands of different activities that people would do.
Guy: Oh, I see.
James: And so, it was an option. We just didn't think people would with log that.
Guy: You were just naive about that.
James: We were naive. We were like, "Okay, this is a government database of activities. It must be fine." That was quite a shock and a wake up call for us.
$76M in revenue (2012)
Guy: Fitbit for the first couple of years was, a, still a clip. Mainly a clip. And then, I think really 2011, you released the first product, Christmas of 2009, you've got 2010. By 2011, just business exploded, 5X growth from 2011, 2012. You went from $15 million in revenue to $76 million in revenue. What was going on? Was it just this self-generating phenomenon? Were you surprised by it? Were you've investing in marketing? Was it just unearned media, just people reporting on it? What was going on?
James: I think, the primary reason is, because we had baked in this social element, this community element into it from the very beginning, it ended up being a very viral product. So one family member would get it, and to really realize the potential, the community aspect and the competitive aspect, you had to have someone else as well. So they'd either buy it for their spouse or their parents and they would start competing and then they'd buy it for their friends and they'd try to get their friends to buy the product.
Guy: So they could each see how many steps you were... Because I remember this, I remember this in NPR. People were wearing Fitbits and they were talking and there was, I think there was even, people were encouraged to get Fitbits.
James: Exactly. It was very driven by word of mouth. And this viral spread was a huge driver of our growth in those days.
Worrying about Competition (2013)
Guy: I think by 2013, you had some competitors coming in. Nike was making one and Jawbone was making one. I mean, I remember going to the TED Conference in 2013 and getting a Jawbone in my gift bag. Were you worried about the competition at that point, or not really?
James: Yeah. At that time I think people were looking at the success and there was even a name, coined for the whole category, which is quantified self. "How do I use sensors, et cetera, to measure everything that I'm doing in my entire life?" And so that attracted a lot of competition that you said. And I'd have to say the competitive aspect was definitely worrying at the time, especially with Nike and Jawbone.
Guy: Because they're so huge.
James: There are huge. I mean, Nike, obviously, it's a multi-billion dollar, multi-national company with a lot of media dollars. I remember when they announced the FuelBand, they had all these celebrity athletes at the announcement and we're like, "Oh god, that's insane."
Guy: And yet, by 2014 you had 67% of the activity tracking marketplace. I mean, Fitbit was just totally dominating the marketplace. I mean, were you and Eric doing victory laps and high-fiving each other and thinking back to all those doubters? I mean, what was going on?
James: I think we were still pretty, I don't know if scared is the right word. I think, it's still very, very cautious. Nothing was guaranteed. There was a lot of competition that was emerging. We still had a lot of internal challenges in the business, scaling production, scaling the company, et cetera. Again, a lot of fires for us to be solving on a day-to-day basis. And I remember occasionally we'd always check in and say, "Hey, when do you think we'll know we're going to make it?" And we'd say, "I think we'll know in six months." And we kept saying that every six months. It was pretty much an ongoing thing, pretty much up to the IPO.
The IPO (2015)
Guy: 2015 was a huge turning point for you in many ways. You go public, I think your market cap, I read a certain point, reached $10 billion. That year, 2015, the Apple Watch is released and they stopped selling Fitbit in their stores. At the time you were quoted saying, I'm not really worried about this because it's a huge market. It's a $200 billion market. The Apple Watch is just crammed with a bunch of stuff, or smartwatches are crowned with a bunch of stuff. And what we're doing as something simpler." Was that, what you were saying publicly, because I don't know, you be felt like you should be saying that or did you really think that was true that the Apple Watch wouldn't actually have much of an impact?
The Apple Watch (2015)
James: We were definitely concerned with Apple. I mean, this was the preeminent technology, and especially a hardware company at the time with an amazing brand. We had faced off Philips and Nike and Jawbone, which were in their rights, very big competitors, especially Nike. We did feel very strongly that our product had very clear advantages. It was a simpler product. If you looked at the Apple Watch, that was announced at that time, I think everyone will admit maybe even Apple, that it was a product that didn't quite know what it was supposed to be used for. With the launch of the first Apple Watch, I don't really think that that had an actual impact on the trajectory of the business. It wasn't the product that it would later become. And the industry wasn't where it would eventually evolve either.
Guy: I mean, but eventually, the industry did change. I mean, Apple Watch got really popular. I think, by 2016, Fitbit's stock had dropped by 75% over the course of a year. I mean, you and Eric were running a publicly traded company and the stock was just tumbling. What did you think? I mean, I can't imagine that was pleasant for you.
Running a Public Company
James: No, it was definitely a stressful period. And you could argue, well, maybe we shouldn't even have been valued at 10 billion in the first place. And I think in a lot of times it's a question of perception. If we had never hit that 10 billion and we had steadily grown into the 2 billion, I think people's perceptions and just psychology about the whole situation would have been different than going to 10 and falling to two. And it was a very challenging period because as a private company, despite challenges, your valuation doesn't change very often. It only changes when you raise money, which could happen once a year, once every two years. So if you hit a bump in the road, your employees don't really feel it.
James: We had a product recall where, if we had been a public company, our valuation would have plummeted immediately, but at the time we were private. So we just told the employees, "Hey, look, this is the challenge. It's pretty serious, but here are the steps that we're going to take to get through it." And everyone rallied together. But when you're being measured every day in real-time-
Guy: By the stock price.
James: ... By the stock price, you're not really given a lot of breathing room to try to fix things.
On Critical Feedback
Guy: Even though you were introducing new products, revenue was declining every year from the time you went public. And I read an article about something that you did in 2017. And I'm really just curious to get your take on it, because I actually think it's really courageous, but also probably super stressful and difficult, which is, you asked your employees to submit an evaluation of the company and of you. And then you sat in front of them to hear the results of this evaluation and it wasn't good. You even had some employees who wrote letters to the board asking that you be removed as CEO. I can't imagine that was easy for you to hear.
James: I don't know if I've heard that particular feedback directly, but clearly the survey results were not great. I have jokingly think, probably used to hearing very critical feedback because of my parents. I don't think there was a moment where they're truly happy with anything that I did. I remember even when I took the SATs and I got my score back, it was a pretty good score, but my dad just honed in on clearly the areas that I had not done well. I don't think I have a huge ego. I mean, I do have an ego, I think it's human to have one, but my primary focus was, "How do I get things back on track?"
Guy: You had, there was a quote from somebody in an article. I was an anonymous quote. It said, "At a certain point, we're focused o the right things. We had the ability, and have the ability to know lot about our users, which you do, but our users don't want to be tol what they did." In other words, they don't want to be told, "Hey, yo exercise, you did 10 steps today." They want to be told what to do Like how to get better. And the quote was, "This was the greates missed opportunity." And I know you've made a pivot since then, bu was that a fair assessment at the time in 2017, that you were to focused on telling people what they've accomplished rather tha telling them what they need to do?
James: Yeah. I think there are ultimately two big things that were driving the headwinds in the business. First of all, I think we were really behind in launching a competitive smartwatch at the time. People were-
Guy: Competitive to...
James: Competitive to Apple. It was clear that the industry, consumers were moving to that category and we were seeing that in our sales. So in a very short period of time, our tracker business fell by $800 million in revenue. And at the time, at our peak, we were doing about 2.1 billion in revenue.
Guy: Wow.
James: So we had $800 million hole, and we finally launched our smartwatch, but it was only sufficient to fill that hole very barely. We hadn't transformed the software into giving people guidance and advice. And it also ties to our failure at the time to quickly diversify our revenue stream beyond just hardware to a services business that-
Guy: Like a subscription.
The Subscription Service
James: Exactly. We were so focused on growing our hardware business because that was what was bringing in the money, that was what the retailers wanted, et cetera. And one of the mistakes I made was not setting up enough time, enough focus to building the subscription part of the business that actually answered those pivotal questions for our users.
Guy: As many, many companies find themselves in a successful companies that have a successful legacy product, this is crazy talking, but a legacy product for your company, which is only 10 years old or 12 years old. You could argue that the Fitbit product is your legacy product, right? And that, as any company with a legacy product realizes, they've got to make a pivot. Like for American Express, it was traveller's checks for 100 years. That's how they made their money. And they had to pivot into other things, there is travel services and credit cards and so on. It sounds like in 2019, you really made a pivot into thinking about Fitbit, not as a hardware company that makes a tracker, watch, or device, like smartwatch, but a company that really is about healthcare and is designed to pivot more into healthcare data and analysis. Is that fair? Is that right?
James: Yeah. I think that's fair. I think we stopped thinking of ourselves as a device company and more of as a behavior change company because that's effectively what people were buying our products and services to do, was to change their behavior in a really positive way. And not only individual people, but companies as well. Companies who in the US, especially bear the direct costs of the care of their employees. We started thinking about ourselves as a behavior change company and figuring out what are the products and services that really deliver that both to people and to businesses.
The Google Acquisition (2019)
Guy: So we get to the end of last year where Google announces that they were going to buy Fitbit, $2.1 billion. We should mention that, at the time of this recording, it hasn't closed yet. To me, it makes perfect sense. If I'm you or Eric, I would have done it. I would've said, "$2.1 billion, that's great. That's a great outcome because now with Google, we've got access to their dollars and their research labs and all the people who work there and the analytics and our ability to really go to the next level." Why did it make sense from your perspective to sell to Google?
James: Yeah, that's a very complicated and emotionally fraught question, but last year our board met and it was pretty clear to everybody that we had a lot of challenges in the business. We weren't profitable. There was a lot of competition out there from the likes of Apple, from Samsung, some emerging Chinese competitors, but there was a lot of just great things going on in the company. I was so excited about our product roadmap, about things that were in our pipeline, all the advanced research that we were doing around health and sensors. I would look at our product roadmap every day and just come away super excited about that. And then also be confronted with a lot of the business challenges as well.
James: And for me, most importantly it was about a legacy and I wanted the Fitbit brand and what we did to continue onwards for a very, very long time. And we just had to figure out the best way to do it, whether it was as an independent company or within a larger company. That was really what was most important.
Guy: I imagine that there are some details you can't talk about for obvious reasons, but as of this recording, we're talking in mid-April, there is a hold on the Google acquisition. The department of justice is doing an investigation because there's some interest groups who have said, "Hey, we don't think that Google should have access to all of this data. That Fitbit has 28 million users. This is incredible trove of health data." Is that causing you stress right now that there is this justice department holdup on the acquisition?
James: No. And it's because sometimes the press does like to sensationalize things, but the process that we're undergoing right now with the department of justice and also with the EU and some other countries around the world is pretty normal for acquisitions of the size. In fact, it's required. Really, the whole reviews about the anti-competitive element, and especially around the wearable market share. That's just something that we have to convince regulators that, "This doesn't reduce competition in the marketplace."
Guy: As far as you know, the situation now with the lockdowns and the pandemic does not have any impact on Google's interest or commitment to making this happen.
James: No, I think everyone's thinking towards the long-term, fingers crossed is that we do find ourselves through this COVID-19 situation and that there is life beyond that. Maybe it comes back slowly, but I think everyone is thinking, "What does this whole category look like in time span of years? How?" And I think what, one of the things that COVID-19 has shown is that, especially if you look at healthcare, this idea of remote health care, remote monitoring, people healthy outside of a hospital setting is actually really important.
Guy: Super. It's going to totally change... I've had a video call with my doctor just for a quick question. It's actually super convenient.
The Future of Medicine
James: Exactly. And if during these telemedicine visits, if they have a snapshot in summary of what you've been up to and what your health has been outside of that visit, and almost be predictive in that way, I mean, I think that can be really groundbreaking in the way medicine gets practiced. And this whole time period is merely accelerating that transition.
Guy: When you think about all of the things that you have done professionally and your successes, you made a lot of money. I mean, you're extremely wealthy and wealthier than your parents could have ever imagined you would be, or they would be. They took a huge risk to come to the US and had all these little mom-and-pop stores. How much of that do you think is because of your intelligence and skill and how much do you attribute to luck?
Closing thoughts
James: Yeah, that's always a tricky question to answer. I think, very fortunate to have grown up with my parents. Just having seen them persevere through life, you get the realization that nothing really comes easy. That it does take a lot of just grinding away at things that at the time seem unpleasant. I think those are good traits and very fortunate to have parents like that who sacrificed a lot to put me in great schools over time, even though they started from some humble beginnings. But also, have learned a lot of ways, gotten some lucky breaks where things could have gone the wrong way very, very quickly. Ultimately, I attribute it to a little bit of all of that. I think it's not fair to say that everything is luck because then I think you start to discount the actual things, actions that you can take on your own to affect the future. And that's really important.
Guy: That's James Park, co-founder of Fitbit. And here's a number for you, 34,642,772, that is how many steps James has tracked since he first put on that balsa wood Fitbit prototype. At least as of this recording. It's about 15,430 miles or 24,832 kilometers. And thanks so much for listening to the show this week, you can subscribe wherever you get your podcasts. You can also write to us at hibt@npr.org">hibt@npr.org. And if you want to send a tweet, it's @HowIBuiltThis or @guyraz. This episode was produced by James Delahoussaye, with music composed by Ramtin Arablouei. Thanks also to Sarah Saracen, Candice Lim, Julia Carney, Neva Grant, Casey Herman, and Jeff Rogers. I'm Guy Raz, and you've been listening to How I Built This. This is NPR.
February 28, 2021 — I read an interesting Twitter thread on focus strategy. That led me to the 3-minute YouTube video Insist on Focus by Keith Rabois. I created the transcript below.
One of the fundamental lessons I learned from Peter Thiel at PayPal was the value of focus. Peter had this somewhat absurd, but classically Peter way of insisting on focus, which is that he would only allow every employee to work on one thing and every executive to speak about one thing at a time, and he distributed this focus throughout the entire organization. So everybody was assigned exactly one thing, and that was the only thing you were allowed to work on, the only thing you were allowed to report back to him about.
Examples
My top initiatives shifted around over the years, but I'll give you a few. One was initially Visa, MasterCard really hated us. We were operating at the edge of their rules at the time. My number one problem was to stop MasterCard particularly, but Visa a bit from killing us. So until I had that risk taken off the table, Peter didn't want to hear about any of my other ideas.
Once we put Visa, MasterCard into a pretty stable place than eBay also wanted to kill us. Wasn't very happy with us processing 70% of the payments on their platform, so that was my next problem.
Then 9/11 happened and the US Treasury Department promulgated regulations, which would require us among other things to collect Social Security numbers from all of our buyers, which would have suppressed our payment volumes substantially. So then my number one initiative became convincing the treasury department to not propagate these regulations, right post 9/11.
At some point, we also needed to diversify our revenue off of eBay. So that became another initiative for me. That one I did not solve that well, which in some way led to us eventually agreeing to be acquired.
I had another number one problem, which was this publication called the Red Herring, had published this set of unflattering articles about us and how to fix that and rebuild the communications team.
Peter would constantly just assign me new things. He didn't like the terms of our financial services relationship with the vendors that we were using, so I took on that team and fixed the economics of those relationships, et cetera, et cetera, but they were not done in parallel. They're basically sequential.
Why This Works
The reason why this was such a successful strategy is that most people, perhaps all people tend to substitute from A-plus problems that are very difficult to solve, to be a plus problems, which you know a solution to, or you understand the path to solve.
You have a checklist every morning. Imagine waking up, and a lot of people write checklists and things to accomplish. Most people have an A-plus problem, but they don't know the solution so they procrastinate on that solution? And then they go down the checklist to the second or third initiative where they know the answer and they'll go solve those problems and cross them off. The problem is if your entire organization is always solving the second, third or fourth most important thing, you never solve the first.
So Peter's technique of forcing people to only work on one thing meant everybody had to work on the A-plus problems. And if every part of the organization once in a while can solve a problem that the rest of the world thinks is impossible, you wind up with an iconic company that the world's never seen before.
I absolutely love the math behind this strategy. There are a few other terms to get right, but there's a fantastic idea here.
February 28, 2021 — I thought it unlikely that I'd actually cofound another startup, but here we are. Sometimes you gotta do what you gotta do.
We are starting the Public Domain Publishing Company. The name should be largely self-explanatory.
If I had to bet, I'd say I'll probably be actively working on this for a while. But there's a chance I go on sabbatical quick.
The team is coming together. Check out the homepage for a list of open positions.
February 22, 2021 — Today I'm launching the beta of something new called Scroll.
I've been reading the newspaper everyday since I was a kid.
I remember I'd have my feet on the ground, my body tilted at an angle and my body weight pressed into the pages on the counter.
I remember staring intently at the pages spread out before me.
World news, local news, sports, business, comics.
I remember the smell of the print.
The feel of the pages.
The ink that would be smeared on my forearms when I finished reading and stood back up straight.
Scroll has none of that.
But it does at least have the same big single page layout.
Scroll brings back some of the magic of newspapers.
In addition to the layout, Scroll has two important differences from existing static publishing software.
First, Scroll is built for public domain sites and only public domain sites. Builders of Scroll will spend 100% of the time building for the amazing creators who understand and value the public domain.
Second, Scroll is built on Particles. Unlike Markdown, Scroll is easily extensible. We can create and combine thousands of new parsers to help people be more creative and communicate more effectively.
I've had fun building Scroll so far and am excited to start working on it with others.
Sleepy Time Conference
The conference that comes together while you sleep.
The Problem
February 11, 2021 — Working from home is now a solved problem.
Working from the other side of the world is not. Twelve hour time zones differences suck! Attend a conference at 3am? No thanks!
The Solution
Sleepy Time Conference is open source video conference software with a twist: you can go to sleep while a conference is going on without missing a thing.
How it works
A 1 hour conference takes place over 24 hours. But instead of using live syncronous software like Zoom, conference speakers and questioners record their segments asyncronously, in order of their time slot.
So when the conference starts the conference page looks like this:

As the world turns, speakers click the record button for their slot and add their respective segments.
12 hours later the conference page looks like this:

After 24 hours:

That conference is a wrap!
A full 1 hour video of the conference is now available for watching.
Originally posted here https://github.com/breck7/sleepytimeconference
Possibly Relevant Video Editing Interfaces
Open Source
Closed Source
Project Status
You're looking at it
Important
There is a domain the public domain the only domain there should be. Where ideas can mingle improve and change So that the people can be free.
December 9, 2020 — Note: I wrote this early draft in February 2020, but COVID-19 happened and somehow 11 months went by before I found this draft again. I am publishing it now as it was then, without adding the visuals I had planned but never got to, or making any major edits. This way it will be very easy to have next year's report be the best one yet, which will also include exciting developments in things like non-linear parsing and "forests".
In 2017 I wrote a post about a half-baked idea I named Tree Notation.
Since then, thanks to the help of a lot of people who have provided feedback, criticism and guidance, a lot of progress has been made flushing out the idea. I thought it might be helpful to provide an annual report on the status of the research until, as I stated in my earlier post, I "have data definitively showing that Tree Notation is useful, or alternatively, to explain why it is sub-optimal and why we need more complex syntax."
My template for this (and maybe future) reports will be as follows:
- 1. High level status
- 2. Restate the problem
- 3. 2019 Pros
- 4. 2019 Cons
- 5. Next Steps
- 6. Status of Predictions
- 7. Organization Status
High Level Status
I've followed the "Strong Opinions, Weakly Held" philosophy with this idea. I came out with a very strong claim: there is some natural and universal syntax that we could use for all of our symbolic languages that would be very useful—it would let us remove a lot of unnecessary complexity, allow us to focus more on semantics alone, and reap a lot of benefits by exploiting isomorphisms and network effects across domains. I've then spent a lot of time trying to destroy that claim.
After publishing my work I was expecting one of two outcomes. Most likely was that someone far smarter than I would put the nail in Tree Notation's coffin with a compelling case for why a such a universal notation is impossible or disadvantageous. My more optimistic—but less probable—outcome was that I would accumulate enough evidence through research and building to make a convincing case that a simplest universal notation is possible and highly advantageous (and it would be cool if Tree Notation evolves into that notation, but I'd be happy for any notation that solves the problem).
Unfortunately neither of those has happened yet. No one has convinced me that this is a dead-end idea and I haven't seen enough evidence that this is a good idea[1]. At times it has seemed like a killer application of the notation was just around the corner that would demonstrate the advantages of this pattern, but while the technology has improved a lot, I can't say anything has turned out to be so compelling that I am certain of the idea.
So the high level status remains: strong opinion, weakly held. I am sticking to my big claim and still awaiting/working on proof or refutation.
Restating the Problem
What is the idea?
In these reports I'll try and restate the idea in a fresh way, but you can also find the idea explained in different places via visuals, an FAQ, a spec, demos, etc.
My hypothesis is that there exists a Simplest Universal Notation for Symbolic Abstraction (SUNSA). I propose Tree Notation as a potential candidate for that notation. It is hard to assign probabilities to events that haven't happened before, but I would say I am between 1% and 10% confident that a SUNSA exists and that Tree Notation is somewhat close to it[2]. If Tree Notation is not the SUNSA, it at least gives me an angle of attack on the general problem.
Let's define a notation as a set of physical rules that can be used to represent abstractions. By simplest universal notation I mean the notation that can represent any and every abstraction representable by other notations that also has the smallest set of rules.
You could say there exists many "UNSAs", or Universal Notations for Symbolic Abstractions. For example, thousands of domain specific languages are built on the XML and JSON notations, but my hypothesis is that there is a single SUNSA. XML is not the SUNSA, because an XML document like <a>b</a> can be equivalently represented as a b using a notation with a smaller set of rules.
Where would a SUNSA fit?
Inventions aren't always built in a linear fashion. For example, when you add 2+3 on your computer, your machine will break down that statement into a binary form and compute something like 0010 + 0011. The higher level base 10 are converted into the lower level base 2 binary numbers. So, before your computer solves 2+3, it must do the equivalent of import binary. But we had Hindu-Arabic numerals centuries before we had boolean numerals. Dependencies can be built out of order.
Similarly, I think there is another missing dependency that fits somewhere between binary the idea and binary the symbolic word.
Consider Euclid's Elements, maybe the most famous math book of all time written around 2,500 years ago. The book begins with the title "Στοιχεῖα"[3]. Already there is a problem: where is import the letter Σ?. Euclid has imported undefined abstractions: letters and a word. Now, if we were to digitally encode the Elements today from scratch, we would first include the binary dependency and then a character encoding dependency like UTF-8. We abstract first from binary to symbols. Then maybe once we have things in a text stream, we might abstract again to encode the Elements book into something like XML and markdown. I think there is a missing notation in both of these abstractions: the abstraction leap from binary to characters, and abstraction leap from characters to words and beyond.
I think to represent the jumps from binary to symbols to systems, there is a best natural notation. A SUNSA that fits in between languages that let's us build mountains of abstraction without introducing extra syntax.
To get a little more concrete, let me show a rough approximation of how using Tree Notation you could imagine a document that starts with just the concept of a bit (here denoted on line 2 as ".") and work your way up to defining digits and characters and words and entities. There is a lot of hand-waving going on here, which is why Tree Notation is still, at best, a half-baked idea.
.
...
0
1 .
...
Σ 10100011
...
Στοιχεῖα
...
book
title Elements
...
Why would a SUNSA be advantageous?
Given that I still consider this idea half-baked at best; given that I don't have compelling evidence that this notation is worthwhile; given that no one else has built a killer app using the idea (even though I've collaborated publicly and privately with many dozens of people on project ideas at this point); why does this idea still excite me so much?
The reason is because I think IF we had a SUNSA, there would be tremendous benefits and applications. I'll throw out three potential application domains that I personally find very interesting.
Idea #1: Mapping the Frontiers of Symbolic Science
A SUNSA would greatly reduce the cost of a common knowledge base of science. While it may be possible to do it today without a SUNSA, having one would be at least a one order of magnitude cost reduction. Additionally, if there is not a SUNSA, than it may take just as long to come to agreement on what UNSA to use for a common knowledge base of science as it would to actual build the base!
By encoding all of science into a universal syntax, in addition to tremendous pedagogical benefits, we could take analogies like this:
And make them actual concrete visualizations.
Idea #2: Law (and Taxes)
This one always gets me excited. I believe there is a deep connection between simplicity, justice, and fairness. I believe legal systems with unnecessary complexity are unfair, prima facie. While legal systems will always be human-made, rich in depth, nuanced, and evolving, we could shed the noise. I dream of a world where paychecks, receipts, and taxes are all written in the same language; where medical records can be cut and pasted; and where when I want to start a business I don't have to fill out forms in Delaware (the codesmell in that last one is so obvious!).
I believe a SUNSA would give us a way to measure complexity as neatly as we measure distance, and allow us to simplify laws to their signal, so that they serve all people, and we don't suffer from all that noise and inefficiency.
Idea #3: Showcasing the Common Patterns in Computing From Low Level to High Level
I love projects like godbolt.org, that let you jump up and down all the levels of abstraction in computing. I think there's an opportunity to do some incredible things if there is a SUNSA and the patterns in languages at different layers of computing all looked roughly the same (since they are roughly the same!).
What would the properties of a SUNSA be?
Tree Notation might not be the SUNSA, but it has a few properties that I think a SUNSA would have.
- 2 or more physical dimensions: Every symbolic abstraction would have to be contained in the SUNSA, so to include an abstraction like the letter "a" would require a medium have at least more than one physical dimension.
- Directional: A SUNSA would not just define how symbols are laid out, but it would also contain concepts of directionality.
- Scopes: Essential for growth and collaboration.
- Brevity: I think a SUNSA will have fewer components, not more. I often see new replacements for S-Expressions or JSON come out with more concepts, not less. I don't think this is the way to go—I think a SUNSA will be like a NAND gate and not a suite of gates, although the latter are handy and pragmatic.
I also will list one thing I don't think a SUNSA will have:
- A single entry point. Currently most documents and programs are parsed start to finish in a linear order. With Tree Notation you can parse things in any order you want—start from anywhere, move in any direction, or even start in multiple places at the same time. I think this will be a property of a SUNSA. Maybe SUNSA programs will look more like this than that.
So those are a few things that I think we'll find in a SUNSA. Will we ever find a SUNSA?
Why might there not be a SUNSA?
I think a really good piece of evidence that we don't need a SUNSA is that we've seen STUPENDOUS SUCCESS WITH THOUSANDS OF SYNTAXES. The pace of progress in computing in the 1900's and 2000's has been tremendous, perhaps because of the Smörgåsbord of notations.
Who's to say that a SUNSA is needed? I guess my retort to that, is that although we do indeed have thousands of digital notations and languages, all of them, without exception, compile down to binary, so clearly having some low level universal notation has proved incredibly advantageous so far.
2019 Pros
So that concludes my restatement of the Tree Notation idea in terms of a more generic SUNSA concept. Now let me continue on and mention briefly some developments in 2019.
Here I'll just write some bullet points of work done this past ~ year advancing the idea.
- Types and Cells
- Tree Notation as a Subset of Grid Notation
- New homepage
- TreeBase
- CopyPaster
- Dozens of new Tree Languages
- More feedback than ever. Tens of thousands of visitors. Hundreds of conversations.
2019 Cons
Here I just list some marks against this idea.
- It still sucks.
- No killer app yet.
- No good General Purpose Tree Language.
- No good Assembly Tree Language.
- No good LISP Tree Language.
- No good LLVM IR tie in yet.
- One argument put to me: "there's no need for a universal syntax with deep learning—complexity IS the universal syntax."
- Another argument put to me: "sure it is still simple BUT there are 2 types of inventions: ones that get more complex over time and ones that no one uses"
Next Steps
Next steps is more of the same. Keep attempting to solve problems by simplifying the encoding of them to their essence (which happens to be Tree Notation, according to the theory). Build tools to make that easier and leverage those encodings. This year LSP will likely be a focus, Grid Notation, and the PLDB.
Tree Notation has a secret weapon: Simplicity does not go out of style. Slippers today look just like slippers in Egypt 3,000 years ago
Status of Predictions in Paper
My Tree Notation paper was my first ever attempt at writing a scientific paper and my understanding was that a good theory would make some refutable predictions. Here are the predictions I made in that paper and where they stand today.
Prediction 1: no structure will be found that cannot serialize to TN.
While this prediction has held, a number of people have commented that it doesn't predict much, as the same could really be said about most languages. Anything you can represent in Tree Notation you can represent in many encodings like XML.
What I should have predicted is something along the lines of this: Tree Notation is the smallest set of syntax rules that can represent all abstractions. I think trying to formalize a prediction along those lines would be a worthwhile endeavor (possibly for the reason that in trying to do what I just said, I may learn that what I just said doesn't make sense).
Prediction 2: TLs will be found for every popular 1DL.
This one has not come true yet. While I have made many public Tree Languages myself and many more private ones, and I have prototyped many with other people, the net utility of Tree Languages is not high enough that people are rushing to design these things. Many people have kicked the tires, but things are not good enough and there is a lack of demand.
On the supply side, it has turned out to be a bit harder to design useful Tree Languages than I expected. Not by 100x, but maybe by as much as 10x. I learned a lot of bad design patterns not to put in Tree Languages. I learned that bad tooling will force compromises in language design. For example, before I had syntax highlighting I relied on weird punctuation like "@" vs "#" prefixes for distinguishing types. I also learned a lot of patterns that seem to be useful in Tree Languages (like word suffixes for types). I learned good tooling leads to simpler and better languages.
Prediction 3: Tree Oriented Programming (TOP) will supersede Object Oriented Programming.
This one has not come true yet. While there is a tremendous amount of what I would call "Tree Oriented Programming" going on, programmers are still talking about objects and message passing and are not viewing the world as trees.
Prediction 4: The simplest 2D text encodings for neural networks will be TLs.
This one is a fun one. Definitely has not come true yet. But I've got a new attack vector to try and potentially crack it.
Status of Long Bet
After someone suggested it, I made a Long Bet predicting the rise of Tree Notation or a SUNSA within ten years of my initial Tree Notation post. Clearly I am far off from winning this bet at this point, as there are not any candidate languages even noted in TIOBE, never mind in the Top 10. However, IF I were to win the bet, I'd expect it wouldn't be until around 2025 that we'd see any candidate languages even appear on TIOBE's radar. In other words, absence of evidence is not evidence of absence.
As an aside, I really like the idea of Long Bet, and I'm hoping it may prompt someone to come up with a theoretical argument against a SUNSA that buries my ideas for good. Now, it would be very easy to take the opposing side of my bet with the simple argument that the idea of 7/10 TIOBE languages dropping by 2027 won't happen because such a shift has never happened so quickly. However, I'd probably reject that kind of challenge as non-constructive, unless it was accompanied by something like a detailed data-backed case with models showing potential speed limits on the adoption of any language (which would be a constructive contribution).
Organization Status
In 2019 I explored the idea of putting together a proper research group and a more formal organization around the idea.
I put the breaks on that for three reasons. The first is I just don't have a particularly keen interest in building an organization. I love to be part of a team, but I like to be more hands on with the ideas and the work of the team rather than the meta aspect. I've gotten great help for this project at an informal level, so there's no rush to formalize it. The second reason is I don't have a great aptitude for team building, and I'm not ready yet to dedicate the time to that. I get excited by ideas and am good at quickly explore new idea spaces, but being the captain who calmly guides the ship toward a known destination just isn't me right now. The third reason is just the idea remains too risky and ill-defined. If it's a good idea, growth will happen eventually, and there's no need to force it.
There is a loose confederation of folks I work on this idea with, but no formal organization with an office so far.
Conclusion
That's it for the recap of 2019! Tune in next year for a recap of 2020.
Related Posts
- Knowledge (2025)
- Ford (2025)
- Experiments (2025)
- Pretext (2025)
- What Science May Be (2025)
- Thinking in Parsers (2025)
- What is Particle Syntax? (2025)
- What is Mathematics? (2025)
- Why Define a New Language? (2024)
- Breckchain (2024)
- Particle Thinking (2024)
- Why Scroll? (2024)
- Microprogramming: A New Way to Program (2024)
- Particle Chain: A New Kind of Blockchain (2024)
- ETA!: A Measure of Evolution (2024)
- CheckBox: An Online + Offline Voting System (2024)
- The World Wide Scroll (2024)
- Download this Blog (2024)
- ICS: A Measure of Intelligence (2024)
- PTCRI: An Equation about Syntax Potential (2024)
- Patch: a micro language to make pretty deep links easy (2024)
- What can we learn from programming language version numbers? (2024)
- ScrollSets: A New Way to Store Knowledge (2024)
- Hot Coffee (2024)
- Final Tree Notation Report (2024)
- Words are Worse than Weights (2024)
- I thought we could build AI experts by hand (2023)
- A Proposal to Solve Government Forms Worldwide, Forever (2023)
- Use the Spine (2023)
- One Textarea (2022)
- Root Thinking (2022)
- Aftertext (2021)
- Scrolldown now has Dialogues (2021)
- The Public Domain Publishing Company (2021)
- Scroll Beta (2021)
- Building a TreeBase with 6.5 million files (2020)
- Dataset Needed (2020)
- Type the World (2020)
- Dreaming of a Logic Checked Language (2020)
- Removing the 2’s from Trinary Notation is a Terrible Idea. (2019)
- PC: Particle Complexity (2017)
- Parsers: a language for making languages (2017)
- Ohayo (2017)
- Tree Notation: an antifragile program notation (2017)
- A New Discovery in Computer Science: 2-Dimensional Programming Languages (2017)
- NudgePad: An IDE in Your Browser (2013)
- ScrollNet: A successor to the Internet (2013)
- Introducing Note (2012)
Notes
[1] Regardless of whether or not Tree Notation turns out to be a good idea, as one part of the effort to prove/disprove it I've built a lot of big datasets on languages and notations, which seem to be useful for other people. Credit for that is due to a number of people who advised me back in 2017 to "learn to research properly".
[2] Note that this means I am between 90-99% confident that Tree Notation is not a good idea. However, if it's a bad idea I am 40% confident the attempt to prove it a bad idea will have positive second-order effects. I am 50% confident that it will turn out I should have dropped this idea years ago, and it's a crackpot or Dunning–Kruger theory, and I'd be lying if I said I didn't recognize that as a highly probably scenario that has kept me up some nights.
[3] When it was first coming together, it wasn't a "book" as we think of books today and authorship is very fuzzy, but that doesn't affect things for my purposes here.
March 2, 2020 — I expect the future of healthcare will be powered by consumer devices. Devices you wear. Devices you keep in your home. In the kitchen. In the bathroom. In the medicine cabinet.
These devices record medical data. Lots of data. They record data from macro signals like heart rate, temperature, hydration, physical activity, oxygen levels, body temperature, brain waves, voice activity. They also record data from micro signals like antibodies, RNA expression levels, metabolomics, microbiome, etc.
Most of the data is collected passively and regularly. But sometimes your Health app prompts you to take out the digital otoscope or digital stethoscope to examine an unusual condition more closely.
This data is not stored in a network at the hospital you don't have access to. Instead you can access all of that data as easily as you can access your email. You can see that data on your wrist, on your phone, on your tablet.
You can understand that data too. You can click and dive into the definitions of every term. You can see what is meant by macro concepts like "VO2 max" and micro concepts like "RBC Count" or "BRC1 expression". Everything is explained precisely and thoroughly. Not only in words but in interactive visualizations that are customized to your body. The algorithms and models that turn the raw signals into higher level concepts are constantly improving.
When you get flu like symptoms, you don't alternate between anxiously Googling symptoms and scheduling doctor's appointments. Instead, your Health app alerts you that your signals have changed, it diagnoses your condition, shows you how your patterns compare to tens of thousands of people who have experienced similar changes, and makes recommendations about what to do next. You can even see forecasts of how your condition will change in the days ahead, and you can simulate how different treatment strategies might affect those outcomes.
You can not only reduce illness, but you can improve well-being too. You can see how your physical habits, social habits, eating habits, sleeping habits, correlate with hundreds of health and other signals.
Another benefit to all of this? Healthcare powered by consumer devices seems like it will be a lot cheaper.
Related posts
March 2, 2020 — A paradigm change is coming to medical records. In this post I do some back-of-the-envelope math to explore the changes ahead, both qualitative and quantitative. I also attempt to answer the question no one is asking: in the future will someone's medical record stretch to the moon?
Medical Records at the Provider
Medical records are generally stored with healthcare providers and currently at least 86%-96% of providers use an EHR system.
Americans visit their healthcare providers an average of 4 times per year.
If you were to plot the cumulative medical data storage use for the average American patient, it would look something like the abstract chart below, going up in small increments during each visit to the doctor:
A decade ago, this chart would not only show the quantity of a patient's medical data stored at their providers, but also the quantity of all of the patient's medical data. Simply put: people did not generally keep their own medical records. But this has changed.
Medical Records at Home
Now people own wearables like FitBits and Apple Watches. People use do-it-yourself services like 23andMe and uBiome. And in the not-too-distant future, the trend of ever-miniaturizing lab devices will enable advanced protocols at home. So now we have an additional line, reflecting the quantity of the patient's medical data from their own devices and services:
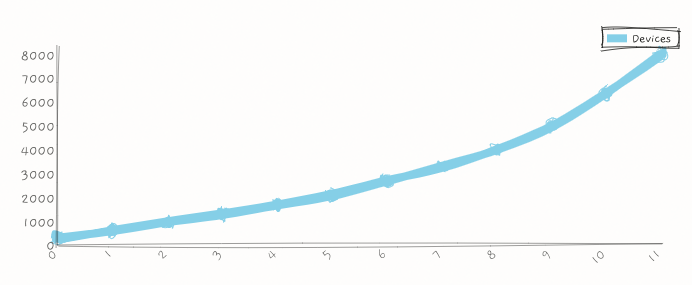
When you put the two together you can see the issue:
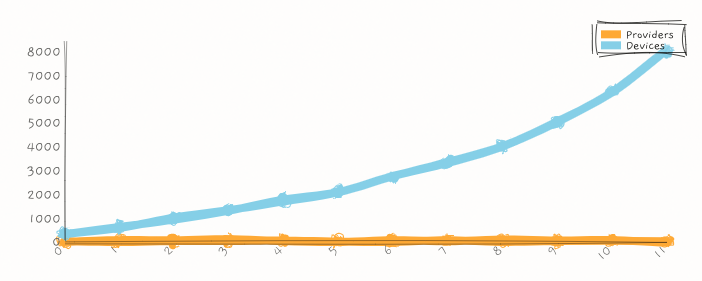
Patients will log far more medical data on their own than they do at their providers'.
Implication #1: Change in Ownership
It seems highly likely then that the possession of medical records will flip from providers to patients. I now have 120 million heart rate readings from my own devices, while I might have a few dozen from my providers. The gravity of the former will be harder and harder to overcome.
Patients won't literally be in possession of their records. While some nerdy patients—the kind of people who host their own email servers—might host their own open records, most will probably use a service provider. Prior attempts at creating personal health record systems, including some from the biggest companies around, did not catch on. But back then we didn't have the exponential increase in personal medical data, and the data gravity that creates, that we have today.
I'm noticing a number of startups innovating along this wave (and if you know of other exciting ones, please share!). However, it seems that Apple Health and FitBit are in strong positions to emerge as leading providers of PHR as-a-service due to data gravity.
Implication #2: Change in Design
Currently EHR providers like Epic design and sell their products for providers first. If patients start making the decisions about which PHR tool to use, product designers will have to consider the patient experience first.
I think this extends beyond products to standards. While there are some great groups working on open standards for medical records, none, as far as I'm aware, consider patients as a first class user of their grammars and definitions. I personally think that a standards system can be developed that is fully understandable by patients without compromising on the needs of experts.
One simple UX innovation in medical records that I love is BlueButton Developed by the V.A. in 2010, BlueButton allows patients to download their entire medical records as a single file. While the grammar and parse-ability of BlueButton leave much to be desired, I think the concept of "your entire medical history in a single document" is a very elegant design.
Implication #3: Change in Scale
As more and more different devices contribute to patients' medical documents, what will the documents look like and how big will they get? Will someone's medical records stretch to the moon?
I think the BlueButton concept provides a helpful mental model here: you can visualize any person's medical record as a single document. Let's call this document an MRD for "Medical Record Document".
Let's imagine a 30 year old in 2050. They'd have around 11,200 days worth of data (I included some days for in utero records). Let's say there are 4 "buckets" of medical data in their MRD:
- Time series sensor data
- Image and point cloud data
- Data from microbio protocols like genomic and metabolomic data
- Text data
This is my back of the envelope math of how many megabytes of data might be in each of those buckets:
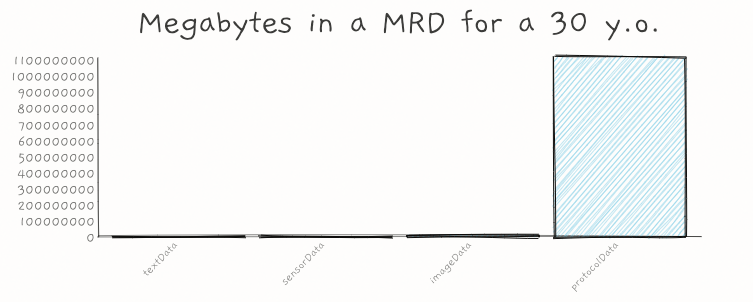
I am assuming that sensor development advances a lot in 40 years. I am assuming our patient of the future has:
- 1,000 different passive 1-D biomedical sensors recording a reading once per second
- 10 different passive photo and 3-D cameras capturing 100 frames per day each
- 100 passive microbio systems generating 1GB of data per protocol (don't ask me how these will work, maybe something like this)
- For good measure I throw in a fourth bucket of 100k characters a day of plain text data
By my estimate this person would log about 100GB of medical data per day, or about 100 petabytes of data in 30 years. That would fit on roughly 1,000 of today's hard drives.
If you printed this record in a single doc, on 8.5 x 11 sheets of paper, in a human readable form—i.e. print the text, print the time series data as line charts, print the images, and print various types of output for the various protocols—the printed version would be about 138,000,000 pages which laid end-to-end would stretch 24,000 miles. If you printed it double-sided and stacked it like a book it would be 4.2 miles high.
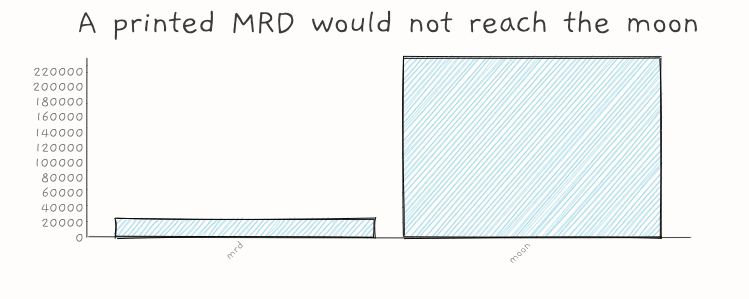
So for a 120 year old in 2140, their printed MRD would not reach the moon. Though it may make it halfway there.
Related posts
My keyboard, if you removed the symbols from the typewriter and computer eras. Try it yourself.
February 25, 2020 — One of the questions I often come back to is this: how much of our collective wealth is inherited by our generation versus created by our generation?
I realized that the keys on the keyboard in front of me might make a good dataset to attack that problem. So I built a small interactive experiment to explore the history of the keys on my keyboard.
The Five Waves of Symbols
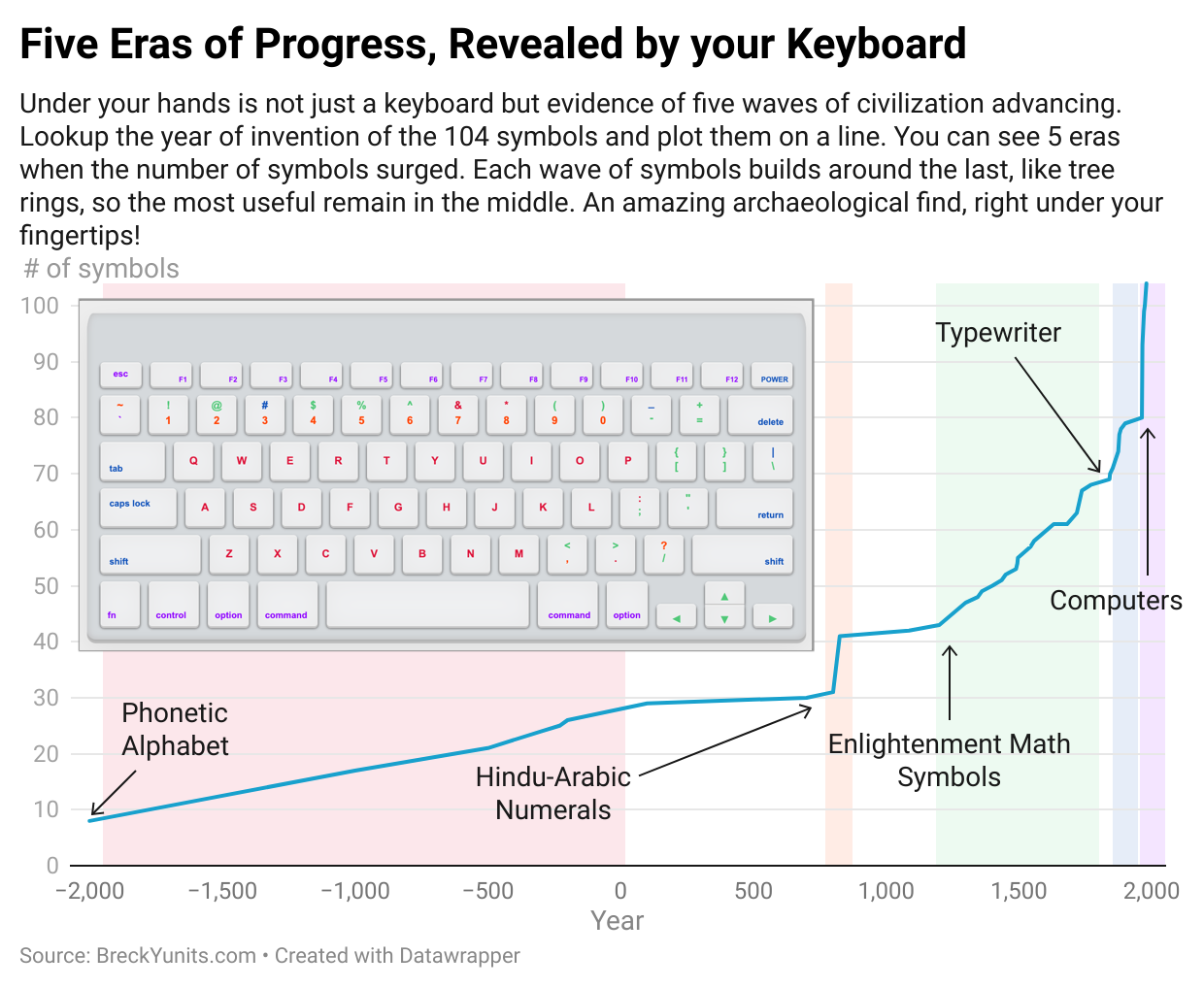
Painting with broad strokes, there were approximately five big waves of inventions that have left their mark on the keyboard:
- 1. The first wave was the invention of the phonetic alphabet letters.
- 2. The second wave was the Hindu-Arabic Numerals.
- 3. The third wave was the mathematical punctuation of the Enlightenment period.
- 4. The fourth wave was the invention of the typewriter.
- 5. And the fifth and most recent wave was the invention of the personal computer.
Concentric Circles
An interesting pattern that I never saw before is how the five waves above are roughly arranged in circles.
The oldest symbols (letters) are close to the center, followed by the Hindu-Arabic Numbers, surrounded by the punctuation of the Englightenment, surrounded by the keys of the typewriter, surrounded by the recent additions in the P.C. era.
(Again, I'm painting with broad strokes, but I found that to be an interesting pattern.)
Standing on the Shoulders of Giants
All of these waves happened before my generation.
Almost all of them before any generation alive today.
The keyboard dataset provides strong evidence that most of our collective wealth is inherited.
Build Notes
I got this idea last week and couldn't get it out of my head. Yesterday I took a quick crack at it. I didn't have much time to spare, just enough to explore the big ideas.
I started by typing all the characters on my keyboard into a dataset. Then I dug up some years for a handful of the symbols.
Next I found the great Apple CSS keyboard. I stitched together the two and it seemed to be at least mildly interesting so I opted to continue.
I then flushed out most of the dataset.
Finally I played around with a number of visualization effects. At first I thought heatmaps would work well, and tried a few variations on that, but wasn't happy with anything. I posted my work-in-progress to a few friends last night and called it a day. Today I switched to the "disappearing keys" visualization. That definitely felt like a better approach than the heatmap.
I made the thing as fun as I could given time constraints and then shipped.
April 28, 2024 — Update: I finally got around to making a chart with this data and adding colors to the keys.
Dataset
February 21, 2020 — One of the most unpopular phrases I use is the phrase "Intellectual Slavery Laws".
I think perhaps the best term for copyright and patent laws is "Intellectual Monopoly Laws". When called by that name, it is obvious that there should be careful scrutiny of these kinds of laws.
However, the industry insists on using the false term "Intellectual Property Laws."
Instead of wasting my breath trying to pull them away from the property analogy, lately I've leaned into it and completed the analogy for them. So let me explain "Intellectual Slavery Laws".
Intellectual Slavery Laws
As far as I can figure, you cannot have Property Rights and "Intellectual Property" rights. Having both is logically inconsistent. My computer is my property. However, by law there are billions of peaceful things I cannot do on my computer. Therefore, my computer is not my property.
Unless of course, the argument is that my computer is my property, but some copyright and patent holders have property rights over me, so their property rights allow them to restrict my freedom. I still get rights over my property. But other people get rights over me. Property Rights and Intellectual Slavery Laws can logically co-exist! Logical inconsistency solved!
The First Step to Having a Logical Debate
We can have a logical debate about whether we should have an Intellectual Slavery System, Intellectual Slavery Laws, Intellectual Slavery Law Schools, Intellectual Slavery Lawyers, etc. But we cannot have a logical debate about Intellectual Property Laws. Because the term itself is not logical.
I know, having now used this term with a hundred different people, that this is a not a popular thing to say. But I think someone needs to say it. Do we really think we are going to be an interplanetary species and solve the world's biggest challenges if we keep 99+% of the population in intellectual chains?
Errata
- "They are stealing my IP." What would your "IP" be if you weren't "stealing" inventions like words, the alphabet, numbers, rules of physics, etc, that were developed and passed down over thousands of years?
- "But shouldn't creators be paid for their work?" Yes. Pay them upon delivery. No need for monopolies. Does a janitor, after cleaning a room, get to charge everyone who enters a royalty for 100 years?
- "Not a big deal—rights expire after a certain time." The fact that Copyrights and Patents expire on an arbitrary date is more proof that these should not be called property rights.
- "This is not an urgent problem." I think Intellectual Slavery Laws have deep, direct connections to major problems of our time including healthcare, education, and inequality problems.
- "This is anti-capitalist." This is pro-property rights.
- "What about trademarks?" Centralized naming registries like Trademarks are fine, as long as anyone can start a registry. Posing as someone else isn't an IP violation, it is fraud. Already consequences for that.
- "If you think the U.S. is bad, go visit China." I acknowledge that we have tremendous intellectual freedoms in the U.S., especially compared to other countries. I don't take freedom of speech and freedom of press for granted. However, I believe we are capping ourselves greatly by not legalizing full intellectual freedom.
- "This is offensive to people suffering from physical slavery or its lingering effects." The people who would benefit the most from abolishing Intellectual Slavery laws are the same people who have suffered the most from physical slavery systems.
- "I am an Intellectual Property lawyer and this offends me." The phrase "Intellectual Property" offends me.
- "What about Trade Secrets?" Trade secrets and private information are fine. No one should be forced to publish anything. But once you publish something, let it thrive.
- "Can't we just copyleft our way to the promised land?" Perhaps, but why lie about the system in the meanwhile?
- One difference between Physical Slavery and Intellectual Slavery is in the latter it is slavery from a million masters.
- This woman is amazing.

A poster from the 1850's promoting Folsom's Mercantile College in Ohio. The poster includes a motto (which I boxed in green) that I think is great guidance: Integrity and Perseverance in Business ensure success. Image Source.
February 9, 2020 — In 1851 Ezekiel G. Folsom incorporated Folsom's Mercantile College in Ohio.
Folsom's taught bookkeeping, banking, and railroading.
Their motto was: "Integrity and Perseverance in Business ensure success".
Guess who went there?
Credit
Richard Brhel of placepeep shared this quote the other day on StartupSchool. He saw the quote on a poster years ago when he was helping a digitization effort in Ohio. I had never seen this exact quote before so wanted to transcribe it for the web.
January 29, 2020 — In this long post I'm going to do a stupid thing and see what happens. Specifically I'm going to create 6.5 million files in a single folder and try to use Git and Sublime and other tools with that folder. All to explore this new thing I'm working on.
TreeBase is a new system I am working on for long-term, strongly-typed collaborative knowledge bases. The design of TreeBase is dumb. It's just a folder with a bunch of files encoded with Tree Notation. A row in a normal SQL table in TreeBase is roughly equivalent to a file. The filenames serve as IDs. Instead of each using an optimized binary storage format it just uses plain text like UTF-8. Field names are stored alongside the values in every file. Instead of starting with a schema you can just start adding files and evolve your schema and types as you go.
For example, in this tiny demo TreeBase of the planets the file mars.planet looks like this:
diameter 6794
surfaceGravity 4
yearsToOrbitSun 1.881
moons 2
TreeBase is composed of 3 key ingredients.
Ingredient 1: A folder All that TreeBase requires is a file system (although in theory you could build an analog TreeBase on paper). This means that you can use any tools on your system for editing files for editing your database.
Ingredient 2: Git Instead of having code to implement any sort of versioning or metadata tracking, you just use Git. Edit your files and use Git for history, branching, collaboration, etc. Because Tree Notation is a line and word based syntax it meshes really well with Git workflows.
Ingredient 3: Tree Notation The Third Ingredient for making a TreeBase is Tree Notation. Both schemas and data use Tree Notation. This is a new very simple syntax for encoding strongly typed data. It's simple, extensible, and plays well with Git.
TreeBase Compared to Other Database Systems
Probably hundreds of billions of dollars has gone into designing robust database systems like SQL Server, Oracle, PostgreSQL, MySQL, MongoDB, SQLite and so forth. These things run the world. They are incredibly robust and battle-hardened. Everything that can happen is thought of and planned for, and everything that can go wrong has gone wrong (and learned from). These databases can handle trillions of rows, can conduct complex real-time transactions, and survive disasters of all sort. They use sophisticated binary formats and are tuned for specific file systems. Thousands of people have gotten their PhD's working on database technology.
TreeBase doesn't have any of that. TreeBase is stupid. It's just a bunch of files in a folder.
You might be asking yourself "Why use TreeBase at all when great databases exist?". To further put the stupidity of the current TreeBase design into perspective, the Largest Git Repo on the Planet is Windows which has 3.5 million files. I'm going to try and create a repo with 6.5 million files on my laptop.
Even if you think TreeBase is silly aren't you curious what happens when I try to put 6.5 million files into one folder? I kind of am. If you want an explanation of why TreeBase, I'll get to that near the end of this post.
But first...
Let's Break TreeBase
Here again is a demo TreeBase with only 8 files.
The biggest TreeBase I work with has on the order of 10,000 files. Some files have thousands of lines, some just a handful.
While TreeBase has been great at this small scale, a question I've been asked, and have wondered myself, is what happens when a TreeBase gets too big?
I'm about to find out, and I'll document the whole thing.
Every time something bad happens I'll include a 💣.
Choosing a Topic
TreeBase is meant for knowledge bases. So all TreeBases center around a topic.
To test TreeBase on a big scale I want something realistic. I wanted to choose some big structured database that thousands of people have contributed to that's been around for a while and see what it would look like as a TreeBase.
IMDB is just such a database and amazingly makes a lot of their data available for download. So movies will be the topic and the IMDB dataset will be my test case.
The Dataset
First I grabbed the data. I downloaded the 7 files from IMDB to my laptop. After unzipping, they were about 7GB.
One file, the 500MB title.basics.tsv, contained basic data for all the movie and shows in the database.
Here's what that file looks like with head -5 title.basics.tsv:
| tconst | titleType | primaryTitle | originalTitle | isAdult | startYear | endYear | runtimeMinutes | genres |
|---|---|---|---|---|---|---|---|---|
| tt0000001 | short | Carmencita | Carmencita | 0 | 1894 | \N | 1 | Documentary,Short |
| tt0000002 | short | Le clown et ses chiens | Le clown et ses chiens | 0 | 1892 | \N | 5 | Animation,Short |
| tt0000003 | short | Pauvre Pierrot | Pauvre Pierrot | 0 | 1892 | \N | 4 | Animation,Comedy,Romance |
| tt0000004 | short | Un bon bock | Un bon bock | 0 | 1892 | \N | \N | Animation,Short |
This looks like a good candidate for TreeBase. With this TSV I can create a file for each movie. I don't need the other 6 files for this experiment, though if this was a real project I'd like to merge in that data as well (in that case I'd probably create a second TreeBase for the names in the IMDB dataset).
Doing a simple line count wc -l title.basics.tsv I learn that there are around 6.5M titles in title.basics.tsv. With the current implementation of TreeBase this would be 6.5M files in 1 folder. That should handily break things.
The TreeBase design calls for me to create 1 file for every row in that TSV file. To again stress how dumb this design is keep in mind a 500MB TSV with 6.5M rows can be parsed and analyzed with tools like R or Python in seconds. You could even load the thing near instantly into a SQLite database and utilize any SQL tool to explore the dataset. Instead I am about to spend hours, perhaps days, turning it into a TreeBase.
From 1 File to 6.5 Million Files
What will happen when I split 1 file into 6.5 million files? Well, it's clear I am going to waste some space.
A file doesn't just take up space for its contents: it also has metadata. Every file contains metadata like permissions, modification time, etc. That metadata must take up some space, right? If I were to create 6.5M new files, how much extra space would that take up?
My MacBook uses APFS It can hold up to 9,000,000,000,000,000,000 files. I can't easily find hard numbers on how much metadata one file takes up but can at least start with a ballpark estimate.
I'll start by considering the space filenames will take up.
In TreeBase filenames are composed of a permalink and a file extension. The file extension is to make it easier for editors to understand the schema of a file. In the planets TreeBase above, the files all had the planet extension and there is a planet.grammar file that contains information for the tools like syntax highlighters and type checkers. For my new IMDB TreeBase there will be a similar title.grammar file and each file will have the ".title" extension. So that is 6 bytes per file. Or merely 36MB extra for the file extensions.
Next, the body of each filename will be a readable ID. TreeBase has meaningful filenames to work well with Git and existing file tools. It keeps things simple. For this TreeBase, I will make the ID from the primaryTitle column in the dataset. Let's see how much space that will take.
I'll try xsv select primaryTitle title.basics.tsv | wc.
💣 I got this error:
CSV error: record 1102213 (line: 1102214, byte: 91470022): found record with 8 fields, but the previous record has 9 fields
1102213 3564906 21815916
XSV didn't like something in that file. Instead of getting bogged down, I'll just work around it.
I'll build a subset from the first 1M rows with head -n 1000000 title.basics.tsv > 1m.title.basics.tsv. Now I will compute against that subset with xsv select primaryTitle 1m.title.basics.tsv | wc. I get 19751733 so an average of 20 characters per title.
I'll combine that with the space for file extension and round that to say 30 extra bytes of file information for each of the 6.5 million titles. So about 200MB of extra data required to split this 500MB file into filenames. Even though that's a 50% increase, 200MB is dirt cheap so that doesn't seem so bad.
You may think that I could save a roughly equivalent amount by dropping the primaryTitle field. However, even though my filenames now contain information from the title, my permalink schema will generally distort the title so I need to preserve it in each file and won't get savings there. I use a more restrictive character set in the permalink schema than the file contents just to make things like URLs easier.
Again you might ask why not just an integer for the permalink? You could but that's not the TreeBase way. The human readable permalinks play nice with tools like text editors, URLs, and Git. TreeBase is about leveraging software that already works well with file systems. If you use meaningless IDs for filenames you do away with one of the very useful features of the TreeBase system.
But I won't just waste space in metadata. I'm also going to add duplicate data to the contents of each file. That's because I won't be storing just values like 1999 but I'll also be repeating column names in each file like startYear 1999.
How much space will this take up? The titles file has 9 columns and using head -n 1 1m.title.basics.tsv | wc I see that adds up to 92 bytes. I'll round that up to 100, and multiple by 6.5M, and that adds up to about 65,000,000 duplicate words and 650MB. In other words the space requirements roughly doubled (of course, assuming no compression by the file system under the hood).
You might be wondering why not just drop the column names from each file? Again, it's just not the TreeBase way. By including the column names, each file is self-documenting. I can open up any file with a text editor and easily change it.
So to recap: splitting this 1 TSV file into 6.5 million files is going to take up 2-3x more space due to metadata and repetition of column names.
Because this is text data, that's actually not so bad. I don't foresee problems arising from wasted disk space.
Foreseeing Speed Problems
Before I get to the fun part, I'm going to stop for a second and try and predict what the problems are going to be.
Again, in this experiment I'm going to build and attempt to work with a TreeBase roughly 1,000 times larger than any I've worked with before. A 3 order of magnitude jump.
Disk space won't be a problem. But are the software tools I work with on a day-to-day basis designed to handle millions of files in a single folder? How will they hold up?
- Bash How will the basics like
lsandgrephold up in a folder with 6.5M files? - Git How slow will
git statusbe? What aboutgit addandgit commit? - Sublime Text Will I even be able to open this folder in Sublime Text? Find/replace is something I so commonly use, will that work? How about regex find/replace?
- Finder Will I be able to visually browse around?
- TreeBase Scripts Will my simple TreeBase scripts be usable? Will I be able to type check a TreeBase?
- GitHub Will GitHub be able to handle 6.5M files?
Proceeding in Stages
Since I am going to make a 3 order of magnitude jump, I figured it would be best to make those jumps one at a time.
Actually, to be smart, I will create 5 TreeBases and make 4 jumps. I'll make 1 small TreeBase for sanity checks and then four where I increase by 10x 3 times and see how things hold up.
First, I'll create 5 folders: mkdir 60; mkdir 6k; mkdir 60k; mkdir 600k; mkdir 6m
Now I'll create 4 smaller subsets for the smaller bases. For the final 6.5M base I'll just use the original file.
head -n 60 title.basics.tsv > 60/titles.tsv
head -n 6000 title.basics.tsv > 6k/titles.tsv
head -n 60000 title.basics.tsv > 60k/titles.tsv
head -n 600000 title.basics.tsv > 600k/titles.tsv
Now I'll write a script to turn those TSV rows into TreeBase files.
#! /usr/local/bin/node --use_strict
const { jtree } = require("jtree")
const { Disk } = require("jtree/products/Disk.node.js")
const folder = "600k"
const path = `${__dirname}/../imdb/${folder}.titles.tsv`
const tree = jtree.TreeNode.fromTsv(Disk.read(path).trim())
const permalinkSet = new Set()
tree.forEach(node => {
let permalink = jtree.Utils.stringToPermalink(node.get("primaryTitle"))
let counter = ""
let dash = ""
while (permalinkSet.has(permalink + dash + counter)) {
dash = "-"
counter = counter ? counter + 1 : 2
}
const finalPermalink = permalink + dash + counter
permalinkSet.add(finalPermalink)
// Delete Null values:
node.forEach(field => {
if (field.getContent() === "\\N") field.destroy()
})
if (node.get("originalTitle") === node.get("primaryTitle")) node.getNode("originalTitle").destroy()
Disk.write(`${__dirname}/../imdb/${folder}/${finalPermalink}.title`, node.childrenToString())
})
The script iterates over each node and creates a file for each row in the TSV.
This script required a few design decisions. For permalink uniqueness, I simply keep a set of titles and number them if a name comes up multiple times. There's also the question of what to do with nulls. IMDB sets the value to \N. Generally the TreeBase way is to not include the field in question. So I filtered out null values. For cases where primaryTitle === originalTitle, I stripped the latter. For the Genres field, it's a CSV array. I'd like to make that follow the TreeBase convention of a SSV. I don't know all the possibilities though without iterating, so I'll just skip this for now.
Here are the results of the script for the small 60 file TreeBase:

Building the Grammar File
The Grammar file adds some intelligence to a TreeBase. You can think of it as the schema for your base. TreeBase scripts can read those Grammar files and then do things like provide type checking or syntax highlighting.
Now that we have a sample title file, I'm going to take a first pass at the grammar file for our TreeBase. I copied the file the-photographical-congress-arrives-in-lyon.title and pasted it into the right side of the Tree Language Designer. Then I clicked Infer Prefix Grammar.
That gave me a decent starting point for the grammar:
inferredLanguageNode
root
inScope tconstNode titleTypeNode primaryTitleNode originalTitleNode isAdultNode startYearNode runtimeMinutesNode genresNode
keywordCell
anyCell
bitCell
intCell
tconstNode
crux tconst
cells keywordCell anyCell
titleTypeNode
crux titleType
cells keywordCell anyCell
primaryTitleNode
crux primaryTitle
cells keywordCell anyCell anyCell anyCell anyCell anyCell anyCell
originalTitleNode
crux originalTitle
cells keywordCell anyCell anyCell anyCell anyCell anyCell anyCell anyCell anyCell
isAdultNode
crux isAdult
cells keywordCell bitCell
startYearNode
crux startYear
cells keywordCell intCell
runtimeMinutesNode
crux runtimeMinutes
cells keywordCell bitCell
genresNode
crux genres
cells keywordCell anyCell
The generated grammar needed a little work. I renamed the root node and added catchAlls and a base "abstractFactType". The Grammar language and tooling for TreeBase is very new, so all that should improve as time goes on.
My title.grammar file now looks like this:
titleNode
root
pattern \.title$
inScope abstractFactNode
keywordCell
anyCell
bitCell
intCell
abstractFactNode
abstract
cells keywordCell anyCell
tconstNode
crux tconst
extends abstractFactNode
titleTypeNode
crux titleType
extends abstractFactNode
primaryTitleNode
crux primaryTitle
extends abstractFactNode
catchAllCellType anyCell
originalTitleNode
crux originalTitle
extends abstractFactNode
catchAllCellType anyCell
isAdultNode
crux isAdult
cells keywordCell bitCell
extends abstractFactNode
startYearNode
crux startYear
cells keywordCell intCell
extends abstractFactNode
runtimeMinutesNode
crux runtimeMinutes
cells keywordCell intCell
extends abstractFactNode
genresNode
crux genres
cells keywordCell anyCell
extends abstractFactNode
Next I coped that file into the 60 folder with cp /Users/breck/imdb/title.grammar 60/. I have the jtree package installed on my local machine so I registered this new language with that with the command jtree register /Users/breck/imdb/title.grammar. Finally, I generated a Sublime syntax file for these title files with jtree sublime title #pathToMySublimePluginDir.
Now I have rudimentary syntax highlighting for these new title files:
Notice the syntax highlighting is a little broken. The Sublime syntax generating still needs some work.
Anyway, now we've got the basics done. We have a script for turning our CSV rows into Tree Notation files and we have a basic schema/grammar for our new TreeBase.
Let's get started with the bigger tests now.
A 6k TreeBase
I'm expecting this to be an easy one. I update my script to target the 6k files and run it with /Users/breck/imdb/build.js. A little alarmingly, it takes a couple of seconds to run:
real 0m3.144s
user 0m1.203s
sys 0m1.646s
The main script is going to iterate over 1,000x as many items so if this rate holds up it would take 50 minutes to generate the 6M TreeBase!
I do have some optimization ideas in mind, but for now let's explore the results.
First, let me build a catalog of typical tasks that I do with TreeBase that I will try to repeat with the 6k, 60k, 600k, and 6.5M TreeBases.
I'll just list them in Tree Notation:
task ls
category bash
description
task open sublime
category sublime
description Start sublime in the TreeBase folder
task sublime responsiveness
category sublime
description scroll and click around files in the treebase folder and see how responsive it feels.
task sublime search
category sublime
description find all movies with the query "titleType movie"
task sublime regex search
category sublime
description find all comedy movies with the regex query "genres ._Comedy._"
task open finder
category finder
description open the folder in finder and browse around
task git init
category git
description init git for the treebase
task git first status
category git
description see git status
task git first add
category git
description first git add for the treebase
task git first commit
category git
description first git commit
task sublime editing
category sublime
description edit some file
task git status
category git
description git status when there is a change
task git add
category git
description add the change above
task git commit
category git
description commit the change
task github push
category github
description push the treebase to github
task treebase start
category treebase
description how long will it take to start treebase
task treebase error check
category treebase
description how long will it take to scan the base for errors.
💣 Before I get to the results, let me note I had 2 bugs. First I needed to update my title.grammar file by adding a cells fileNameCell to the root node and also adding a fileNameCell line. Second, my strategy above of putting the CSV file for each TreeBase into the same folder as the TreeBase was not ideal as Sublime Text would open that file as well. So I moved each file up with mv titles.tsv ../6k.titles.tsv.
The results for 6k are below.
| category | description | result |
|---|---|---|
| bash | ls | instant |
| sublime | Start sublime in the TreeBase folder | instant |
| sublime | scroll and click around files in the treebase folder and see how responsive it feels. | nearInstant |
| sublime | find all movies with the query "titleType movie" | neaerInstant |
| sublime | find all comedy movies with the regex query "genres ._Comedy._" | nearInstant |
| finder | open and browse | instant |
| git | init git for the treebase | instant |
| git | see git status | instant |
| git | first git add for the treebase | aFewSeconds |
| git | first git commit | instant |
| sublime | edit some file | instant |
| git | git status when there is a change | instant |
| git | add the change above | instant |
| git | commit the change | instant |
| github | push the treebase to github | ~10 seconds |
| treebase | how long will it take to start treebase | instant |
| treebase | how long will it take to scan the base for errors. | nearInstant |
So 6k worked without a hitch. Not surprising as this is in the ballpark of where I normally operate with TreeBases.
Now for the first of three 10x jumps.
A 60k TreeBase
💣 This markdown file that I'm writing was in the parent folder of the 60k directory and Sublime text seemed to be slowing a bit, so I closed Sublime and created a new unrelated folder to hold this writeup separate from the TreeBase folders.
The build script for the 60k TreeBase took 30 seconds or so, as expected. I can optimize for that later.
I now repeat the tasks from above to see how things are holding up.
| category | description | result |
|---|---|---|
| bash | ls | aFewSeconds |
| sublime | Start sublime in the TreeBase folder | aFewSeconds with Beachball |
| sublime | scroll and click around files in the treebase folder and see how responsive it feels. | instant |
| sublime | find all movies with the query "titleType movie" | ~20 seconds with beachball |
| sublime | find all comedy movies with the regex query "genres ._Comedy._" | ~20 seconds with beachball |
| git | init git for the treebase | instant |
| finder | open and browse | 6 seconds |
| git | see git status | nearInstant |
| git | first git add for the treebase | 1 minute |
| git | first git commit | 10 seconds |
| sublime | edit some file | instant |
| git | git status when there is a change | instant |
| git | add the change above | instant |
| git | commit the change | instant |
| github | push the treebase to github | ~10 seconds |
| treebase | how long will it take to start treebase | ~10 seconds |
| treebase | how long will it take to scan the base for errors. | ~5 seconds |
Uh oh. Already I am noticing some scaling delays with a few of these tasks.
💣 The first git add took about 1 minute. I used to know the internals of Git well but that was a decade ago and my knowledge is rusty.
I will now look some stuff up. Could Git be creating 1 file for each file in my TreeBase? I found this post from someone who created a Git repo with 1.7M files which should turn out to contain useful information. From that post it looks like you can indeed expect 1 file for Git for each file in the project.
The first git commit took about 10 seconds. Why? Git printed a message about Autopacking. It seems Git will combine a lot of small files into packs (perhaps in bundles of 6,700, though I haven't dug in to this) to speed things up. Makes sense.
💣 I forgot to mention, while doing the tasks for the 60k TreeBase, my computer fan kicked on. A brief look at Activity Monitor showed a number of mdworker_shared processes using single digit CPU percentages each, which appears to be some OS level indexing process. That's hinting that a bigger TreeBase might require at least some basic OS/file system config'ing.
Besides the delays with git everything else seemed to remain fast. The 60k TreeBase choked a little more than I'd like but seems with a few tweaks things could remain screaming fast.
Let's move on to the first real challenge.
A 600k TreeBase
💣 The first problem I hit immediately in that my build.js is not efficient. I hit a v8 out of memory error. I could solve this by either 1) streaming the TSV one row at a time or 2) cleaning up the unoptimized jtree library to handle bigger data better. I chose to spend a few minutes and go with option 1).
💣 It appears the first build script started writing files to the 600k directory before it failed. I had to rm -rf 600k/ and that took a surprisingly long time. Probably a minute or so. Something to keep an eye on.
💣 I updated my build script to use streams. Unfortunately the streaming csv parser I switched to choked on line 32546. Inspecting that vicinity it was hard to detect what it was breaking on. Before diving in I figured I'd try a different library.
💣 The new library seemed to be working but it was taking a while so I added some instrumentation to the script. From those logs the new script seems to generate about 1.5k files per second. So should take about 6 minutes for all 600k. For the 6.5M files, that would grow to an hour, so perhaps there's more optimization work to be done here.
💣 Unfortunately the script exited early with:
Error: ENAMETOOLONG: name too long, open '/Users/breck/imdbPost/../imdb/600k/mord-an-lottomillionr-karl-hinrich-charly-l.sexualdelikt-an-carola-b.bankangestellter-zweimal-vom-selben-bankruber-berfallenmord-an-lottomillionr-karl-hinrich-charly-l.sexualdelikt-an-carola-b.bankangestellter-zweimal-vom-selben-bankruber-berfallen01985nncrimenews.title'
Turns out the Apple File System has a filename size limit of 255 UTF-8 characters so this error is understandable. However, inspecting the filename shows that for some reason the permalink was generated by combining the original title with the primary title. Sounds like a bug.
I cd into the 600k directory to see what's going on.
💣 Unfortunately ls hangs. ls -f -1 -U seems to go faster.
The titles look correct. I'm not sure why the script got hung up on that one entry. For now I'll just wrap the function call in a Try/Catch and press on. I should probably make this script resumable but will skip that for now.
Rerunning the script...it worked! That line seemed to be the only problematic line.
We now have our 600k TreeBase.
| category | description | result |
|---|---|---|
| bash | ls | ~30 seconds |
| sublime | Start sublime in the TreeBase folder | failed |
| sublime | scroll and click around files in the treebase folder and see how responsive it feels. | X |
| sublime | find all movies with the query "titleType movie" | X |
| sublime | find all comedy movies with the regex query "genres ._Comedy._" | X |
| finder | open and browse | 3 minutes |
| git | init git for the treebase | nearInstant |
| git | see git status | 6s |
| git | first git add for the treebase | 40 minutes |
| git | first git commit | 10 minutes |
| sublime | edit some file | X |
| git | git status when there is a change | instant |
| git | add the change above | instant |
| git | commit the change | instant |
| github | push the treebase to github | ~10 seconds |
| treebase | how long will it take to start treebase | ~10 seconds |
| treebase | how long will it take to scan the base for errors. | ~5 seconds |
💣 ls is now nearly unusable. ls -f -1 -U takes about 30 seconds. A straight up ls takes about 45s.
💣 Sublime Text failed to open. After 10 minutes of 100% CPU usage and beachball'ing I force quit the program. I tried twice to be sure with the same result.
💣 mdworker_shared again kept my laptop running hot. I found a way of potentially disabling Mac OS X Spotlight Indexing of the IMDB folder.
💣 Opening the 600k folder in Apple's Finder gave me a loading screen for about 3 minutes
At least it eventually came up:
Now, how about Git?
💣 The first git add . took 40 minutes! Yikes.
real 39m30.215s
user 1m19.968s
sys 13m49.157s
💣 git status after the initial git add took about a minute.
💣 The first git commit after the git add took about 10 minutes.
GitHub turns out to be a real champ. Even with 600k files the first git push took less than 30 seconds.
real 0m22.406s
user 0m2.657s
sys 0m1.724s
The 600k repo on GitHub comes up near instantly. GitHub just shows the first 1k out of 600k files which I think is a good compromise, and far better than a multiple minute loading screen.
💣 Sadly there doesn't seem to be any pagination for this situation on GitHub, so not sure how to view the rest of the directory contents.
I can pull up a file quickly on GitHub, like the entry for License to Kill.
How about editing files locally? Sublime is no use so I'll use vim. Because ls is so slow, I'll find the file I want to edit on GitHub. Of course because I can't find pagination in GitHub I'll be limited to editing one of the first 1k files. I'll use just that License to Kill entry.
So the command I use vim 007-licence-to-kill.title. Editing that file is simple enough. Though I wish we had support for Tree Notation in vim to get syntax highlighting and such.
💣 Now I do git add .. Again this takes a while. What I now realize is that my fancy command prompt does some git status with every command. So let's disable that.
After going in and cleaning up my shell (including switching to zsh) I've got a bit more performance back on the command line.
💣 But just a bit. A git status still takes about 23 seconds! Even with the -uno option it takes about 15 seconds. This is with 1 modified file.
Now adding this 1 file seems tricky. Most of the time I do a git status and see that I want to add everything so I do a git add ..
💣 But I tried git add . in the 600k TreeBase and after 100 seconds I killed the job. Instead I resorted to git add 007-licence-to-kill.title which worked pretty much instantly.
💣 git commit for this 1 change took about 20 seconds. Not too bad but much worse than normal.
git push was just a few seconds.
I was able to see the change on GitHub instantly. Editing that file on GitHub and committing was a breeze. Looking at the change history and blame on GitHub was near instant.
Git blame locally was also just a couple of seconds.
Pause to Reflect
So TreeBase struggles at the 600k level. You cannot just use TreeBase at the 100k level without preparing your system for it. Issues arise with GUIs like Finder and Sublime, background file system processes, shells, git, basic bash utilities, and so forth.
I haven't looked yet into RAM based file systems or how to setup my system to make this use case work well, but for now, out of the box, I cannot recommend TreeBase for databases of more than 100,000 entities.
Is there even a point now to try 6.5M? Arguably no.
However, I've come this far! No turning back now.
A 6.5M TreeBase
To recap what I am doing here: I am taking a single 6.5 million row 500MB TSV file that could easily be parsed into a SQLite or other battle hardened database and instead turning it into a monstrous 6.5 million file TreeBase backed by Git and writing it to my hard disk with no special configuration.
By the way, I forgot to mention my system specs for the record. I'm doing this on a MacBook Air running macOS Catalina on a 2.2Ghz Dual-core i7 with 8GB of 1600 Mhz DDR3 Ram with a 500GB Apple SSD using APFS. This is the last MacBook with a great keyboard, so I really hope it doesn't break.
Okay, back to the task at hand.
I need to generate the 6.5M files in a single directory. The 600k TreeBase took 6 minutes to generate so if that scales linearly 6.5M should take an hour. The first git add for 600k took 40 minutes, so that for 6.5M could take 6 hours. The first git commit for 600k took 10 minutes, so potentially 1.5 hours for 6.5M. So this little operation might take about 10 hours.
I'll stitch these operations together into a shell script and run it overnight (I'll make sure to check the batteries in my smoke detectors first).
Here's the script to run the whole routine:
time node buildStream.js
time cd ~/imdb/6m/
time git add .
time git commit -m "initial commit"
time git push
Whenever running a long script, it's smart to test it with a smaller dataset first. I successfully tested this script with the 6k file dataset. Everything worked. Everything should be all set for the final test.
(Later the next day...)
It's Alive!
It worked!!! I now have a TreeBase with over 6 million files in a single directory. Well, a few things worked, most things did not.
| category | description | result |
|---|---|---|
| bash | ls | X |
| sublime | Start sublime in the TreeBase folder | X |
| sublime | scroll and click around files in the treebase folder and see how responsive it feels. | X |
| sublime | find all movies with the query "titleType movie" | X |
| sublime | find all comedy movies with the regex query "genres ._Comedy._" | X |
| finder | open and browse | X |
| git | init git for the treebase | nearInstant |
| git | first git add for the treebase | 12 hours |
| git | first git commit | 5 hours |
| sublime | edit some file | X |
| git | git status when there is a change | X |
| git | add the change above | X |
| git | commit the change | X |
| github | push the treebase to github | X |
| treebase | how long will it take to start treebase | X |
| treebase | how long will it take to scan the base for errors. | X |
💣 There was a slight hiccup in my script where somehow v8 again ran out of memory. But only after creating 6,340,000 files, which is good enough for my purposes.
💣 But boy was this slow! The creation of the 6M+ files took 3 hours and 20 minutes.
💣 The first git add . took a whopping 12 hours!
💣 The first git commit took 5 hours!
💣 A few times when I checked on the machine it was running hot. Not sure if from CPU or Disk or a combination.
💣 I eventually quit git push. It quickly completed Counting objects: 6350437, done. but then nothing happened except lots of CPU usage for hours.
Although most programs failed, I was at least able to successfully create this monstrosity and navigate the folder.
The experiment has completed. I took a perfectly usable 6.5M row TSV file and transformed it into a beast that brings some of the most well-known programs out there to their knees.
💣 NOTE: I do not recommend trying this at home. My laptop became lava hot at points. Who knows what wear and tear I added to my hard disk.
What have I learned?
So that is the end of the experiment. Can you build a Git-backed TreeBase with 6.5M files in a single folder? Yes. Should you? No. Most of your tools won't work or will be far too slow. There's infrastructure and design work to be done.
I was actually pleasantly surprised by the results of this early test. I was confident it was going to fail but I wasn't sure exactly how it would fail and at what scale. Now I have a better idea of that. TreeBase currently sucks at the 100k level.
I also now know that the hardware for this type of system feels ready and it's just parts of some software systems that need to be adapted to handle folders with lots of files. I think those software improvements across the stack will be made and this dumb thing could indeed scale.
What's Next?
Now, my focus at the moment is not on big TreeBases. My focus is on making the experience of working with little TreeBases great. I want to help get things like Language Server Protocol going for TreeBases and a Content Management System backed by TreeBase.
But I now can envision how, once the tiny TreeBase experience is nailed, you should be able to use this for bigger tasks. The infrastructure is there to make it feasible with just a few adjustments. There are some config tweaks that can be made, more in-memory approaches, and some straightforward algorithmic additions to make to a few pieces of software. I also have had some fun conversations where people have suggested good sharding strategies that may prove useful without changing the simplicity of the system.
That being said, it would be fun to do this experiment again but this time try and make it work. Once that's a success, it would be fun to try and scale it another 100x, and try to build a TreeBase for something like the 180M paper Semantic Scholar dataset.
Why Oh Why TreeBase?
Okay, you might be wondering what is the point of this system? Specifically, why use the file system and why use Tree Notation?
1) The File System is Going to Be Here for a Long Long Time
1) About 30m programmers use approximately 100 to 500 general purpose programming languages. All of these actively used general purpose languages have battle tested APIs for interacting with file systems. They don't all have interfaces to every database program. Any programmer, no matter what language they use, without having to learn a new protocol, language, or package, could write code to interact with a TreeBase using knowledge they already have. Almost every programmer uses Git now as well, so they'd be familiar with how TreeBase change control works.
2) Over one billion more casual users are familiar with using their operating system tools for interacting with Files (like Explorer and Finder). Wouldn't it be cool if they could use tools they already know to interact with structured data?
Wouldn't it be cool if we could combine sophisticated type checking, querying, and analytical capabilities of databases with the simplicity of files? Programmers can easily build GUIs on top of TreeBase that have any and all of the functionality of traditional database-backed programs but have the additional advantage of an extremely well-known access vector to their information.
People have been predicting the death of files but these predictions are wrong. Even Apple recently backtracked and added a Files interface to iOS. Files and folders aren't going anywhere. It's a very simple and useful design pattern that works in the analog and digital realm. Files have been around for at least 4,500 years and my guess is will be around for another 5,000 years, if the earth doesn't blow up. Instead of dying, on the contrary file systems will keep getting better and better.
2) Tree Notation is All You Need to Create Meaningful Semantic Content
People have recognized the value of semantic, strongly typed content for a long time. Databases have been strongly typed since the beginning of databases. Strongly typed programming languages have dominated the software world since the beginning of software.
People have been attempting to build a system for collaborative semantic content for decades. XML, RDF, OWL2, JSON-LD, Schema.org—these are all great projects. I just think they can be simplified and I think one strong refinement is Tree Notation.
I imagine a world where you can effortlessly pass TreeBases around and combine them in interesting ways. As a kid I used to collect baseball cards. I think it would be cool if you could just as easily pass around "cards" like a "TreeBase of all the World's Medicines" or a "TreeBase of all the world's academic papers" or a "TreeBase of all the world's chemical compounds" and because I know how to work with one TreeBase I could get value out of any of these TreeBases. Unlike books or weakly typed content like Wikipedia, TreeBases are computable. They are like specialized little brains that you can build smart things out of.
So I think this could be pretty cool. As dumb as it is.
I would love to hear your thoughts.
January 23, 2020 — People make biased claims all the time. A decent response used to be "citation needed". But we should demand more. Anytime someone makes a claim that seems biased, call them out with: Dataset needed.
Whether it's an academic paper, news article, blog post, tweet, comment or ad, linking to analyses is not enough. If someone stops at that, demand a link to a clean dataset supporting the author's position. If they can't deliver, they should retract.
Of course, most sources don't currently publish their datasets. You cannot trust claims from any person or organization without an easily accessible dataset. In fact, it's probably safe to assume when someone shares a conclusion without the accompanying dataset that they are distorting reality for their own benefit.
Be a broken record: "Dataset needed. Dataset needed. Dataset needed."
Encourage authors to link to and/or publish their datasets. You can't say dataset needed enough. It is valuable, constructive feedback.

You can't say it enough[1].
Authors: support your arguments with open data
Link to the dataset. If you want to include a conclusion, provide a deep link to the relevant query of the dataset. Do not repeat conclusions that don't have an accompanying dataset. If people can't verify what you say, don't say it.
Software teams: make it easy for users to share deep links to queries over public datasets
Many teams are creating tools that make it easy to deep link to queries over open datasets, such as Observable, Our World in Data, Google Big Query, Wolfram Data Repository, Tableau Public, IDL, Jupyter, Awesome Public Datasets, USAFacts, Google Dataset Search, and many more.
Students: Learn to build and publish datasets
I remember being a high school student and getting graded on our dataset notebooks we made in the lab. Writing clean data should be widely taught in school, and there's an army of potential workers who could help us create more public, deep-linkable datasets.
Related Posts
January 20, 2020 — In this post I briefly describe eleven threads in languages and programming. Then I try to connect them together to make some predictions about the future of knowledge encoding.
This might be hard to follow unless you have experience working with types, whether that be types in programming languages, or types in databases, or types in Excel. Actually, this may be hard to follow regardless of your experience. I'm not sure I follow it. Maybe just stay for the links. Skimming is encouraged.
First, from the Land of Character Sets
Humans invented characters roughly 5,000 years ago.
Binary notation was invented roughly 350 years ago.
The first widely adopted system for using binary notation to represent characters was ASCII, which was created only 60 years ago. ASCII encodes little more than the characters used by English.
In 1992 UTF-8 was designed which went on to become the first widespread system that encodes all the characters for all the world's languages.
For about 99.6% of recorded history we did not have a globally used system to encode all human characters into a single system. Now we do.
Meanwhile, in the Land of Standards Organization
Scientific standards are the original type schemas. Until recently, Standards Organizations dominated the creation of standards.
You might be familiar with terms like meter, gram, amp, and so forth. These are well defined units of measure that were pinned down in the International System of Units, which was first published in 1960.
The International Organization for Standardization (ISO) began around 100 years ago and is the organization behind a number of popular standards from currency codes to date and time formats.
For 98% of recorded history we did not have global standards. Now we do.
Meanwhile, in Math Land
My grasp of the history of mathematics isn't strong enough to speak confidently to trends in the field, but I do want to mention that in the past century there has been a lot of important research into type theories.
In the past 100 years type theories have taken their place as part of the foundation of mathematics.
For 98% of recorded history we did not have strong theories of type systems. Now we do.
Meanwhile, in Programming Language Land
The research into mathematical type and set theories in the 1900's led directly into the creation of useful new programming languages and programming language features.
From the typed lambda calculus in the 1940's to the static type system in languages like C to the ongoing experiments of Haskell or the rapid growth of the TypeScript ecosystem, the research into types has led to hundreds of software inventions.
In the late 1990's and 2000's, a slew of programming languages that underutilized innovations from type theory in the name of easier prototyping, like Python and Ruby and Javascript, became very popular. For a while this annoyed programmers who understood the benefits of type systems. But now they too are benefiting, as there is a bigger demand for richer type systems now due to the increase in the number of programmers.
95%+ of the most popular programming languages use increasingly smarter type systems.
Meanwhile, in API Land
Before the Internet became widespread, the job of most programmers was to write software that interacted only with other software on the local machine. That other software was generally under their control or well documented.
In the late 1990's and 2000's, a big new market arose for programmers to write software that could interact over the Internet with software on other machines that they had no control of or knowledge about.
At first there was not a good standard language to use that was agreed upon by many people. 1996's XML a variant of SGML from 1986, was the first attempt to get some traction for this job. But XML and the dialects of XML for APIs like SOAP (1998) and WSDL (2000) were not easy to use. Then Douglas Crockford created a new language called JSON in 2001. JSON made web API programming easier and helped create a huge wave of web API businesses. For me this was great. In the beginning of my programming career I got jobs working on these new JSON APIs.
The main advantage that JSON had over XML was simple, well defined types. It had just a few primitive types—like numbers, booleans and strings—and a couple of complex types—lists and dicts. It was a very useful collection of structures that were important across all programming languages, put together in a simple and concise way. It took very little time to learn the entire thing. In contrast, XML was "extensible" and defined no types, leading to many massive dialects defined by committee.
For 99.8% of recorded history we did not have a global network conducting automated business transactions with a typed language. Now we do.
Meanwhile, in SQL Land
When talking about types and data one must pay homage to SQL databases, which store most of the world's structured data and perform the transactions that our businesses depend on.
SQL programmers spend a lot of time thinking about the structure of their data and defining it well in a SQL data definition language.
Types play a huge role in SQL. The dominant SQL databases such as MySQL, SQL Server, and Oracle all contain common primitives like ints, floats, and strings. Most of the main SQL databases also have more extensive type systems for things like dates and money and even geometric primitives like circles and polygons in PostgreSQL.
Critical information is stored in strongly typed SQL databases: Financial information; information about births, health and deaths; information about geography and addresses; information about inventories and purchase histories; information about experiments and chemical compounds.
98% of the world's most valuable, processed information is now stored in typed databases.
Meanwhile, in the Land of Types as Code
The standards we get from the Standards Organizations are vastly better than not having standards, but in the past they've been released as non-computable, weakly typed documents.
There are lots of projects that are now writing schemas in computable languages. The Schema.org project is working to build a common global database of rich type schemas. JSON LD aims to make the types of JSON more extensible. The DefinitelyTyped project has a rich collection of commonly used interfaces. Protocol buffers and similar are another approach at language agnostic schemas. There are attempts at languages just for types. GraphQL has a useful schema language with rich typing.
100% of standards/type schemas can now themselves be written in strongly typed documents.
Meanwhile, in Git Land
Git is a distributed version control system created in 2005.
Git can be used to store and track changes to any type of data. You could theoretically put all of the English Wikipedia in Git, then CAPITALIZE all verbs, and save that as a single patch file. Then you could post your patch to the web and say "I propose the new standard is we should CAPITALIZE all verbs. Here's what it would look like." While this is a dumb idea, it demonstrates how Git makes it much cheaper to iterate on standards. Someone can propose both a change to the standard and the global updates all in a single operation. Someone can fork and branch to their heart's content.
For 99.9% of recorded history, there was not a cheap way to experiment and evolve type schemas nor a safe way to roll them out. Now there is.
Meanwhile, in Hub Land
In the past 30 years, central code hubs have emerged. There were early ones like SourceForge but in the past ten years GitHub has become the breakout star. GitHub has around 30 million users, which is also a good estimate of the total number of programmers worldwide, meaning nearly every programmer uses git.
In addition to source code hubs, package hubs have become quite large. Some early pioneers are still going strong like 1993's CRAN but the breakout star is 2010's NPM, which has more packages than the package managers of all other languages combined.
Types are arbitrary. The utility of a type depends not only on its intrinsic utility but also on its popularity. You can create a better type system—maybe a simpler universal day/time schema—but unless it gains popularity it will be of limited value.
Code hubs allow the sharing of code, including type definitions, and can help make type definitions more popular, which also makes them more useful.
99% of programmers now use code hubs and hubs are a great place to increase adoption of types, making them even more useful.
Meanwhile, in Semantic Web Land
The current web is a collection of untyped HTML pages. So if I were to open a web page with lots of information about diseases and had a semantic question requiring some computation, I'd have to read the page myself and use my slow brain to parse the information and then figure out the answer to my semantic question.
The Semantic Web dream is that the elements on web pages would be annotated with type information so the computer could do the parsing for us and compute the answers to our semantic questions.
While the "Semantic Web" did not achieve adoption like the untyped web, that dream remains very relevant and is ceaselessly worked upon. In a sense Wolfram Alpha embodies an early version of the type of UX that was envisioned for the Semantic Web. The typed data in Wolfram Alpha comes from a nicely curated collection.
While lots of strongly typed proprietary databases exist on the web for various domains from movies to startups and while Wikipedia is arguable undergoing gradual typing, the open web still remains largely untyped and we don't have a universally accessible interface yet to the world's typed information.
99% of the web is untyped while 99% of the world's typed information is silo-ed and proprietary.
Meanwhile, in Deep Learning Land
Deep Learning is creeping in everywhere. In the past decade it has come to be the dominant strategy for NLP. In the past two years, a new general learning strategy has become feasible where models learn some intrinsic structure of language and can use this knowledge to perform many different language tasks.
One of those tasks could be to rewrite untyped data in a typed language.
AI may soon be able to write a strongly typed semantic web from the weakly typed web.
Tying All These Threads Together
I see a global pattern here that I call the "Type the World" trend. Here are some future predictions from these past trends.
- We will always have creative, ambiguous, untyped human languages where new ideas can evolve freely
- In the future great new ideas from the untyped realm will be adopted faster by the typed realm
- Nearly all transactions in business and government will be in typed languages
- Someone will invent a wildly popular new domain specific language(s) for type definitions
- All the popular standards will be ones written in these new and improved TypeDSLs
- Git—or git like systems—will be used to store both the TypeDSLs and the typed data
- TypeHubs will arise hosting these widely used type schemas
- Programmers will get their types from TypeHubs regardless of which programming language they use
- Deep learning agents will be used to rewrite the web's untyped data into typed data
- Deep learning agents will be used to improve type schemas
- Human editors will review and sign off on the typing work of the deep learning agents
- Silo-ed domain specific standards will merge into one or a handful of global monolithic type systems
The result of this will be a future where all business, from finance to shopping to healthcare to law, is conducted in a rich, open type system, and untyped language work is relegated to research, entertainment and leisure.
While I didn't dive into the benefits of what Type the World will bring, and instead merely pointed out some trends that I think indicate it is happening, I do indeed believe it will be a fantastic thing. Maybe I'll give my take on why Type the World is a great thing in a future post.
January 16, 2020 — I often rail against narratives. Stories always oversimplify things, have hindsight bias, and often mislead.
I spend a lot of time inventing tools for making data derived thinking as effortless as narrative thinking (so far, mostly in vain).
And yet, as much as I rail on stories, I have to admit: stories work.
I read an article that put it more succinctly:
Why storytelling? Simple: nothing else works.
I would agree with that. Despite the fact that 90% of stories are lies, they motivate people better than anything else.
Stories make people feel something. They get people going.
What is the math here?
On a population level, it seems people who follow stories have a survival advantage.
On a local level, it seems people who can weave stories have an even greater survival advantage.
Why?
Perhaps it's due to risk taking. Perhaps the people who follow stories take more risks, on average, than people who don't, and even though many of those don't pan out some of those risks do pay off and the average is worth it.
Perhaps it's due to productivity. Perhaps people who are storiers spend less time analyzing and more time doing. The act of doing generates experience (data), so often the best way to be data-driven isn't to analyze more it's to go out there and do more to collect more data. As they say in machine learning, data trumps algorithms.
Perhaps it's due to focus. If you just responded to your senses all the time the world is a shimmering place, and perhaps narratives are necessary to get anything done at all.
Perhaps it's due to memory. A story like 'The Boy who Cried Wolf' is shorter and more memorable than 'Table of Results from a Randomized Experiment on the Effect of False Alarms on Subsequent Human Behavior'.
Perhaps it's healthier. Our brains are not much more advanced than the chimp. Uncertainty can create stress and anxiety. Perhaps the confidence that comes from belief in a story leads to less stress and anxiety leading to better health, which outweighs any downsides from decisions that go against the data.
Perhaps it's a cooperation advantage. If everyone is analyzing their individual decisions all the time, perhaps that comes at the cost of cooperation. Storiers go along with the group story, and so over time their populations get more done together. Maybe the opposite of stories isn't truth, it's anarchy.
Perhaps it's just more fun. Maybe stories are suboptimal for decision making and lead us astray all the time, and yet are still a survival advantage simply because it's a more enjoyable way to live. Even when you screw up royally, it can make a good story. As the saying goes, "don't take life too seriously, you'll never make it out alive."
Despite my problems with narratives and my quest for something better, it seems quite possible to me that at the end of the day it may turn out that there is nothing better, and it's best to make peace with stories, despite their flaws. And regardless of the future, I can't argue with the value of stories today for motivation and enjoyment. Nothing else works.
Related Posts
January 3, 2020 — Speling errors and errors grammar are nearly extinct in published content. Logic errors, however, are prolific.
By logic error I mean one the following errors: a statement without a backing dataset and/or definitions, a statement with data but a bad reduction(s), or a statement with backing data but lacking integrated context. I will provide examples of these errors later.
The hard sciences like physics, chemistry and most branches of engineering have low tolerance for logic errors. But outside of those domains logic errors are everywhere.
Fields like medicine, law, media, policy, the social sciences, and many more are teeming with logic errors, which are far more consequential than spelling or grammar errors. If a drug company misspells the word dockter in some marketing material the effect will be trivial. But if that material contains logic errors those often influence terrible medical decisions that lead to many deaths and wasted resources.
If Logic Errors Were Spelling Errors
You would be skeptical of National Geographic if their homepage looked like this:
We generally expect zero spelling errors when reading any published material.
Spell checking is now an effortless technology and everyone uses it. Published books, periodicals, websites, tweets, advertisements, product labels: we are accustomed to reading content at least 99% free of spelling and grammar errors. But there's no equivalent to a spell checker for logic errors and when you look for them you see them everywhere.
The Pandemic: An Experiment
Logic errors are so pervasive that I came up with a hypothesis today and put it to the test. My hypothesis was this: 100% of "reputable" publications will have at least one logic error on their front page.
Method
I wrote down 10 reputable sources off the top of my head: the WSJ, The New England Journal of Medicine, Nature, The Economist, The New Yorker, Al Jazeera, Harvard Business Review, Google News: Science, the FDA, and the NIH.
For each source, I went to their website and took a single screenshot of their homepage, above the fold, and skimmed their top stories for logic errors.
Results
In the screenshots above, you can see that 10/10 of these publications had logic errors front and center.
Breaking Down These Errors
Logic errors in English fall into common categories. My working definition provides three: a lack of dataset and/or definitions, a bad reduction, or a lack of integrated context. There could be more, this experiment is just a starting point where I'm naming some of the common patterns I see.
The top article in the WSJ begins with "Tensions Rise in the Middle East". There are at least 2 logic errors here. First is the Lack of Dataset error. Simply put: you need a dataset to make a statement like that. There is no longitudinal dataset in that article on tensions in the Middle East. There is also a Lack of Definitions. Sometimes you can not yet have a dataset but at least define what a dataset would be that could back your assertions. In this case we have neither a dataset nor a definition of what some sort of "Tensions" dataset would look like.
In the New England Journal of Medicine, the lead figure shows "excessive alcohol consumption is associated with atrial fibrillation" between 2 groups. One group had 0 drinks over a 6 month period and the other group had over 250 drinks (10+ per week). There was a small impact on atrial fibrillation. This is a classic Lack of Integrated Context logic error. If you were running a lightbulb factory and found soaking lightbulbs in alcohol made them last longer, that might be an important observation. But humans are not as disposable, and health studies must always include integrated context to explore whether there is something of significance. Having one group make any sort of similar drastic lifestyle change will likely have some impact on any measurement. A good rule of thumb is anything you read that includes p-values to explain why it is significant is not significant.
In Nature we see the line "world's growing water shortage". This is a Bad Reduction, another very common logic error. While certain areas have a water shortage, other areas have a surplus. Any time you see a broad diverse things grouped into one term, or "averages", or "medians", it's usually a logic error. You always need access to the data, and you'll often see a more complex distribution that would prevent broad true statements like those.
In The Economist the lead story talks about an action that "will have profound consequences for the region". Again we have the Lack of Definitions error. We also have a Forecast without a Dataset error. There's nothing wrong with making a forecast--creating a hypothetical dataset of observations about the future--but one needs to actually create and publish that dataset and not just a vague unfalsifiable statement.
The New Yorker lead paragraph claims an event "was the most provocative U.S. act since...". I'll save you the suspense: the article did not include a thorough dataset of such historical acts with a defined measurement of provocative. Another Lack of Dataset error.
In Al Jazeera we see "Iran is transformed" and also a Bad Reduction, Lack of Dataset and Lack of Definition errors.
Harvard Business Review has a lead article about the Post-Holiday funk. In that article the phrase "research...suggests" is often a dead giveaway for a Hidden Data error, where the data is behind a paywall and even then often inscrutable. Anytime someone says "studies/researchers/experts" it is a logic error. We all know the earth revolves around the sun because we can all see the data for ourselves. Don't trust any data you don't have access to.
Google News has a link to an interesting article on the invention of a new type of color changing fiber, but the article goes beyond the matter at hand to make the claim: "What Exactly Makes One Knot Better Than Another Has Not Been Well-Understood – Until Now". There is a Lack of Dataset error for meta claims about the knowledge of knot models.
The FDA's lead article is on the Flu and begins with the words "Most viral respiratory infections...", then proceeds for many paragraphs with zero datasets. There is an overall huge Lack of Datasets in that article. There's also a Lack of Monitoring. Manufacturing facilities are a controlled, static environment. In uncontrolled, heterogeneous environments like human health, things are always changing, and to make ongoing claims without having infrastructure in place to monitor and adjust to changing data is a logic error.
The NIH has an article on how increased exercise may be linked to reduced cancer risk. This is actually an informative article with 42 links to many studies with lots of datasets, however the huge logic error here is Lack of Integration. It is very commendable to do the grunt work and gather the data to make a case, but simply linking to static PDFs is not enough—they must be integrated. Not only does that make it much more useful, but if you've never tried to integrate them, you have no idea if the pieces actually will fit together to support your claims.
While my experiment didn't touch books or essays, I'm quite confident the hypothesis will hold in those realms as well. If I flipped through some "reputable" books or essayist collections I'm 99.9% confident you'd see the same classes of errors. This site is no exception.
The Problem is Language Tools
I don't think anyone's to blame for the proliferation of logic errors. I think it's still relatively recent that we've harnessed the power of data in specialized domains, and no one has yet invented ways to easily and fluently incorporate true data into our human languages.
Human languages have absorbed a number of sublanguages over thousands of years that have made it easier to communicate with ease in a more precise way. The base 10 number system (0,1,2,3,4,5,6,7,8,9) is one example that made it a lot easier to utilize arithmetic.
Taking Inspiration from Programming Language Design
Domains with low tolerance for logic errors, like aeronautical engineering or computer chip design, are heavily reliant on programming languages. I think it's worthwhile to explore the world of programming language design for ideas that might inspire improvements to our everyday human languages.
Some quick numbers for people not familiar with the world of programming languages. Around 10,000 computer languages have been released in history (most of them in the past 70 years). About 50-100 of those have more than a million users worldwide and the names of some of them may be familiar to even non-programmers such as Java, Javascript, Python, HTML or Excel.
Not all programming languages are created equal. The designers of a language end up making thousands of decisions about how their particular language works. While English has evolved with little guidance over millennia, programming languages are often designed consciously by small groups and can evolve much faster.
Often the designers change a language to make it easier to do something good or harder to do something bad.
Sometimes what is good and bad is up to the whims of the designer. Imagine I was an overly optimistic person and decided that English was too boring or pessimistic. I may invent a language without periods, where all sentences must end with an exclamation point! I'll call it Relish!
Most of the time though, as data and experience accumulates, a rough consensus emerges about what is good and bad in language design (though this too seesaws).
Typed Checked Languages
One of the patterns that has emerged as generally a good thing over the decades to many languages is what's called "type checking". When you are programming you often create buckets that can hold values. For example, if you were programming a function that regulated how much power a jet engine should supply, you might take into account the reading from a wind speed sensor and so create a bucket named "windSpeed".
Some languages are designed to enforce stricter logic checking of your buckets to help catch mistakes. Others will try to make your program work as written. For example, if later in your jet engine program you mistakenly assigned the indoor air temperature to the "windSpeed" bucket, the parsers of some languages would alert you while you are writing the program, while with some other languages you'd discover your error in the air. The former style of languages generally do this by having "type checking".
Type Checking of programming languages is somewhat similar to Grammar Checking of English, though it can be a lot more extensive. If you make a change in one part of the program in a typed language, the type checker can recheck the entire program to make sure everything still makes sense. This sort of thing would be very useful in a logic checked language. If your underlying dataset changes and conclusions anywhere are suddenly invalid, it would be helpful to have the checker alert you.
Perhaps lessons learned from programing language design, like Type Checking, could be useful for building the missing logic checker for English.
A Blue Squiggly to Highlight Logic Errors
Perhaps what we need is a new color of squiggly:
✅ Spell Checkers: red squiggly
✅ Grammar Checkers: green squiggly
❌ Logic Checkers: blue squiggly
If we had a logic checker that highlighted logic errors we would eventually see a drastic reduction in logic errors.
If we had a checker for logic errors appear today our screens would be full of blue. For example, click the button below to highlight just some of the logic errors on this page alone.
How Do We Reduce Logic Errors?
If someone created a working logic checker today and applied it to all of our top publications, blue squigglies would be everywhere.
It is very expensive and time consuming to build datasets and make data driven statements without logic errors, so am I saying until we can publish content free of logic errors we should stop publishing most of our content? YES! If you don't have anything true to say, perhaps it's best not to say anything at all. At the very least, I wish all the publications above had disclaimers about how laden with logic errors their stories are.
Of course I don't believe either of those are likely to happen. I think we are stuck with logic errors until people have invented great new things so that it becomes a lot easier to publish material without logic errors. I hope we somehow create a logic checked language.
I still don't know what that looks like, exactly. I spend half my work time attempting to create such new languages and tools and the other half searching the world to see if someone else has already solved it. I feel like I'm making decent progress on both fronts but I still have no idea whether we are months or decades away from a solution.
While I don't know what the solution will be, I would not be surprised if the following patterns play a big role in moving us to a world where logic errors are extinct:
1. Radical increases in collaborative data projects It is very easy for a person or small group to crank out content laden with logic errors. It takes small armies of people making steady contributions over a long time period to build the big datasets that can power content free of logic errors.
2. Widespread improvements in data usability. Lots of people and organizations have moved in the past decade to make more of their data open. However, it generally takes hours to become fluent with one dataset, and there are millions of them out there. Imagine if it took you hours to ramp on a single English word. That's the state of data usability right now. We need widespread improvements here to make integrated contexts easier.
3. Stop subsidizing content laden with logic errors. We grant monopolies on information and so there's even more incentive to create stories laden with logic errors—because there are more ways to lie than to tell the truth. We should revisit intellectual monopoly laws.
4. Novel innovations in language. Throughout history novel new sublanguages have enhanced our cognitive abilities. Things like geometry, Hindu-Arabic numerals, calculus, binary notation, etc. I hope some innovators will create very novel logic sublanguages that make it much easier to communicate with data and reduce logic errors.
Have you invented a logic checked language, or are working on one? If so, please get in touch.
Related Posts
The Attempt to Capture Truth
August 19, 2019 — Back in the 2000's Nassim Taleb's books set me on a new path in search of truth. One truth I became convinced of is that most stories are false due to oversimplification. I largely stopped writing over the years because I didn't want to contribute more false stories, and instead I've been searching for and building new forms of communication and ways of representing data that hopefully can get us closer to truth.
I've tried my best to make my writings encode "real" and "true" information, but it's impossible to overcome the limitations of language. The longer any work of English writing is, the more inaccuracies it contains. This post itself will probably be more than 50% false.
But most people aren't aware of the problem.
Fake news is a great idea.
Then came DT and "fake news". One nice thing I can say about DT is that "fake news" is a great idea.
If your ideas are any good, you'll have to ram them down people's throats.Howard H. Aiken
..in science the credit goes to the man who convinces the world, not to the man to whom the idea first occurs.Francis Darwin
DT has done a great job at spreading this idea. Hundreds of millions of people, at least, now are at least vaguely familiar that there's a serious problem, even if people can't describe precisely what that is. Some people mistakenly believe "their news" is real and their opponents' news is fake. It's all fake news.
What's the underlying problem?
English is a fantastic story telling language that has been very effective at sharing stories, coordinating commerce and motivating armies, but English evolved in a simpler time with simpler technologies and far less understanding about how the world really works.
English oversimplifies the world which makes it easy to communicate something to be done. English is a modern day cave painting language. Nothing motivates a person better than a good story, and that motivation was essential to get us out of the cave. It didn't matter so much in which direction people went, as long as they went in some direction together.
But we are now out of the cave, and it is not enough to communicate what is to be done. We have many more options now and it's important that we have langauges that can better decide what is the best thing to do.
What will a language that supports Real News look like?
Real News is starting to emerge in a few places. The WSJ has long been on the forefront but newer things like Observable are also popping up.
I don't know exactly what a language for truth will look like but I imagine it will have some of these properties:
- It will be a language that is hard to lie with
- It will contain more numerics and be more data driven
- It will be interactive, with assumptions made clear and adjustable by the reader
- It will be blameable, with the source and history of every line and character auditable
- It will be linked and auditable, with the ability to "go to definitions"
- It will discourage obfuscation, and will make it easy to compare 2 representations and choose the simpler one
- It will be more visual, expanding beyond character alphabets and embracing more charts and visualizations
- It will be more Random Access, like bullet points
English and Sapir–Whorf
I would say until we move away from English and other story-telling languages to encodings that are better for truth telling, our thinking will also be limited.
A language that doesn’t affect the way you think about programming, is not worth knowing.Alan Perlis
New languages designed for truth telling might not just be useful in our everyday lives, they could very much change the way we think.
Finally
Again, to channel Taleb, I'm not saying English is bad. By all means, enjoy the stories. But just remember they are stories. If you are reading English, know that you are not reading Real News.
Related Posts
July 18, 2019 — In 2013 I sent a brief email to 25 programmers whose programs I admired.
"Would you be willing to share the # of hours you have spent practicing programming? Back of the envelope numbers are fine!"
Some emails bounced back.
Some went unanswered.
But five coders wrote back.
This turned out to be a tiny study, but given the great code these folks have written, I think the results are interesting--and a testament to practice!
| Name | GitHub | Hours | YearOfEstimate | BornIn |
|---|---|---|---|---|
| Donald Knuth | 56000 | 2013 | 1938 | |
| Rob Pike | robpike | 30000 | 2013 | 1956 |
| Peter Norvig | norvig | 30000 | 2013 | 1956 |
| Stephen Wolfram | 50000 | 2013 | 1959 | |
| Lars Bak | larsbak | 30000 | 2013 | 1965 |
My Conclusion
No evidence has been found that the 10,000 hour strategy is flawed. :)
Thank You
I hope these data points can encourage other aspiring programmers as much as they encouraged me.
I am eternally grateful to the programmers who responded.
Back then I was 5 years into my programming career, I had passed 10,000 hours of practice, and was starting to worry that the "10,000 hour strategy" I had been following and telling other aspiring programmers to follow may have been in vain, because I was still a pretty bad programmer (many would argue that today, 6 years later, I'm not much better, but now I can say that's just because I only have 29,000 hours of practice).
These busy coders answered my cold emails with not just a number but many encouraging words and thoughts.
One of my favorite responses was from Peter Norvig, who sent me a Python program computing his estimate:
# sum(years * (hours/week)) * (weeks/year)
(4 * 10 # college
+ 2 * 30 # first job
+ 5 * 20 # grad school
+ 6 * 20 # faculty, research faculty
+ 6 * 25 # programming jobs
+ 15 * 10 # management jobs
) * 48
Thank you everyone!
Notes
I promised I would compile the responses and publish the results to the public domain.
But, while waiting for more responses to trickle in, I slowly forgot about this project.
Until this morning (7/18/2019), when I stumbled upon one of those old emails.
Sorry for the delay!
Related Posts

Recently some naive fool proposed removing the “2's” from our beloved Trinary Notation.
Binary Notation is almost too idiotic an idea to take seriously, but because this is not the first time this issue has been raised in the past 20 years, and lest some more poor saps waste their time pondering the problem for themselves, I feel it my duty, as someone who knows nearly everything there is to know about notations, as demonstrated by my long CV, to provide a few dogmas that unequivocally prove how foolish an idea this is and that all work on it is a huge waste of time.
First, an observation. Trinary notation has been around for over 60 years, and has been learned and studied by the most eminent scholars in our field. Clearly, if there were problems with it, these eminent persons would have fixed them by now. If the broader public hasn’t adopted Trinary notation widely yet, it is not a problem with Trinary, but rather it is the feeble-minded public who is to blame.
Second, an example. Imagine, dear reader, you would like to add the number 2 to itself. In Trinary Notation such a thing could not be simpler: “2 + 2”! Now, in this atrocious Binary format, to do the same thing you’d have to write “10 + 10”. My goodness, how hard to read! Does that equal 20 or 4? Who knows?! Cleary “2 + 2” is better! My dear reader, I beg you to not waste your time thinking of other examples, that one alone should be enough.
Third, I will agree with the proponents of Binary Notation when they claim that it is very similar to Trinary Notation, and indeed, no one has yet found an example of something you can do in Trinary Notation that you cannot do in Binary Notation, but let me tell you dear reader, that is simply because Binary Notation is just Trinary Notation, except reinvented poorly! As the “2 + 2” example shows, Trinary is better, and exploring other examples and problems using Binary Notation instead is a waste of your time.
Fourth, the proponents of Binary Notation think that in the future, there might be some types of magical machines that can do things with Binary Notation that might be impractical or more expensive to do with Trinary. How laughable, to think their could be new machines that the Trinary founding fathers never envisioned!
Fifth, and my final point, if the idiot creator of Binary Notation struggles with “2's”, that’s just because he doesn’t get Trinary Notation. Once you get Trinary Notation, dear reader, you don’t even see the “2's” anymore. But it’s still very important that they be there.)
Originally posted on Medium.
Yet another method for counting complexity.
by Breck Yunits
Introduction
...make the irreducible basic elements as simple and as few as possible without having to surrender the adequate representation of a single datum of experience.On the Method of Theoretical Physics by Albert Einstein
The above quote is commonly paraphrased as "Make things as simple as possible, but not simpler."
This statement presents a hard problem. How do we know when we've made things as simple as possible?
How do you count complexity?
One 1999 survey of complexity measures found 48 systems in use[1]. Despite the abundance of proposed systems, some of which have proved useful in isolated domains, no general measurement system has emerged as a defacto standard[2].
In this paper I add to the pile, and propose using Particle Syntax as a tool for counting complexity.
Overview
The method introduced here, named Particle Complexity (PC), can be used to measure the complexity of an entity X. It operates as follows.
- It is assumed that all ideas are graphs that can be sliced into tree structures.
- Given the assumption that all structures can be represented as trees, we can then use Particle Syntax, a simple encoding of tree structures, to encode the components of
X, in a programP, parseable by a set of Parsers,P0. - We can then describe that set
P0in a recursive series (P1,P2, ...). - We can then stop at a desired level of abstraction (to get Relative Complexity), or continue until we reach irreducible trees (to get Total Complexity).
- We can use simple arithmetic to count the atomic components of our program and parsers and get complexity measurements for a system.
Simple Example #1
Which concept is more complex, a boolean digit (0 or 1) or a base-10 digit (between 0 and 9)?
Let's imagine a machine that takes as input one character and returns true if that input is defined in a program written for that machine.
Let's encode both concepts using one Particles language (not defined here).
boolean
0
1
digit
0
1
2
3
4
5
6
7
8
9
Comparing the count of nodes, we get two nodes for the "boolean" and ten nodes for the "digit".
Hence, by this simple PC measure we can say that a digit is more complex than a boolean.
Simple Example #2
Next, let's imagine a similar string matching program that returns true on "pat,pit,pin,bat,bit,bin,fat,fit,fin".
In this example, we use two different machines that implement two different languages.
The programming language for MachineA can accept only one letter per node.
The language for MachineB can accept multiple characters per node and will test its input against each character.
programA
p
a
t
i
n
b
a
t
i
n
f
a
t
i
n
programB
pbf
ai
tn
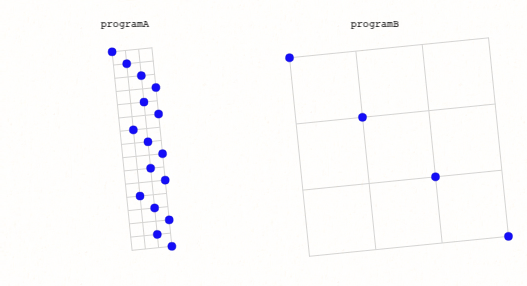
A visualization of the nodes of the two programs above.
Both programs are equivalent in that they both will return the same thing for the same input.
ProgramA requires fifteen nodes while programB requires three nodes.
Hence, the programB is less complex by this measure, given machineA and machineB (I will explain later what I mean by "given machineA and machineB").
Atomic Components of Complexity
A visualization of the countable atomic units in PC.
PC has more atomic units to count beyond nodes.
In PC countable atomic units of complexity include:
- Particles (files/2D planes/documents)
- Atoms (words)
- Subparticles (indented particles)
- and references (atoms that are pointers to other atoms)
Other derived measures could be devised as well, but in this paper we look at only the atomic units fully necessary to describe an entity.
Relative vs Total Complexity
In the example above, programB was less complex than programA "given machineA and machineB".
However, if we were measuring Total Complexity of programA and programB, we might find that programA is less complex, as the complexity of the tree representation of machineA might be less complex than the complexity of the tree representation of machineB.
Total Complexity of an entity aggregates the complexity of the tree representation of the entity along with the tree representations of all its dependencies.
Another trivial example might be, given a computer that can execute both C code and Python code, and a task to sum some numbers from a CSV file, a program in Python would be less complex.
But the Total Complexity of the Python program might be greater than that of the C program, when dependencies are measured.
Why Particles?
PC is one of many systems that measure the "difficulty of description"[3]. This means PC doesn't measure complexity directly, rather the description of the entity is measured.
Particles is used because it can easily describe micro and macro concepts, and a user can zoom between macro and micro scales as easily as moving within scales.
Basic primitives like the bit, the concept of a word, or an AND gate have a Particles representation.
Macro objects, like the Linux Kernel, could also be described using just Particles.
Both the description and the parsers the description uses are represented by the same basic minimal structures allowing the whole system to be counted and analyzed.
Particles is minimal and unambiguous.
Descriptions written in Particles can expand gracefully to handle new ideas.
Other descriptions become noisier or repetitive over time, whereas Particles is a noiseless encoding and the signal in the information remains strong over time.
Particles is a universal notation that can describe items in any domain, from computer science and mathematics to medicine and the law.
PC thus could enable cross-domain complexity comparisons.
In a sense, Particles can be thought of as a notation for building a strongly-typed noiseless encyclopedia, and then the complexity of items in that encylopedia can then be measured and compared.
Furthermore, items encoded in Particles can be thought of and visualized as existing in 3-Dimensions.
This is far-off speculation, but perhaps there exists a correlation between the PC measurements of a topic, and the number of neurons and synapses dedicated to that topic in the brain of a topic expert, out of the total supply of their 10e11 neurons and 10e15 synapses.
Big Complexity
How complex is the U.S. tax code?
How complex is the Linux Kernel?
How complex is a comprehensive description of the human brain?
How complex is a comprehensive blueprint of the new iPhone?
At the moment no total complexity descriptive project so ambitious has been attempted in Particles.
It is an open question as to whether or not such an accomplishment is even possible.
For example, a back of the envelope estimate of how many nodes might be in the total Particles description of the Linux Kernel might be a 10e6 or perhaps as many as 10e12.
One thing is certain: assuming Particles does provide the simplest notation to describe entities and thus measure their complexity (a big assumption), that does not change the fact that the total complexity of entities in our modern world is large and ever increasing.
Growth of Complexity
The Total Complexity of the world increases monotonically over time in terms of raw atomic units like tree, node and edge counts.
However, new higher level trees are also constantly introduced, reducing Relative complexity in many areas at the same time that absolute complexity generally increases.
Relative Complexity measurements of concepts ebbs and flows in sinusoidal waves, while the underlying absolute complexity steadily increases.
Conclusion and Future Work
To an evergrowing number of systems for measuring I add one more: Particles Are Complexity.
The benefit of this system is that it is simple, practical, universal, and scale free.
Future projects might look at creating Particles descriptions of large, complex systems and visualizing and summarizing the results.
Bibliography
[1] Edmonds, B. (1999). Syntactic Measures of Complexity. Doctoral Thesis, University of Manchester, Manchester, UK.
[2] Mitchell, M., 2009. Complexity: A guided tour. Oxford University Press.
[3] Lloyd, Seth. "Measures of complexity: a nonexhaustive list." IEEE Control Systems Magazine 21.4 (2001): 7-8.
Related Posts
- Particle Chain: A New Kind of Blockchain (2024)
- ETA!: A Measure of Evolution (2024)
- ICS: A Measure of Intelligence (2024)
- PTCRI: An Equation about Syntax Potential (2024)
- ScrollSets: A New Way to Store Knowledge (2024)
- Parsers: a language for making languages (2017)
- Tree Notation: an antifragile program notation (2017)
- A New Discovery in Computer Science: 2-Dimensional Programming Languages (2017)
by Breck Yunits
I introduce the core idea of a new language for making languages.
Introduction
Creating a great programming language is a multi-step process. One step in that process is to decide on syntax and formally define a language in a parser notation such as BNF. Unfortunately, like the programming languages they describe, these parser notations are complex, brittle and error-prone.
Below I introduce the core idea of a much simpler parser notation for defining 2D Languages.
Parsers: A language for building languages
A microlang in Parsers consists of a set of Parser Definitions including a catchall Parser Definition.
A Parser Definition consists of a match rule and optionally another Parsers microlang.
Everything is encoded in the same sytnax (Particles), hence Parsers is written in Parsers.
Example
A Parsers file for an imagined microlang called Tally, with 2 Parsers {+, -} might look like this:
TallyParser
catchAllParser errorParser
parsers
errorParser
expressionParser extends TallyParser
words int+
+Parser extends expressionParser
-Parser extends expressionParser
A valid program in the Tally microlang defined by the file above:
+ 4 5
- 1 1
Conclusion and Future Work
The introduction above is minimal but shows the core idea: a new notation (Particles) can be used to define new languages in a language (Parsers) that itself is defined in Parsers on top of Particles.
We have developed and open-sourced Parsers a compiler-compiler implementing these ideas.
Future publications and/or open source releases will delve into the additional features found in the compiler-compiler.
Related Posts
- Particle Chain: A New Kind of Blockchain (2024)
- ETA!: A Measure of Evolution (2024)
- ICS: A Measure of Intelligence (2024)
- PTCRI: An Equation about Syntax Potential (2024)
- ScrollSets: A New Way to Store Knowledge (2024)
- PC: Particle Complexity (2017)
- Tree Notation: an antifragile program notation (2017)
- A New Discovery in Computer Science: 2-Dimensional Programming Languages (2017)
June 23, 2017 — I just pushed a project I've been working on called Ohayo.
You can also view it on GitHub: https://github.com/treenotation/ohayo
I wanted to try and make a fast, visual app for doing data science. I can't quite recommend it yet, but I think it might get there. If you are interested you can try it now.
by Breck Yunits
Note: I renamed Tree Notation to Particles. For the latest on this, start with Scroll.
This paper presents Tree Notation, a new simple, universal syntax. Language designers can invent new programming languages, called Tree Languages, on top of Tree Notation. Tree Languages have a number of advantages over traditional programming languages.
We include a Visual Abstract to succinctly display the problem and discovery. Then we describe the problem--the BNF to abstract syntax tree (AST) parse step--and introduce the novel solution we discovered: a new family of 2D programming languages that are written directly as geometric trees.
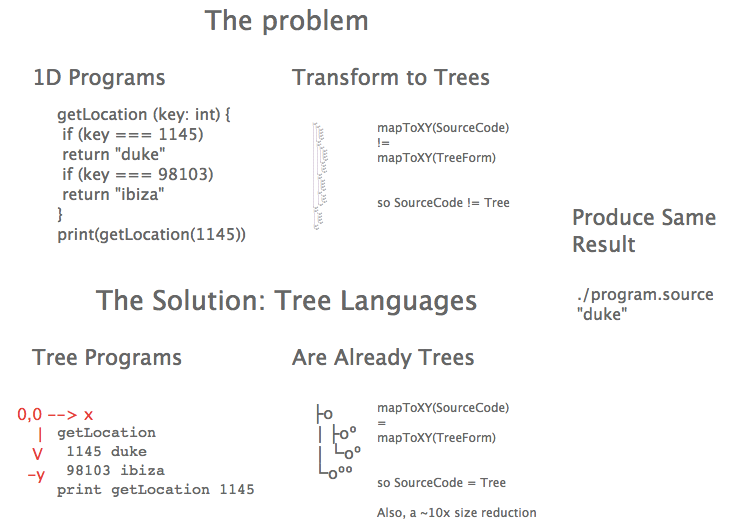
Figure 1. This Visual Abstract explains the core idea of the paper. This diagram is also the output of a program written in a new Tree Language called Flow.
The Problem
Programming is complicated. Our current 1-dimensional languages (1DLs) add to this complexity. To run 1DL code we first strip whitespace, then transform it to an AST and then transform that to executable machine code. These intermediate steps have enabled local minimum gains in developer productivity. But programmers lose time and insight due to discrepancies between 1DL code and ASTs.
The Solution: Tree Notation
In this paper and accompanying GitHub ES6 Repo (GER), we introduce Tree Notation (TN), a new 2D notation. A node in TN maps to an XY point on a 2D plane. You can extend TN to create domain specific languages (DSLs) that don't require a transformation to a discordant AST. These DSLs, called Tree Languages (TLs), are easy to create and can be simple or Turing Complete.
TN encodes one data structure, a TreeNode, with two members: a string called line and an optional array of child TreeNodes called children.
TN defines two special characters, Y Increment (YI) and X Increment (XI). YI is \n and XI is . XI is a space, not a tab. Many TLs also add a Word Increment (WI) to provide a more succint way of encoding common node types.
A comparison quickly illustrates nearly the entirety of the notation:
{
"title" : "Web Stats",
"visitors": {
"mozilla": 802
}
}title Web Stats
visitors
mozilla 802Useful Properties
Simplicity
As shown in Figure 1, TN simply maps source code to an XY plane which makes reading code locally and globally easy, and TL programs use far fewer source nodes than equivalent 1DL programs. TLs let programmers write much shorter, perfect programs.
Zero parse errors
Parse errors do not exist in TN. Every text string is a valid TN program. TLs implement microparsers that parallelize easily and can creatively handle errors.
With most 1DLs, to get from a blank program to a certain valid program in keystroke increments requires stops at invalid programs. With TN all intermediate steps are valid TN programs.
A user can edit the nodes of a program at runtime with no risk of breaking the TN parsing of the entire program. "Errors", still can exist at the TL level, but TL microparsers can handle errors independently and even correct errors automatically. TLs cut development and debug time.
Semantic diffs
1DLs ignore whitespace and so permit programmers and programs to encode the same object to different programs. This often causes merge conflicts for non-semantic changes.
TN does not ignore whitespace and diffs contain only semantic meaning. Just one right way to encode a program.
Easy composition
Base notations such as XML[2], JSON[3], and Racket[4] can encode multi-lingual programs by complecting language blocks. For example, the JSON program below requires extra nodes to encode Python:
{
"source": [
"import hn.np as lz\n",
"print(\"aaronsw pdm ah as mo gb 28-3\")"
]
}
With TN, the Python code requires no complecting:
source
import hn.np as lz
print("aaronsw pdm ah as mo gb 28-3")
Drawbacks
TN is new and tooling support rounds to zero.
TN lacks primitive types. Many 1DLs have notations for common types like floats, and parse directly to efficient in-memory structures. TLs make TN useful. The GER demonstrates how useful TLs can be built with just a few lines of code, which is far less code than one needs to implement even a simple 1DL such as JSON[5].
TN is verbose without a TL. A complex node in TN takes multiple lines. Base 1DLs allow multiple nodes per line.
Some developers dislike space-indented notations, some wrongly prefer tabs, and some just have no taste.
Predictions
Prediction 1: no structure will be found that cannot serialize to TN. Some LISP programmers believe all structures are recursive lists (or perhaps "recursive cons"). We believe in The Tree Conjecture (TTC): All structures are trees.
For example, a map could serialize to MapTL:
dsl Domain Specific Language
sf San Francisco
Therefore, maps are a type of tree. TTC stands.
Prediction 2: TLs will be found for every popular 1DL. Below is some code in a simple TL, JsonTL:
o
s dsl yrt
n ma 902
TLs will be found for great 1DLs including C, RISC-V, ES6, and Arc. Some TLs have already been found[6], but their common TN DNA has gone unseen. The immediate benefit of creating a TL for an 1DL is that programs can then be written in a TL editor and compiled to that 1DL.
Prediction 3: Tree Oriented Programming (TOP) will supersede Object Oriented Programming. A new style of programming, TOP, will arise. TOP programmers will frequently reference 2D views of their program.
Prediction 4: The simplest 2D text encodings for neural networks will be TLs. High level TLs will be found to translate machine written programs into understandable trees.
Literature Review
Turing Machines with 2D Tapes have been studied and are known to be Turing Complete[7]. A few esoteric 2D programming languages are available online[8]. At time of publication, 387 programming languages and notations were searched and many thousands of pages of research and code was read but TN was not found.
The closest someone came to discovering TN, and TLs, was perhaps Mark B. Wells, who wrote a brillant paper at Los Alamos, back in 1972 which predicted the discovery and utility of something like TLs[1].
Further Research
The GER contains a TN parser, grammar notation, Tree Language compiler-compiler (TLCC), VM, and some TLs.
Future publications might explore the Tree Notation Grammar, TLCC, or machine-written TL programs.

Rearranging these fridge magnets is equivalent to editing a TN program. The fridge magnet set that includes parentheses is a poor seller.
References
[1] Wells, Mark B. "A REVIEW OF TWO-DIMENSIONAL PROGRAMMING LANGUAGES*". 1972. http://sci-hub.cc/10.1145/942576.807009 (visited in 2017).
[2] Bray, Tim, et al. "Extensible markup language (XML)." World Wide Web Consortium Recommendation REC-xml-19980210. http://www. w3. org/TR/1998/REC-xml-19980210 16 (1998): 16.
[3] Crockford, Douglas. "The application/json media type for javascript object notation (json)." (2006).
[4] Tobin-Hochstadt, Sam, et al. "Languages as libraries." ACM SIGPLAN Notices. Vol. 46. No. 6. ACM, 2011.
[5] Ooms, Jeroen. "The jsonlite package: A practical and consistent mapping between json data and r objects." arXiv preprint arXiv:1403.2805 (2014).
[6] Roughan, Matthew, and Jonathan Tuke. "Unravelling graph-exchange file formats." arXiv preprint arXiv:1503.02781 (2015).
[7] Toida, Shunichi. "Types of Turing Machines." http://www.cs.odu.edu/~toida/nerzic/390teched/tm/othertms.html (visited in 2017).
[8] Ender, Martin. "A two-dimensional, hexagonal programming language." https://github.com/m-ender/hexagony (visited in 2017).
Original published on arXiv
June 21, 2017 — Eureka! I wanted to announce something small, but slightly novel, and potentially useful.
What did I discover? That there might be useful general purpose programming languages that don't use any visible syntax characters at all.
I call the whitespace-based notation Tree Notation and languages built on top of it Tree Languages.
Using a few simple atomic ingredients---words, spaces, newlines, and indentation--you can construct grammars for new programming languages that can do anything existing programming languages can do. A simple example:
if true
print Hello world
This language has no parentheses, quotation marks, colons, and so forth. Types, primitives, control flow--all of that stuff can be determined by words and contexts instead of introducing additional syntax rules. If you are a Lisper, think of this "novel" idea as just "lisp without parentheses."
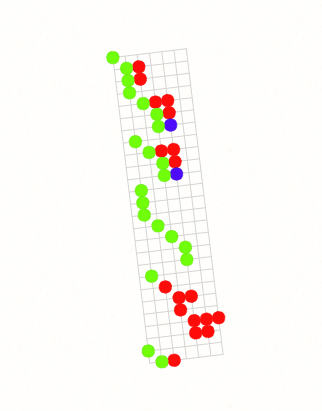
Programs in this system look sort of like DNA strands. The balls in this program represent words, and the colors represent the types of those words.
There are hundreds of very active programming languages, and they all have different syntax as well as different semantics.
I think there will always be a need for new semantic ideas. The world's knowledge domains are enormously complex (read: billions/trillions of concepts, if not more), machines are complex (billions of pieces), and both will always continue to get more complex.
But I wonder if we always need a new syntax for each new general purpose programming language. I wonder if we could unlock potentially very different editing environments and experiences with a simple geometric syntax, and if by making the syntax simpler folks could build better semantic tooling.
Maybe there's nothing useful here. Perhaps it is best to have syntax characters and a unique syntax for each general purpose programming language. Tree Notation might be a bad idea or only useful for very small domains. But I think it's a long-shot idea worth exploring.
Thousands of language designers focus on the semantics and choose the syntax to best fit those semantics (or a syntax that doesn't deviate too much from a mainstream language). I've taken the opposite approach--on purpose--with the hopes of finding something overlooked but important. I've stuck to a simple syntax and tried to implement all semantic ideas without adding syntax.
Initially I just looked at Tree Notation as an alternative to declarative format languages like JSON and XML, but then in a minor "Eureka!" moment, realized it might work well as a syntax for general purpose Turing complete languages across all paradigms like functional, object-oriented, logic, dataflow, et cetera.
Someday I hope to have data definitively showing that Tree Notation is useful, or alternatively, to explain why it is suboptimal and why we need more complex syntax.
I always wanted to try my hand at writing an academic paper. So I put the announcement in a 2-page paper on GitHub and arxiv. The paper is titled Tree Notation: an antifragile program notation. I've since been informed that I should stick to writing blog posts and code and not academic papers, which is probably good advice :).
Updated 12/30/2017
- After I wrote this I was informed that one other person from the Scheme world created a very similar notation years ago. Very little was written in it, which I guess is evidence that the notation itself isn't that useful, or perhaps that there is still something missing before it catches on.
- The second note is I updated the wording of this post as the original was a bit rushed.
Updated 2024
We renamed Tree Notation Particles. We now call the Grammar language Parsers. See the latest at Scroll.pub
Related Posts
- Particle Chain: A New Kind of Blockchain (2024)
- ETA!: A Measure of Evolution (2024)
- ICS: A Measure of Intelligence (2024)
- PTCRI: An Equation about Syntax Potential (2024)
- ScrollSets: A New Way to Store Knowledge (2024)
- PC: Particle Complexity (2017)
- Parsers: a language for making languages (2017)
- Tree Notation: an antifragile program notation (2017)
A Suggestion for a Simple Notation
September 24, 2013 — What if instead of talking about Big Data, we talked about 12 Data, 13 Data, 14 Data, 15 Data, et cetera? The # refers to the number of zeroes we are dealing with.
You can then easily differentiate problems. Some companies are dealing with 12 Data, some companies are dealing with 15 Data. No company is yet dealing with 19 Data. Big Data starts at 12 Data, and maybe over time you could say Big Data starts at 13 Data, et cetera.
What do you think?
This occurred to me recently as I just started following Big Data on Quora and was surprised to see the term used so loosely, when data is something so easily measurable. For example, a 2011 Big Data report from McKinsey defined big data as ranging "from a few dozen terabytes to multiple petabytes (thousands of terabytes)." Wikipedia defines Big Data as "a collection of data sets so large and complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications."
I think these terms make Big Data seem mysterious and confusing, when in fact it could be completely straightforward.
September 23, 2013 — Making websites is slow and frustrating.
I met a young entrepreneur who wanted to create a website for his bed and breakfast. He had spent dozens of hours with different tools and was no closer to having what he wanted.
I met a teacher who wanted his students to turn in web pages for homework instead of paper pages. No existing tool allows his students to easily create pages without restricting their creativity.
I met an artist who wanted a website with a slideshow for her portfolio.
A restaurant owner who wanted a website that could take online orders.
An author who wanted a website with a blog.
A saleswoman who wanted to build a members-only site for great deals she gathered.
A candidate who wanted a website that could coordinate his volunteers.
A nonprofit founder who wanted a website that told the story of impoverished children in his country and accepted donations.
These are just a handful of real people with real ideas who are frustrated by the current tools.
The problem
The fact is, people want to do millions of different things with their websites, but the only two options are to use a tool that limits your creative potential or to program your site from scratch. Neither option is ideal.
The solution
Which is why we're building a third option. We are building an open source, general purpose IDE for building websites.
Here's a short video demonstrating how it works:
NudgePad is in early beta, but is powering a number of live websites like these:
Although we have a lot more to do to get to a stable version 2.0, we thought the time was right to start opening up NudgePad to more people and recruiting more help for the project. We also want to get feedback on the core ideas in NudgePad.
To get involved, give NudgePad a try or check out the source code on GitHub.
We truly believe this new way to build websites--an IDE in your browser-- is a faster way to build websites and the way it will be done in the future. By this time next year, using NudgePad, it could be 100x faster and easier to build websites than it is today.
June 2, 2013 — I have an idea for a simpler Internet, where a human could hold in their head, how it all works, all at once.
It would work much the same way as the Internet does now except for one major change. Almost all protocols and encodings such as TCP/IP, HTTP, SMTP, MIME, XML, Zone files, et cetera are replaced by a lightweight language called Scroll.
Computers would still communicate by sending and receiving packets, but those packets would be human readable Scroll messages.
Programs would not have to speak dozens of different grammars for different services but could be equipped to work with Scroll and easily send and receive messages to other programs on ScrollNet.
A user could learn Scroll in under an hour and then have the ability to create and broadcast raw Scroll messages that could send emails, request web pages, trigger remote APIs, and much more.
A user could inspect all ScrollNet traffic and not have the slightest bit of difficulty understanding what was happening on their wires.
A user could experiment with creating languages on top of Scroll that could make ScrollNet do all sorts of neat things with minimal effort and without breaking existing programs.
An example electronic message on ScrollNet might look like this:
to vint@cerf.com bob@bob.com
from breck7@gmail.com
subject ScrollNet: Good idea or bad idea?
message Would love to hear your thoughts.
This is simpler than how that message currently looks on the current Internet:
MIME-Version: 1.0 Received: by 10.76.12.234 with HTTP; Sun, 2 Jun 2013 16:36:57 -0700 (PDT) Date: Sun, 2 Jun 2013 16:36:57 -0700 Delivered-To: Vint Cerf <vint@cerf.com>, Bob Kahn <bob@kahn.com> Subject: ScrollNet: Good idea or bad idea? From: Breck Yunits <breck7@gmail.com> To: Me <breck7@gmail.com> Content-Type: multipart/alternative; boundary=bcaec554097aeca02704de34521c —bcaec554097aeca02704de34521c Content-Type: text/plain; charset=ISO-8859-1 Would love to hear your thoughts. —bcaec554097aeca02704de34521c Content-Type: text/html; charset=ISO-8859-1 Would love to hear your thoughts. —bcaec554097aeca02704de34521c—
To transmit that message, the computer would add a transport encoding to the message, which on the Internet contains a fixed size header containing unprintable characters but on ScrollNet might look something like this:
header
source 1.1.1.1
destination 1.1.1.1
length 135
sourcePort 80
destinationPort 81
sequenceNumber 1
acknowledgementNumber 1
checksum 234fsdafsda534453
to vint@cerf.com bob@bob.com
from breck7@gmail.com
subject ScrollNet: Good idea or bad idea?
message Would love to hear your thoughts.
Scroll can serve both as the high level encoding at the application layer and the low level encoding at the transport layer.
Of course, there are obvious issues that come up. How does hardware do packet switching with variable width headers? Is the increased packet header size a concern? Then of course, there’s the big issue of whether Scroll is even a good language. Why not XMLNet, or JSONNet? There are answers to those questions, but for now I just wanted to share this idea and see what people thought.
The current Internet works incredibly well, and has grown to be many magnitudes larger than its predecessor ARPANET. But only a tiny fraction of the population understands how it works at a low level, and even those who do had to invest considerable time to learn all of the encodings and pieces.
The complexity of current Internet protocols could be holding us back from an even better successor that can benefit from orders of magnitude more tinkerers and experimenters.
Related Posts
- Knowledge (2025)
- Ford (2025)
- Experiments (2025)
- Pretext (2025)
- What Science May Be (2025)
- Thinking in Parsers (2025)
- What is Particle Syntax? (2025)
- What is Mathematics? (2025)
- Why Define a New Language? (2024)
- Breckchain (2024)
- Particle Thinking (2024)
- Why Scroll? (2024)
- Microprogramming: A New Way to Program (2024)
- Particle Chain: A New Kind of Blockchain (2024)
- ETA!: A Measure of Evolution (2024)
- CheckBox: An Online + Offline Voting System (2024)
- The World Wide Scroll (2024)
- Download this Blog (2024)
- ICS: A Measure of Intelligence (2024)
- PTCRI: An Equation about Syntax Potential (2024)
- Patch: a micro language to make pretty deep links easy (2024)
- What can we learn from programming language version numbers? (2024)
- ScrollSets: A New Way to Store Knowledge (2024)
- Hot Coffee (2024)
- Final Tree Notation Report (2024)
- Words are Worse than Weights (2024)
- I thought we could build AI experts by hand (2023)
- A Proposal to Solve Government Forms Worldwide, Forever (2023)
- Use the Spine (2023)
- One Textarea (2022)
- Root Thinking (2022)
- Aftertext (2021)
- Scrolldown now has Dialogues (2021)
- The Public Domain Publishing Company (2021)
- Scroll Beta (2021)
- 2019 Tree Notation Annual Report (2020)
- Building a TreeBase with 6.5 million files (2020)
- Dataset Needed (2020)
- Type the World (2020)
- Dreaming of a Logic Checked Language (2020)
- Removing the 2’s from Trinary Notation is a Terrible Idea. (2019)
- PC: Particle Complexity (2017)
- Parsers: a language for making languages (2017)
- Ohayo (2017)
- Tree Notation: an antifragile program notation (2017)
- A New Discovery in Computer Science: 2-Dimensional Programming Languages (2017)
- NudgePad: An IDE in Your Browser (2013)
- Introducing Note (2012)
I originally published this on Medium.
April 2, 2013 — For me, the primary motivation for creating software is to save myself and other people time.
I want to spend less time doing monotonous tasks.
Less time doing bureaucratic things. Less time dealing with unnecessary complexity. Less time doing chores.
I want to spend more time engaged with life.
Saving people time is perhaps the only universal good.
Everyone wants to have more options with their time.
Everyone benefits when a person has more time. They can enjoy that extra time and/or invest some of it to make the world better for everyone else.
Nature loves to promote inequality, but a fascinating feature of time is that it is so equally distributed.
Nature took the same amount of time to evolve all of us alive today.
All of our evolutionary paths are equally long.
We also have equal amounts of time to enjoy life, despite the fact that other things may be very unequally distributed.
The very first program I made was meant to save me and my family time. Back in 1996, to start our computer, connect to the Internet and launch Netscape took about 20 minutes, and you had to do each step sequentially. My first BAT script automated that to allow you to turn the computer on and go play outside for 20 minutes while it connected to the web.
Many years later, my ultimate motivation to save people time has remained constant.
Time
by Breck Yunits
Two people in the same forest,
have the same amount of water and food,
Are near each other, but may be out of sight,
The paths behind each are equally long.
The paths ahead, may vary.
One's path is easy and clear.
The other's is overgrown and treacherous.
Their paths through the forest,
in the past, in the present, and ahead
are equal.
Their journeys can be very different.
March 30, 2013 — Why does it take 10,000 hours to become a master of something, and not 1,000 hours or 100,000 hours?
The answer is simple. Once you've spent 10,000 hours practicing something, no one can crush you like a bug.
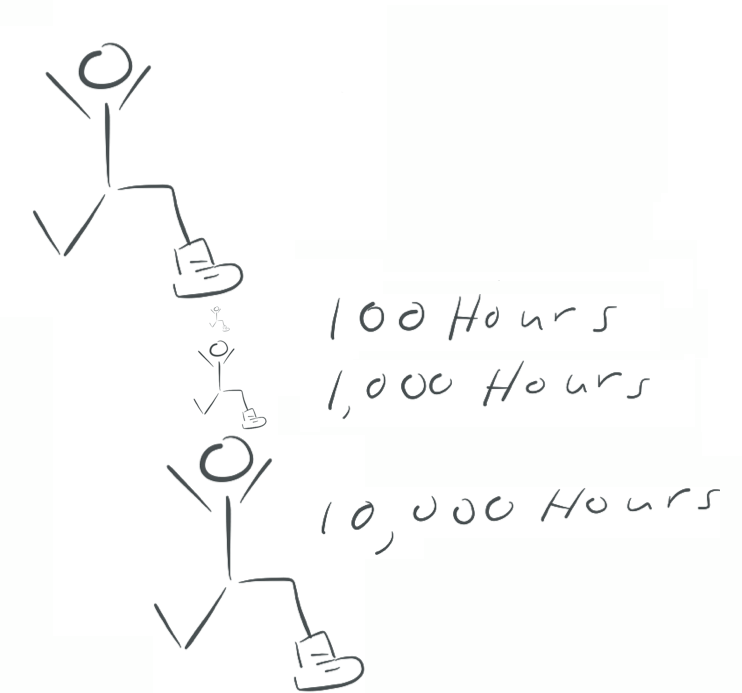
The figure on top has 10,000 hours of experience and crushes people with 100 hours or 1,000 hours like a bug. But they cannot crush another person with 10,000 hours.
Nature loves inequality
Nature loves inequality. For example, humans are 1,000x bigger than bugs.
It is very easy for a human to squash a bug.
100 Hours
When you are starting to learn something and have spent say, 100 hours practicing that thing, you, my friend, are the bug.
There are many people out there who have been practicing that thing for 10,000 hours, and can easily crush you like a bug (if they are mean spirited like that ;) ).
1,000 Hours
Once you've got 1,000 hours of practice under your belt, it becomes hard for someone to easily crush you.
10,000 Hours
You reach 10,000 hours of practice, and you are now at a level where no one can crush you like a bug.
You can put up a fight against anyone.
100,000 Hours
It is near impossible for a human to practice something for 100,000 hours.
That would be 40 hours of practice per week for fifty years!
Life is too chaotic, and our bodies are too fragile, to hit that level of practice.
Thus, when you hit 10,000 hours, you're at "mastery level".
Almost no one one in the world will know 10x more than you.[1]
Do you hear them talking of genius, Degna? There is no such thing. Genius, if you like to call it that, is the gift of work continuously applied. That's all it is, as I have proved for myself. @ Guglielmo Marconi
Related Posts
Notes
[1] Perhaps to be one of the greatest of all time, you have to both be constantly practicing and have exceptional luck to live a healthy long live.
The crux of the matter, is that people don't understand the true nature of money. It is meant to circulate, not be wrapped up in a stockingGuglielmo Marconi
March 30, 2013 — I love Marconi's simple and clear view of money. Money came in and he put it to good use. Quickly. He poured money into the development of new wireless technology which had an unequal impact on the world.
This quote, by the way, is from "My Father, Marconi", a biography of the famous inventor and entrepreneur written by his daughter, Degna. Marconi's story is absolutely fascinating. If you like technology and entrepreneurship, I highly recommend the book.
P.S. This quote also applies well to most man made things. Cars, houses, bikes, et cetera, are more valuable circulating than idling. It seemed briefly we were on a trajectory toward overabundance, but the sharing economy is bringing circulation back.
March 16, 2013 — A kid says Mommy or Daddy or Jack or Jill hundreds of times before grasping the concept of a name.
Likewise, a programmer types name = Breck or age=15 hundreds of times before grasping the concept of a variable.
What do you call it when someone finally sees the concept?
John Calcote, a programmer with decades of experience, calls it a minor epiphany.
Minor epiphanies. Anyone who's programmed for a while can appreciate that term.
When you start programming you do pure trial and error. What will happen when I type this or click that? You rely on memorization of action and reaction. Nothing makes sense. Every single term--variable, object, register, boolean, int, string, array, and so on--is completely and utterly foreign.
But you start to encounter these moments. These minor epiphanies, where suddenly you see the connection between a class of things. Suddenly something makes sense. Suddenly one term is not so foreign anymore. You have a new tool at your disposable. You have removed another obstacle that used to trip you.
In programming the well of minor epiphanies never runs dry. Even after you've learned thousands of things the epiphanies keep flowing at the same rate. Maybe the epiphanies are no longer about what the concept is, or how you can use it, but now are more about where did this concept come from, when was it created, who created it, and most fascinating of all, why did they create it?
Minor epiphanies give you a rush, save you time, help you make better products, and help you earn more.
As someone who loves to learn, my favorite thing about them is the rush you get from having something suddenly click. They make this programming thing really, really fun. Day in and day out.
Notes
- I stumbled upon the term in John Calcote's book "Autotools".
March 8, 2013 — If your software project is going to have a long life, it may benefit from Boosters. A Booster is something you design with two constraints: 1) it must help in the current environment 2) it must be easy to jettison in the next environment.

February 24, 2013 — It is a popular misconception that most startups need to fail. We expect 0% of planes to crash. Yet we switch subjects from planes to startups and then suddenly a 100% success rate is out of the question.
This is silly. Maybe as the decision makers switch from gambling financeers to engineers we will see the success rate of starting a company shoot closer to 100%.
February 16, 2013 — Some purchasing decisions are drastically better than others. You might spend $20 on a ticket to a conference where you meet your next employer and earn 1,000x "return" on your purchase. Or you might spend $20 on a fancy meal and have a nice night out.
Purchasing decisions have little direct downside. You most often get your money's worth.
The problem is the opportunity cost of purchases. That opportunity cost can cost you a fortune.
Since some purchases can change your life, delivering 100x or greater return on your investment, spending your money on things that only give you a 10% return can be a massive mistake, because you'll miss out on those great deals.
It's best to say "no" to a lot of deals. Say "yes" to the types of deals that you know deliver massive return.
- For me, this is: books, meeting people, coffee (which I use as "fuel" for creating code which generates a strong return).
- I'm not advocating being a penny pincher. I'm advocating being aware of the orders of magnitude difference in return from purchases.
- I wonder if someday we'll have credit cards that help you be aware of the order of magnitude variance in expected value of purchases. It seems like one great benefit, would be to charge a higher interest rate on purchases that have low expected value, and a very low interest rate on purchases with high expected value (like books).
February 12, 2013 — You shouldn't plan for the future. You should plan for one of many futures.
The world goes down many paths. We only get to observe one, but they all happen.
In the movie "Back to the Future II", the main character Marty, after traveling decades into the future, buys a sports alamanac so he can go back in time and make easy money betting on games. Marty's mistake was thought he had the guide to the future. He thought there was only one version of the future. In fact, there are many versions of the future. He only had the guide to one version.
Marty was like the kid who stole the answer key to an SAT but still failed. There are many versions of the test.
There are infinite futures. Prepare for them all!
December 29, 2012 — I love that phrase.
I want to learn how to program. Prove it.
I value honesty. Prove it.
I want to start my own company. Prove it.
It works with "we" too.
We're the best team in the league. Prove it.
We love open source. Prove it.
We're going to improve the transportation industry. Prove it.
Words don't prove anything about you. How you spend your time proves everything.
The only way to accurately describe yourself or your group is to look at how you've spent your time in the past.
Anytime someone says something about what they will do or be like in the future, your response should be simple: prove it.
December 23, 2012 — If you are poor, your money could be safer under the mattress than in the bank:
The Great Bank Robbery dwarfs all normal burglaries by almost 10x. In the Great Bank Robbery, the banks are slowly, silently, automatically taking from the poor.
One simple law could change this:
What if it were illegal for banks to automatically deduct money from someone's account?
If a bank wants to charge someone a fee, that's fine, just require they send that someone a bill first.
What would happen to the statistic above, if instead of silently and automatically taking money from people's accounts, banks had to work for it?
Sources
Moebs via wayback machine
December 22, 2012 — Entrepreneurship is taking responsibility for a problem you did not create.
It was not Google's fault that the web was a massive set of unorganized pages that were hard to search, but they claimed responsibility for the problem and solved it with their engine.
It was not Dropbox's fault that data loss was common and sharing files was a pain, but they claimed responsibility for the problem and solved it with their software.
It is not Tesla's fault that hundreds of millions of cars are burning gasoline and polluting our atmosphere, but they have claimed responsibility for the problem and are attempting to solve it with their electric cars.
In a free market, like in America or online, you can attempt to take responsibility for any problem you want. That's pretty neat. You can decide to take responsibility for making sure your neighborhood has easy access to great Mexican food. Or you can decide to take responsibility for making sure the whole Internet has easy access to reliable version control. If you do a good job, you will be rewarded based on how big the problem is and how well you solve it.
How big an entrepreneur's company gets is strongly correlated with how much responsibility the entrepreneur wants. The entrepreneur gets to constantly make choices about whether they want their company to take on more and more responsibility. Companies only get huge because their founders say "yes" to more and more responsibility. Oftentimes they can say "yes" to less responsibility, and sell their company or fold it.
Walmart started out as a discount store in the Midwest, but Sam Walton (and his successors) constantly said "yes" to more and more responsibility and Walmart has since grown to take on responibility for discounting across the world.
Google started out with just search, but look at all the other things they've decided to take responsibility for: email, mobile operating systems, web browsers, social networking, document creation, calendars, and so on. Their founders have said "yes" to more and more responsibility.
Smart entrepreneurship is all about choosing problems you can and want to own. You need to say "no" to most problems. If you say "yes" to everything, you'll stretch yourself too thin. You need to increase your responsibility in a realistic way. You need to focus hard on the problems you can solve with your current resources, and leave the other problems for another company or another time.

There's a man in the world who is never turned down, wherever he chances to stray; he gets the glad hand in the populous town, or out where the farmers make hay; he's greeted with pleasure on deserts of sand, and deep in the aisles of the woods; wherever he goes there's the welcoming hand--he's The Man Who Delivers the Goods. The failures of life sit around and complain; the gods haven't treated them white; they've lost their umbrellas whenever there's rain, and they haven't their lanterns at night; men tire of the failures who fill with their sighs the air of their own neighborhoods; there's one who is greeted with love-lighted eyes--he's The Man Who Delivers the Goods. One fellow is lazy, and watches the clock, and waits for the whistle to blow; and one has a hammer, with which he will knock, and one tells a story of woe; and one, if requested to travel a mile, will measure the perches and roods; but one does his stunt with a whistle or smile--he's The Man Who Delivers the Goods. One man is afraid that he'll labor too hard--the world isn't yearning for such; and one man is always alert, on his guard, lest he put in a minute too much; and one has a grouch or a temper that's bad, and one is a creature of moods; so it's hey for the joyous and rollicking lad--for the One Who Delivers the Goods! Walt Mason, his book (1916)
December 19, 2012 — For a long time I've believed that underpromising and overdelivering is a trait of successful businesses and people. So the past year I've been trying to overdeliver.
But lately I realized that you cannot try to overdeliver. All an individual can do is deliver, deliver, deliver. Delivering is a habit that you get into. Delivering is something you can do.
Overdelivering is only something a team can do. The only way to overdeliver, is for a team of people to constantly deliver things to each other, and then the group constantly delivers something to other people that that person could never imagine doing alone.
But in your role on a team, the key isn't to worry about overdelivering, just get in the habit of delivering.
Be the One who delivers the goods!
December 19, 2012 — For the past year I've been raving about Node.js, so I cracked a huge smile when I saw this question on Quora:
In five years, which language is likely to be most prominent, Node.js, Python, or Ruby, and why?
For months I had been repeating the same answer to friends: "Node.js hands down. If you want to build great web apps, you don't have a choice, you have to master Javascript. Why then master two languages when you don't need to?"
Javascript+Node.js is to Python and Ruby what the iPhone is to MP3 players--it has made them redundant. You don't need them anymore.
So I started writing this out and expanding upon it. As I'm doing this, a little voice in my head was telling me something wasn't right. And then I realized: despite reading Taleb's books every year, I was making the exact mistake he warns about. I was predicting the future without remembering that the future is dominated not by the predictable, but by the unpredictable, the Black Swans.
And sure enough, as soon as I started to imagine some Black Swans, I grew less confident in my prediction. I realized all it would take would be for one or two browser vendors to start supporting Python or Ruby or language X in the browser to potentially disrupt Node.js' major advantage. I don't think that's likely, but it's the type of low probability event that could have a huge impact.
When I started to think about it, I realized it was quite easy to imagine Black Swans. Imagine visiting hackernews in 2013 and seeing any one of these headlines:
- Microsoft Open Sources Windows.
- Researchers Crack SSL. Render it useless.
- Google Perfects Voice Recognition.
- Facebook Covers the World in Free Wifi.
- Amazon Launches Distributed Data Centers in your home.
It took only a few minutes to imagine a few of these things. Clearly there are hundreds of thousands of low probability events that could come from established companies or startups that could shift the whole industry.
The future is impossible to predict accurately.
Notes
All that being said, Node.js kicks ass today(the Javascript thing, the community, the speed, the packages, the fact I don't need a separate web server anymore...it is awesome), and I would not be surprised if Javascript becomes 10-100x bigger in the years ahead, while I can't say the same about other languages. And if Javascript doesn't become that big, worst case is it's still a very powerful language and you'll benefit a lot from focusing on it.
December 18, 2012 — My whole life I've been trying to understand how the world works. How do planes fly? How do computers compute? How does the economy coordinate?
Over time I realized that these questions are all different ways of asking the same thing: how do complex systems work?
The past few years I've had the opportunity to spend thousands of hours practicing programming and studying computers. I now understand, in depth, one complex system. I feel I can finally answer the general question about complex systems with a very simple answer.
Compounded Probability Makes Complex Systems Work
There is no certainty in life or in systems, but there is probability, and probability compounds.
We can combine the high probability that wheels roll, with the high probability that wood supports loads, to build a wooden chariot that has a high probability of carrying things from point A to point B, which has a high probability of giving us more time to innovate, and so on and so forth...
Everything is built off of probability. You are reading this because of countless compounded probabilities like:
- There is a high probability that your Internet connection works
- There is a high probability that my web server is responding to connections
- There is a high probability that my web server's disk works
- There is a high probability that my web software works and will handle this post
- There is a high probability that my Internet connection works
- There is a high probability that my text editor won't fail as I write this
- There is a high probability that my laptop works
- There is a high probability that the CPU in my laptop consistently adds numbers in the registers correctly
Complex systems consist of many, many simple components with understood probabilities stitched together.
How does a plane fly? The most concise and accurate answer isn't about aerodynamics or lift, it's about probabilities. A plane is simply a huge system of compounded probabilities.
How does a bridge stay up? The answer is not about physics, it's about compounded probabilities.
How do computers work? Compounded probability.
How do cars work? Compounded probability.
The economy? Compounded probability.
Medicine? Compounded probability.
It's probability all the way down.
December 18, 2012 — One of Nassim Taleb's big recommendations for how to live in an uncertain world is to follow a barbell strategy: be extremely conservative about most decisions, but make some decisions that open you up to uncapped upside.
In other words, put 90% of your time into safe, conservative things but take some risks with the other 10%.
I personally try to follow this advice, particularly with our startup. I think it is good advice. I think it would be swell if our company became a big, profitable, innovation machine someday. But that's not what keeps me up at night.
I'm more concerned about creating the best worst case scenario. I spend most of my time trying to improve the worst case outcomes. Specifically, here's how I think you do this:
Tackle a big problem. Worst case scenario is you don't completely solve it, but you learn a lot in that domain and get acquired/acquihired by a bigger company in the space. That's a great outcome.
Build stuff you want. Worst case scenario is no one uses your product but you. If you aren't a fan of what you build, then you have nothing. If you love your product, that's a great outcome.
Focus on your customers. Make sure your customers are happy and getting what they want. Worst case scenario, you made a couple people of people happy. That's a great outcome.
Practice your skills. Worst case scenario is the company doesn't work out, but you are now much better at what you do. That's a great outcome.
Deliver. Worst case scenario is you deliver something that isn't quite perfect but is good and helps people. That's a great outcome.
Avoid debt. If you take on debt or raise money, worst case scenario is you run out of time and you lose control of your destiny. If you keep money coming in, worst case scenario is things take a little longer or if you move on you are not in a hole. That's a great outcome.
Enjoy life. Make sure you take time to enjoy life. Worst case scenario is you spend a few years with no great outcome at work but you have many great memories from life. That's a great outcome.
Then, if you want to make yourself open to positive black swans, you can put 10% of your efforts into things that make you more open to those like: recruiting world class talent, pitching and raising money, tackling bigger markets. But make sure you focus on the conservative things. Risk, in moderation, is a good thing. Risk, in significant amounts, is for the foolish.
December 16, 2012 — Concise but not cryptic. e=mc² is precise and not too cryptic. Shell commands, such as chmod -R 755 some_dir are concise but very cryptic.
Understandable but not misleading. "Computing all boils down to ones and zeros" is understandable and not misleading. "Milk: it does a body good", is understandable but misleading.
Minimal but not incomplete. A knife, spoon and fork is minimal. Just a knife is incomplete.
Broad but selective. A knife, spoon, and fork is broad and selective. A knife, spoon, fork and turkey baster is just as broad but not selective.
Flat but not too flat. 1,000 soldiers is flat but too flat. At least a few officers would be better.
Anthropocentric not presentcentric. Shoes are relevant to people at any time. An iPhone 1 case is only useful for a few years.
Cohesive but flexible. You want the set to match. But you want each item to be independently improvable.
Simple is balanced. It is nuanced, not black and white.
December 16, 2012 — When I was a kid I loved reading the Family Circus. My favorite strips were the "dotted lines" ones, which showed Billy's movements over time:
These strips gave a clear narrative of Billy's day. In the strip above, Billy, a fun loving kid, was given a task by his mother to put some letters in the mailbox before the mailman arrives. Billy took the letters, ran into the kitchen, then dashed into the living room, jumped on the couch, sprinted to the dining room, crawled under the dining room table, skipped into the TV room, jumped into the crib, twirled into the foyer, stumbled outside, swung around the light post, then ran to the mailbox.
We know the end result: Billy failed to get to the mailbox in time.
With this picture in mind, let's do a thought experiment.
Let's imagine that right now, once again, Billy and his mom are standing in the laundry room and she's about to give him the mail. What are the odds that Billy gets to the mailbox in time?
Pick a range, and then click here to see the answer.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
December 14, 2012 — Note is a structured, human readable, concise language for encoding data.
XML to JSON to Note
In 1998, a large group of developers were working on technologies to make the web simpler, more collaborative, and more powerful. Their vision and hard work led to XML and SOAP.
XML was intended to be a markup language that was "both human-readable and machine-readable". As Dave Winer described it, "XML is structure, simplicity, discoverability and new power thru compatibility."
SOAP, which was built on top of XML, was intended to be a "Simple Object Access Protocol". Dave said "the technology is potentially far-reaching and precedent-setting."
These technologies allowed developers across the world to build websites that could work together with other websites in interesting ways. Nowadays, most web companies have APIs, but that wasn't always the case.
Although XML and SOAP were a big leap forward, in practice they are difficult to use. It's arguable whether they are truly "human-readable" or "simple".
Luckily, in 2001 Douglas Crockford specified a simpler, more concise language called JSON. Today JSON has become the de facto language for web services.
Could JSON be improved?
Early last year, one idea that struck me was that subtle improvements to underlying technologies can have exponential impact. Fix a bug in subversion and save someone hours of effort, but replace subversion and save someone weeks.
The switch from XML to JSON had made my life so much easier, I wondered if you could extract an even simpler alternative to JSON. JSON, while simple, still takes a while to learn, particularly if you are new to coding. Although more concise than XML, JSON has at present six types and eight syntax characters, all of which can easily derail developers of all skill levels. Because whitespace is insignificant in JSON, it quickly becomes messy. These are all relatively small details, but I think perhaps getting the details right in a new encoding could make a big difference in developers' lives.
Introducing Note
After almost two years of tinkering, and with a lot of inspiration from JSON, XML, HAML, Python, YAML, and other languages, we have a new simple encoding that I hope might make it easier for people to create and use web services.
We dubbed the encoding Note, and have put an early version with Javascript support up on Github. We've also put out a quick demonstration site that allows you to interact with some popular APIs using Note.
Note is a text based encoding that uses whitespace to give your data structure. Note is simple: there are only two syntax characters (newline and space). It is concise--not a single keystroke is wasted (we use a single space for indentation--why use 2 when one is sufficient?). Note is neat: the meaningful whitespace forces adherance to a clean style. These features make Note very easy to read and to write.
Despite all this minimalism, Note is very powerful. Each note is a hash consisting of name/value pairs. Note is also recursive, so each note can be a tree containing other notes.
Note has only two types: strings and notes. Every entity in note is either a string or another Note. But Note is infinitely extendable. You can create domain specific languages on top of Note that support additional types as long as you respect the whitespace syntax of Note.
This is a very brief overview of the thinking behind Note and some of its features. I look forward to the months ahead as we start to implement Note on sites across the web and demonstrate some of the neat features and capabilities of the encoding.
Please feel free to email me with any questions or feedback you may have, as well as if you'd be interested in contributing.
November 26, 2012 — For todo lists, I created a system I call planets and pebbles.

I label each task as a planet or a pebble. Planets are super important things. It could be helping a customer complete their project, meeting a new person, finishing an important new feature, closing a new sale, or helping a friend in need. I may have 20 pebbles that I fail to do, but completing one planet makes up for all that and more.
I let the pebbles build up, and I chip away at them in the off hours. But the bulk of my day I try to focus on the planets--the small number of things that can have exponential impact. I don't sweat the small stuff.
I highly recommend this system. We live in a power law world, and it's important to practice the skill of predicting what things will prove hugely important, and what things will turn out to be pebbles.
Related Posts
November 25, 2012 — I published 55 essays here the first year. The second and third years combined, that number nosedived to 5.
What caused me to stop publishing?
It hasn't been a lack of ideas. All my essays start with a note to self. I have just as many notes to self nowadays as I did back then.
It hasn't been a lack of time. I have been working more but blogging doesn't take much time.
It's partly to do with standards. I've been trying to make higher quality things. I used to just write for an hour or two and hit publish. Now I'm more picky.
I've also become somewhat disappointed with the essay form. I am very interested in understanding systems, and I feel words alone don't explain systems well. So I've been practicing my visual and design skills. But I'm basically a beginner and output is slow.
The bottom line is I want to publish more. It forces me to think hard about my opinions, and it opens me up to advice from other people. I think this blog has helped me be less wrong about a lot of things. So here's to another fifty posts.
November 20, 2012 — "Is simplicity ever bad?" If you had asked me this a year ago, I probably would have called you a fucking moron for asking such a dumb question. "Never!", I would have shouted. Now, I think it's a fair question. Simplicity has it's limits. Simplicity is not enough, and if you pursue simplicity at all costs, that can be a bad thing. There's something more than simplicity that you need to be aware of. I'll get to that in a second, but first, I want to backtrack a bit and state clearly that I do strongly, strongly believe and strive for simplicity. Let me talk about why for a second.
Why I love simplicity
Simple products are pleasant to use. When I use a product, and it is easy to use, and it's quick to use, I love that. I fucking hate things that are not as simple as possible and waste people's time or mental energy as a result. For example, to file my taxes with the IRS, I cannot go to the IRS' website. It's much more complex than that. I hate that. It is painful. Complex things are painful to use. Simple things are pleasant to use. They make life better. This is, of course, well known to all good designers and engineers.
Simple things are also more democratic. When I can understand something, I feel smart. I feel empowered. When I cannot understand something, I feel stupid. I feel inferior. Complex things are hard to understand. The response shouldn't be to spend a long time learning the complex thing, it should be to figure out how to make the complex thing simpler. When you do that, you create a lot of value. If I can understand something, I can do something. When we make things simpler, we empower people. Often times I wonder if being a doctor would only take 2 years if Medicine abandoned Latin terms for a simpler vocabulary.
Reaching the Limits of Simplicity
This whole year, and well before that, I've been working with people trying to make the web simpler. The web is really complex. You need to know about HTML, CSS, Javascript, DNS, HTTP, DOM, Command Line, Linux, Web Servers, Databases, and so on. It's a fucking mess. It's fragmented to all hell as well. Everyone is using different languages, tools, and platforms. It can be a pain.
Anyway, we've been trying to make a simple product. And we've been trying to balance simplicity with features. And that's been difficult. Way more difficult than I would have predicted.
The thing is, simpler is not always better. A fork is simpler than a fork, knife, and spoon, but which would you rather have? The set is better. Great things are built by combining distinct, simple things together. If you took away the spoon, you'd make the set simpler, but not better. Which reminds me of that Einstein quote:
Make things as simple as possible, but not simpler.
I had always been focused on the first part of that quote. Make things as simple as possible. Lately I've thought more about the second part. Sometimes by trying to make things too simple you make something a lot worse. Often, less is more, but less can definitely be less.
People rave about the simplicity of the iPhone. And it is simple, in a sense. But it is also very complex. It has a large screen, 2 cameras, a wifi antenna, a GPS, an accelerometer, a gyroscope, a cell antenna, a gpu, cpus, memory, a power unit, 2 volume buttons, a power button, a home button, a SIM card slot, a mode switch, and a whole lot more. Then the software inside is another massive layer of complexity. You could try to make the iPhone simpler by, for example, removing the volume buttons or the cameras, but that, while increasing the simplicity, would decrease the "setplicity". It would remove a very helpful part of the set which would make the whole product worse.
Think about what the world would be like if we only used half of the periodic table of elements--it would be less beautiful, less enjoyable, and more painful.
Simplicity is a great thing to strive for. But sometimes cutting things out to make something simpler can make it worse. Simplicity is not the only thing to maximize. Make sure to balance simplicity with setplicity. Don't worry if you haven't reduced things to a singularity. Happiness in life is found by balancing amongst a set of things, not by cutting everything out.
October 20, 2012 — I love to name things.
I spend a lot of time naming ideas in my work. At work I write my code using a program called TextMate. TextMate is a great little program with a pleasant purple theme. I spend a lot of time using TextMate. For the past year I've been using TextMate to write a program that now consists of a few hundred files. There are thousands of words in this program. There are hundreds of objects and concepts and functions that each have a name. The names are super simple like "Pen" for an object that draws on the screen, and "delete" for a method that deletes something. Some of the things in our program are more important than others and those really important ones I've renamed dozens of times searching for the right fit.
There's a feature in TextMate that lets me find and replace a word across all 400+ files in the project. If I am unhappy with my word choice for a variable or concept, I'll think about it for weeks if not months. I'll use Thesaurus.com, I'll read about similar concepts, I'll run a subconscious search for the simplest, best word. When I find it, I'll hit Command+Shift+F in TextMate and excitedly and carefully execute a find and replace across the whole project. Those are some of my favorite programming days--when I find a better name for an important part of the program.
Naming a thing is like creating life from inorganic material in a lab. You observe some pattern, combine a bunch of letters to form a name, and then see what happens. Sometimes your name doesn't fit and sits lifeless. But sometimes the name is just right. You use it in conversation or in code and people instantly get it. It catches on. It leaves the lab. Your name takes a life of its own and spreads.
Words are very contagious. The better the word, the more contagious it can be. Like viruses, small differences in the quality of a word can have exponential differences on it's spread. So I like to spend time searching for the right words.
Great names are short. Short names are less effort to communicate. The quality of a name drops exponentially with each syllable you add. Coke is better than Coca-Cola. Human is better than homo sapiens.
Great names are visual. A good test of whether a name is accurate is whether you can draw a picture of the name that makes sense. Net is better than cyberspace. If you drew a picture of the physical components of the Internet, it would look a lot like a fishing net. Net is a great name.
Great names are used for great ideas. You should match the quality of a name to the quality of the idea compared to the other ideas in the space. This is particularly applicable in the digital world. If you are working on an important idea that will be used by a lot of people in a broad area, use a short, high quality name. If you are working on a smaller idea in that same area, don't hog a better name than your idea deserves. Linux is filled with great programs with bad names and bad programs with great names. I've been very happy so far with my experience with NPM, where it seems programmers who are using the best names are making their programs live up to them.
I think the exercise of naming things can be very helpful in improving things. Designing things from first principles is a proven way to arrive at novel, sometimes better ideas. Attempting to rename something is a great way to rethink the thing from the ground up.
For example, lately I've been trying to come up with a way to explain the fundamentals of computing. A strategy I recently employed was to change the names we use for the 2 boolean states from True and False to Absent or Present. It seems like it gets closer to the truth of how computers work. I mean, it doesn't make sense to ask a bit whether it is True or False. The only question an electronic bit can answer is whether a charge is present or absent. When we compare variable A to variable B, the CPU sets a flag in the comparison bit and we are really asking that bit whether a charge is present.
What I like about the idea of using the names Present and Absent is that it makes the fundamentals of computing align with the fundamentals of the world. The most fundamental questions in the world about being--of existence. Do we exist? Why do we exist? Will we exist tomorrow? Likewise, the most fundamental questions in computing is not whether or not there are ones and zeroes, it's whether or not a charge exists. Does a charge exist? Why does that charge exist? Will that charge exist in the next iteration? Computing is not about manipulating ones and zeroes. It's about using the concept of being, of existence, to solve problems. Computing is about using the concept of the presence or absence of charge to do many wonderful things.
March 30, 2011 — Railay is a tiny little beach town in Southern Thailand famous for its rock climbing.
I've been in Railay for two weeks.
When the weather is good, I'm outside rock climbing.
When the weather is bad, I'm inside programming.
Naturally I've found myself comparing the two.
Specifically I've been thinking about what I can take away from my rock climbing experience and apply to my programming education.
Here's what I've come up with.
1. You should always be pushing yourself. Each day spent climbing I've made it to a slightly higher level than the previous day. The lazy part of me has then wanted to just spend one day enjoying this new level without pushing myself further. Luckily I've had a great climbing partner who's refused that and has forced me to reach for the next level each day. In both rock climbing and programming you should always be reaching for that new level. It's not easy, you have to risk a fall to reach a new height, but it's necessary if you want to become good. In programming, just like in climbing, you should be tagging along with the climbers at levels above you. That's how you get great. Of course, don't forget to enjoy the moment too.
2. Really push yourself. In rock climbing you sometimes have these points where you're scared--no, where you're fucking petrified--that you're going to fall and get hurt or die and you're hanging on to the rock for dear life, pouring sweat, and you've got to overcome it. In programming you should seek out moments like these. It will never be that extreme of course, but you should find those spots where you are afraid of falling and push yourself to conquer them. It might be a project whose scope is way beyond anything you've attempted before, or a task that requires advanced math, or a language that scares the crap out of you. My climbing instructor here was this Thai guy named Nu. He's the second best speed climber in Thailand and has been climbing for fifteen years. The other day I was walking by a climbing area and saw Nu banging his chest and yelling at the top of his lungs. I asked a bystander what was going on and he told me that Nu was struggling with the crux of a route and was psyching himself up to overcome it. That's why he's a master climber. Because he's been climbing for over fifteen years and he's still seeking out those challenges that scare him.
3. There's always a next level. In rock climbing you have clearly defined levels of difficulty that you progress through such as 5 to 8+ or top rope to lead+. In programming the levels are less defined and span a much wider range but surely exist. You progress from writing "hello world" to writing compilers and from using notepad to using vim or textmate or powerful IDEs. You might start out writing a playlist generator and ten years later you may be writing a program that can generate actual symphonies, but there still will be levels to climb.
4. Climbing or programming without teachers is very inefficient. There are plenty of books on rock climbing. But there's no substitute for great teachers. You can copy what you see in books and oftentimes you'll get many parts right, but a teacher is great for pointing out what you're doing wrong. Oftentimes you just can't tell what the key concepts and techniques to focus on are. You might not focus on something that's really important such as using mostly legs in climbing or not repeating yourself in programming. A good teacher can instantly see your mistakes and provide helpful feedback. Always seek out great teachers and mentors whether they be friends, coworkers, or professional educators.
5. You learn by doing; practice is key. Although you need teachers and books to tell you what to do, the only way to learn is to do it yourself, over and over. It takes a ton of time to master rock climbing or programming and although receiving instruction plays an important part, the vast majority of the time it takes to learn will be spent practicing.
6. Breadth, not only depth, is important. Sometimes to get to the next level in rock climbing you need to get outside of rock climbing. You may need to take up yoga to gain flexibility or weightlifting to gain strength. Likewise in programming sometimes you need to go sideways to go up. If you want to master Rails, you'll probably want to spend time outside of it and work on your command line and version control skills. Programming has a huge amount of silos. To go very deep in any one you have to gain competance in many.
7. People push the boundaries. Both rock climbing and programming were discovered by people and people are continually pushing the boundaries of both. In rock climbing advanced climbers are discovering new areas, bolting new routes, inventing new equipment, perfecting new techniques, and passing down new knowledge. Programming is the most cumulative of all human endeavors. It builds on the work of tens of millions of people and new "risk takers" are always constantly pushing the frontiers (today in areas like distributed computing, data mining, machine learning, parallel processing and mobile amongst others).
8. Embrace collaboration. The rock climbing culture is very collaborative much like the open source culture. Rock climbing is an inherently open source activity. Everything a climber does and uses is visible in the open. This leads to faster knowledge transfer and a safer activity. Likewise, IMO open source software leads to a better outcome for all.
9. Take pride in your work. In rock climbing when you're the first to ascend a route your name gets forever attached to that route. In programming you should be proud of your work and add your name to it. Sometimes I get embarrassed when I look at some old code of mine and realize how bad it is. But then I shrug it off because although it may be bad by my current standards, it represents my best honest effort at the time and so there's nothing to be ashamed of. I'm sure the world's greatest rock climbers have struggled with some easy routes in their day.
10. Natural gifts play a part. Some people who practiced for 5,000 hours will be worse than some people who practiced for only 2,000 hours due to genetics and other factors. It would be great if how good you were at something was determined totally by how many hours you've invested. But it's not. However, at the extremes, the number of hours of practice makes a huge difference. The absolute best climbers spend an enormous amount of time practicing. In the middle of the pack, a lot of the difference is just due to luck. I've worked with a wide range of programmers in my (short so far) career. I've worked with really smart ones and some average ones. Some work hard and others aren't so dedicated. The best by far though, possess both the intelligence and the dedication. And I'd probably rather work with the dedicated and average smarts over the brilliant but lazy.
Notes
- Rock climbing and programming are great complements because rock climbing seems to erase any bad effects on your hands that typing all day can cause.
- I'm a terrible rock climber and only a decent programmer. Take all my advice with a grain of salt.
Related Posts
March 5, 2011 — A good friend passed along some business advice to me a few months ago. "Look for a line," he said. Basically, if you see a line out the door at McDonald's, start Burger King. Lines are everywhere and are dead giveaways for good business ideas and good businesses.
Let's use Groupon as a case study for the importance of lines. Groupon scoured Yelp for the best businesses in its cities--the businesses that had virtual lines of people writing positive reviews--and created huge lines for these businesses with their discounts. Other entrepreneurs saw the number of people lining up to purchase things from Groupon and created a huge line of clones. Investors saw other investors lining up to buy Groupon stock and hopped in line as well. Business is all about lines.
In every country we travel to I look around for lines. It's a dead giveaway for finding good places to eat, fun things to do, amazing sites to see. If you want to start a business, look for lines and either create a clone or create an innovation that can steal customers from that line. If you see tons of people lining up to take taxis, start a taxi company. Better yet, start a bus.
Creating Lines
Succeeding in business is all about creating lines. Apple creates lines of reporters looking to write about their next big product. Customers line up outside their doors to buy their next big product. Investors line up to pump money into AAPL. Designers and engineers line up to work there.
If you are the CEO of a company, your job is simply to create lines. You want customers lining up for your product, investors lining up to invest, recruits lining up to apply for jobs. It's very easy to measure how you're doing. If you look around and don't see any lines, you gotta pick it up.
March 4, 2011 — I haven't written in a long while because i'm currently on a long trip around the world. at the moment, we're in indonesia. one thing that really surprised me was that despite our best efforts to do as little planning as possible, we were in fact almost overprepared. i've realized you can do an around the world trip with literally zero planning and be perfectly fine. you can literally hop on a plane with nothing more than a passport, license, credit card, and the clothes on your back and worry about the rest later. i think a lot of people don't make a journey like this because they're intimidated not by the trip itself, but by the planning for the trip. i'm here to say you don't need to plan at all to travel the world (alas, would be a lot harder if you were not born in a first world country, unfortunately). here's my guide for anyone that might want to attempt to do so. every step is highlighted in bold. adjust accordingly for your specific needs and desires.
The plan (see below for bullet points)
Set a savings goal. you'll need money to travel around the world, and the more money you have, the easier, longer, and more fun your journey will be.
Save, save, save. make sure you save enough so that when your trip ends you won't come home broke. $12,000 would be a large enough amount to travel for a long time and still come back with money to get you resettled easily.
Once you've saved half of your goal, buy your first one way plane ticket to a cheap, tourist friendly country. bali, indonesia or bangkok, thailand would be terrific first stops, amongst others. next, get a paypal account with a paypal debit card. this card gives you 1.5% cash back on all purchases, only charges a $1 atm fee, and charges no foreign transaction fees at all. the 1.5% cash back more than offsets the 1% fee Mastercard charges for interchange fees. if you don't have them already, get a drivers license and a passport with at least 1 year left before expiration. get a free google voice number so people can still SMS and leave you voicemails without paying a monthly cell phone bill. if you need glasses, contacts, prescription medication, or other custom things, stock up on those.
Settle your affairs at home--housing, job, etc. now, your planning is DONE! you have everything you need to embark on a trip around the world.
Get on the plane with your passport, license, paypal debit card, and $100 US Cash. you don't need anything else--not even a backpack! you'll pick up all that later.
Once you've arrived in bali (or another similar locale), go to a large, cheap shopping district(kuta square in bali for example). if you arrived late, find a cheap place to crash first and hit the market first thing in the morning. look for backpackers at the airport or ask someone who works there for cheap accommodation recommendations.
Once you're at the market, you've got a lot to buy. visit an ATM to take money out of your PayPal account in the local currency. if you want, space out your purchases over a few days. you'll want to buy a lonely planet/rough guides for your current country, a solid backpack (get a good one), bug spray with deet, sun tan lotion, a toothbrush, toothpaste, deodorant, nail clippers, tweezers, a swiss army knife, pepto bismol, tylenol, band aids, neosporin, bathing suit, some clothes for the current weather, shoes/flip flops, a cheap cell phone and SIM card, a netbook, a power adapter, and a camera and memory card. you now have pretty much everything you need for your trip and you probably spent less than half of what you would have had to spend in the states. you may want some other things like a sleeping bag, tent, portable stove, goggles, etc., depending on what you want to do on your trip.
Now, talk to locals and other travelers for travel recommendations. that plus your lonely planet and maybe some google searching and you'll have all the tools you need to plan where to go, what to do and what to eat.
Hit up an internet cafe to email and print a copy of your drivers license, passport, and credit card. it will be dirt cheap. get some passport photos made for countries that require a photo for visas. then sign up for skype and facebook (if you're the one person in the world who hasn't done this yet) to make cheap phone calls and keep in touch with family and friends.
Plan your trip one country at a time. every few days, check flight prices for the next few legs of your trip. you can sometimes get amazingly cheap deals if you check prices frequently and are flexible about when and where you fly. use sites like kayak, adioso, hotels.com, airbnb, and hostelworld to find cheap flights and places to stay, especially in expensive countries. in cheap countries, lonely planet and simply asking around often works great for finding great value hotels. also in expensive cities, find the local groupon clones and check them often for great excursion and meal deals. finally, you might want to get travel insurance from a site like world nomads.
That's it. enjoy your trip!
Bullet point format
- set a savings goal.
- save, save, save.
- buy your first one way plane ticket to a cheap, tourist friendly country.
- get a paypal account with a paypal debit card.
- get a drivers license and a passport with at least 1 year left before expiration.
- get a free google voice number.
- settle your affairs at home--housing, job, etc.
- get on the plane with your passport, license, paypal debit card, and $100 US Cash.
- go to a large, cheap shopping district.
- visit an ATM.
- buy a lonely planet for your current country, a solid backpack (get a good one), bug spray with deet, sun tan lotion, a toothbrush, toothpaste, deodorant, nail clippers, tweezers, a swiss army knife, pepto bismol, tylenol, band aids, neosporin, bathing suit, some clothes for the current weather, shoes/flip flops, a cheap cell phone and SIM card, a netbook, a power adapter, and a camera and memory card.
- talk to locals and other travelers for travel recommendations.
- hit up an internet cafe to email and print a copy of your drivers license, passport, and credit card.
- get some passport photos made for countries that require a photo for visas.
- sign up for skype and facebook.
- plan your trip one country at a time.
- check flight prices for the next few legs of your trip.
- find the local groupon clones and check them often for great excursion and meal deals.
September 18, 2010 — I was an Economics major in college but in hindsight I don't like the way it was taught. I came away with an academic, unrealistic view of the economy. If I had to teach economics I would try to explain it in a more realistic, practical manner.
I think there are two big concepts that if you understand, you'll have a better grasp of the economy than most people.
The first idea is that the economy has a pulse and its been beating for thousands of years. The second is that the economy is like a brain and if you visualize it in that way you can make better decisions depending on your goals.
In Media Res
Thousands of years ago people were trading goods and service, knitting clothes, and growing crops. The economy slowly came to life probably around 20 or 15 thousand years ago and it's never stopped. Although countless kingdoms, countries, industries, companies, families, workers, owners, have come and gone, this giant invisible thing called the economy has kept on trucking.
And not much has changed.
Certainly in 2,000 B.C. there was a lot more bartering and a lot less Visa, but most of the concepts that describe today's economy are the same as back then. You had industries and specialization, rich and poor, goods and services, marketplaces and trade routes, taxes and government spending, debts and investments.
Today, the economy is more connected. It covers more of the globe. But it's still the same economy that came to life thousands of years ago. It's just grown up a bit.
What are the implications of this? I think the main thing to take away from this idea is that we live in a pretty cool time where the economy has matured for thousands of years. It has a lot to offer if we understand what it is and how to use it. Which brings me to my next point.
The economy is like a brain.
The second big idea I try to keep in mind about the economy is that it's like a neural network. It's really hard to form a model of what the economy really looks like, but I think a great analogy is the human brain.
At a microscopic level, the brain is composed of around 100 billion neurons. The economy is currently composed of around 8 billion humans.
The average neuron is directly connected to 1,000 other neurons via synapses. Some neurons have more connections, some have less. The average human is directly connected to 200 other humans in their daily economic dealings. Some more, some less.
Neurons and synapses are not distributed evenly in the brain. Some are in relatively central connections, some are on the periphery. Likewise, some humans operate in critical parts of the economy(London or Japan for example), while many live in the periphery(Driggs, Idaho or Afghanistan, for example).
If we run with this analogy that the economy is like the human brain, what can we take home from that?
For people that want a high paying job
If you want a high paying job then you should think carefully about where you plug yourself into the network/economy. You want to plug yourself in where there's a lot of action. You want to plug yourself into a "nerve center". These nerve centers can be certain geographies, certain industries, certain companies, etc. For instance, plugging yourself into an investment banking job on Wall Street will bring you more money than teaching surfing in Maui. Now, if you're born in the periphery, like a third world nation, you might be SOL. It's tremendously easier to plug yourself into a nerve center if you're born in the right place at the right time.
If you don't care much for money there are plenty of peripheries
Now if you don't want a high paying job there are more choices available to you. Most of the economy is not a nerve center. It's also a lot easier to move from a high paying spot in the economic brain to a place in a lower paying spot.
Starting a business you've got to inject yourself into it.
When you start a business, you're basically a neuron with no synapses living outside the brain. You've got to inject yourself into the brain and build as many synapses as possible. When you start a business, the brain("the economy"), doesn't give a shit about you. You've got to plug yourself in and make yourself needed. You've got to get other neurons(people/companies/governments) to depend on you. You can do this through a combination of hard work, great products/services, great sales, etc.
Now one thing I find interesting is that a lot of people say entrepreneurs are rebels. This is sort of true, however, for a business to be successful the business has to conform a lot for the economy to build connections to it. If you want to be a nerve center, you've got to make it easy for other parts of the economy to connect to you. You can't be so different that you are incompatible with the rest of the economy. If you want to be a complete rebel, you can do that on the periphery, but you won't become a big company/nerve center.
If you're an existing business, it's hard to get dislodged.
Once you are "injected" into the economy, it's hard to get dislodged. If a lot of neurons have a lot of synapses connected to you, those will only die slowly. For a long time business will flow through you. This explains why a company like AOL can still make a fortune.
In conclusion
In conclusion, the economy is a tremendous creature that can provide you with a lot if you plug yourself in. It's been growing for thousands of years and has a lot to offer. You can also to choose to stay largely unplugged from it, and that's okay too.
August 25, 2010 — I've been very surprised to discover how unpredictable the future is. As you try to predict farther out, your error margins grow exponentially bigger until you're "predicting" nothing specific at all.
Apparently this is because many things in our world are "chaotic". Small errors in your predictions get compounded over time. 10 day weather forecasts are notoriously inaccurate despite the fact that teams of the highest IQ'd people on earth have been working on them for years. I don't understand the math behind chaos but I believe in the basic ideas.
A Simple Example
I can correctly predict whether or not I'll work out tomorrow with about 85% accuracy. All I need to do is look at whether I worked out today and whether I worked out yesterday. If I worked out those 2 days, odds are about 90% I will work out tomorrow. If I worked out yesterday but didn't work out today, odds are about 40% I will work out tomorrow. If I worked out neither of those two days, odds are about 20% I'll work out tomorrow.
However, I can't predict with much accuracy whether or not I'll work out 30 days from now. That's because the biggest two factors depend on whether I work out 29 days from now and 28 days from now. And whether I work out 29 days from now depends on the previous 2 days the most. If I'm wrong in my predictions about tomorrow, that error will compound and throw me off. It's hard to make an accurate prediction about something so simple. Imagine how hard it is to make a prediction about a non-binary quantity.
Things You Can't Predict
Weather, the stock market, individual stock prices, the next popular website, startup success, box office hits, etc. Basically dynamic, complex systems are completely resistant to predictions.
On Model verse Off Model
When making predictions you generally build a model--consciously or unconsciously. For instance, in predicting my future workouts I can make a spreadsheet (or just a "mental spreadsheet") where I come up with some inputs that are used to predict the future workout. My inputs might be whether I worked out today and whether it will rain. These are the "on model" factors. But all models leave things out that may or may not affect the outcome. For example, it could be sunny tomorrow and I could have worked out today, so my model would predict a workout tomorrow. But then I might get injured on my way to the gym--an "off model" risk that I hadn't taken into account.
Avoid Making Predictions & Run From People Pushing Predictions
The world is complex and impossible to predict accurately. But people don't get this. They think the world is easier to explain and predict than it really is. And so they demand predictions. And so people provide them, even though these explanations and predictions are bogus. Feel free to make or listen to long term predictions for entertainment, but don't believe any long term predictions you hear. We're a long way(possibility an infinitely long way) from making accurate predictions about the long run.
Inside Information
What if you have inside information? Should you then be able to make better predictions than others? Let's imagine for a moment that you were alive in 1945 and you were trying to predict when WWII would end. If you were like 99.99999+% of the population, you would have absolutely no idea that a new type of bomb was just invented and about to be put to use. But if you were one of the few who knew about the bomb, you might have been a lot more confident that the war was close to an end. Inside information gives you a big advantage in predicting the future. If you have information and can legally "bet on that", go for it. However, even the most connected people only have the inside scoop on a handful of topics, and even if you know something other people don't it's very hard to predict the scale (or direction) of an event's effect.
Be Conservative
My general advice is to be ultra conservative about the future and ultra bullish on the present. Plan and prepare for the worst of days--but without a pessimistic attitude. Enjoy today and make safe investments for tomorrow.
August 25, 2010 — Ruby is an awesome language. I've come to the conclusion that I enjoy it more than Python for the simple reason that whitespace doesn't matter.
Python is a great language too, and I have more experience with it, and the whitespace thing is a silly gripe. But I've reached a peak with PHP and am looking to master something new. Ruby it is.
August 25, 2010 — Doctors used to recommend leeches to cure a whole variety of illnesses. That seems laughable today. But I think our recommendations today will be laughable to people in the future.
Recommendations work terrible for everyone but decently on average.
We are a long, long way from making good individual recommendations. You won't get good individual recommendations until your individual genome is taken into account. And even then it will take a while. We may never get to the point where we can make good individual recommendations.
So many cures and medicines work for a certain percentage of people, but for some people they can have detrimental or even fatal effects. People rave about certain foods, exercises, and so forth, without considering how differences in genetics can have a huge role.
People are quite similar, but they are also quite different and react to different things in different ways. I think we are a long way away from seeing breakthroughs in recommendations.
Recommendations are great business, but I think we're 2 or 3 orders of magnitude away from where they could be, and it could take decades(or never) to reach those levels.
August 25, 2010 — Genetics, aka nature, plays the dominant role in predicting most aspects of your life, in my estimation.
Across every dimension in life your genes are both a glass ceiling--preventing you from reaching certain heights--and a cement foundation--making it unlikely you'll hit certain lows. How tall/short you will be, how smart/dumb you will be, how mean/nice you will be, how popular/lonely you will be, how athletic/clumsy, how fat/skinny, how talkative/quiet, how long/short you'll live, and so forth.
By the time you are born, your genes, place of birth, year of birth, parents--they're all set in stone, and the constraints on your life are largely in place. That's an interesting thought.
Nurture plays a huge role in making you, of course. Being born with great genes is irrelevant if you are malnourished, don't get early education, etc. But nurture cannot overcome nature. Our DNA is not at all malleable and no one knows if it ever will be. Nonetheless, it makes no sense to complain about nature. It is up to you to make the most of your starting hand. On the other hand, let us not be quick to judge others. I make that mistake a lot.
I think the bio/genome field will be the most interesting industry come 2025 or so.
August 25, 2010 — Maybe I'm getting old, but I'm starting to think the best way to "change the world" isn't to bust your ass building companies, inventing new machines, running for office, promoting ideas, etc., but to simply raise good kids. Even if you are a genius and can invent amazing things, by raising a few good kids their output combined can easily top yours. Nerdy version: you are a single core cpu and can't match the output of a multicore machine.
I'm not saying I want to have kids anytime soon. I'm just realizing after spending time with my family over on Cape Cod, that even my dad, who is a harder worker than anyone I've ever met and has made a profound impact with his work, can't compete with the output of 4 people (and their potential offspring), even if they each work only 1/3 as hard, which is probably around what we each do. It's simple math.
So the trick to making a difference is to sometimes slow down, spend time raising good kids, and delegate some of the world saving to them.
August 25, 2010 — I've been working on a fun side project of categorizing things into Mediocristan or Extremistan(inspired by NNT's book The Black Swan).
I'm trying to figure out where intelligence belongs. Bill Gates is a million times richer than many people; was Einstein a million times smarter than a lot of people? It seems highly unlikely. But how much smarter was he? Was he 1,000x smarter than the average joe? 100x smarter?
I'm not sure. The brain is a complex thing and I haven't figure out how to think about intelligence yet.
Would love to hear what other people think. Shoot me an email!
August 25, 2010 — I have a feeling critical thinking gets the least amount of brain's resources. The trick is to critically think about things, come to conclusions, and turn those conclusions into habits. The subconcious, habitual mind is much more powerful than the tiny little conscious, critically thinking mind.
If you're constantly using the critical thinking part of your mind, you're not using the bulk of your mind. You're probably accomplishing a lot less than you could be.
Come to conclusions and build good habits. Let your auto pilot take over. Then occasionally come back and revisit your conclusions.
August 25, 2010 — Warren Buffet claims to follow an investment strategy of staying within his "circle of competence". That's why he doesn't invest in high tech--it's outside his circle.
I think this is good advice. The tricky part is to figure out where to draw the circle.
Here are my initial thoughts:
- Start with a small circle. Be conservative about where you draw the circle.
- Do what you're good at as opposed to what you want to do. Our economy rewards specialization. You want to work on interesting problems, but it pays better to work on things you've done before. Use that money to explore the things you want to do.
- Be a big fish in a small circle.
- Spend time outside your circle, but expand it slowly. Definitely work hard to improve your skill set but don't overreach. It's better to have a solid core and build momentum from that than to be marginal in a lot of areas.
August 23, 2010 — Note: Sometimes I'll write a post about something I don't understand at all. I am not a neuroscientist and have only the faintest understanding of the brain so this is one of those times. Reading this post could make you dumber. But occasionally writing from ignorance leads to good things--like the time I wrote about Linear Algebra and got a number of helpful emails better explaining the subject to me.
My question is: how are the brain's resources allocated for its different tasks?
In a restaurant the majority of the workers are involved with serving, then a smaller number of employees are involved with cooking, and still a smaller number of people are involved with managing.
The brain has a number of functions: vision, auditory, speech, mathematics, locomotion, and so forth. Which function uses the most resources? Which function uses the least?
I have no idea, but my guess is below.
- Vision. My guess is vision uses more than 50% of the brain.
- Memory. Perhaps 50% or more of the brain is involved with storing memories of sights, sounds, smells, etc.
- Locomotion. Movement probably touches between 20-60% of the brain.
- Auditory/Speech. I guess that between 20-40% of the brain is involved with this.
- Taste/touch/smell. My guess is between 10-20%.
- Emotion. My guess is 10-15% is involved with setting/controlling emotion.
- Long term planning/mathematics. I think the ability to do complex thinking is given the least resources.
I'm probably quite far off, but I thought it was an interesting question to think about. Now I'll go see if I can dig up some truer numbers.
August 23, 2010 — Your most recent experiences effect you the most. Reading this essay will effect you the most today but a week from now the effect will have largely worn off.
Experiences have a half-life. The effect decays over time. You might watch Almost Famous, run out to buy a drumset, start a band, and then a month later those drums could be gathering dust in your basement. You might read Shakespeare and start talking more lyrically for a week.
Newer experiences drown out old ones. You might be a seasoned Rubyist and then read an essay espousing Python and suddenly you become a Pythonista.
All genres of experiences exhibit the recency effect. Reading books, watching movies, listening to music, talking with friends, sitting in a lecture--all of these events can momentarily inspire us, influence our opinions and understanding of the world, and alter our behaviors.
Taking Advantage of the Recency Effect
If you believe in the recency effect you can see the potential benefit of superstitious behavior. For instance, I watched "The Greatest Game Ever Played", a movie about golf, and honest to god my game improved by 5 strokes the next day. A year later when I was a bit rusty, I watched it again and the effect was similar(though not as profound). When I want to write solid code, I'll read some quality code first for the recency effect.
If you want to do great work, set up an inspiring experience before you begin. It's like taking a vitamin for the mind.
Some More Examples
- Settlers of Cataan can make you an astute businessman after a few games. You'll find yourself negotiating everything and saving/making money left and right.
- Influence by Cialdini will give you a momentary force field against the tricks of pushy salespeople and also temporarily boost your own ability to get people to do what you want.
- Watching Jersey Shore will temporarily make you feel much better about your life while at the same time altering your vocabulary with phrases like "You do you" and "GTL".
August 11, 2010 — I've had some free time the past two weeks to work on a few random ideas I've had.
They all largely involve probability/statistics and have no practical or monetary purpose. If I was a painter and not a programmer you might call them "art projects".
One project deals with categorizing data into "Extremistan" and "Mediocristan". Taleb's books, the Black Swan and Fooled by Randomness, list a number of different examples for each, and I thought it would be interesting to extend that categorization further.
The second project I'll expand on a bit more here.
TheOvarianLottery.com
Warren Buffett coined the idea of the "ovarian lottery"--his basic idea is that the most important factor in determining how you end up in life is your birth. You either are born "lucky"--in a rich country, with no major diseases, to an affluent member of society, etc.--or you aren't. Other factors like hard work, education, smart decision making and so forth have a role, but play a relatively tiny role in determining what your life will be like.
I thought this was a very interesting idea and so I started a program that lets you be "born again" and see how things turn out. When you click "Play", theOvarianLottery will show you:
- What year you were born in(or you can choose this yourself)
- What continent/country you were born in
- What your gender is
- How old you will be when you die
- Your Religion
- Silly things like whether you will ever be a Facebook user (with 500 million users potentially 1 in every 200 people that has ever lived has used Facebook!)
Two Surprises
I've encountered two major surprises with the theOvarianLottery.
First, I thought theOvarianLottery would take me an hour or two. I was wrong. It turns out the coding isn't hard at all--the tricky part is finding the statistics. Not a whole lot of countries provide detailed statistics on their current populations. Once you start looking up stats for human population before 1950, the search gets an order of magnitude harder. (I've listed a few good sources and resources at the bottom of this post if anyone's interested)
Second, I've found so many fascinating diversions while working on this. I've encountered cool stats like:
- Estimates on the total number of births that have happened so far range from 40 - 150 billion. This doesn't include species prior to homo sapiens.
- Around 1 in 5 births today happens in China. Odds of being born in the U.S. are around 4%.
- Potentially around 40% of all babies that have ever been born have died before the age of 1. Nowadays the infant mortality rate is around 2% (and less in many countries).
But cooler than interesting descriptive statistics are the philosophical questions that this idea of the Ovarian Lottery raises. If I was a philosopher I might ponder these questions at depth and write more about each one, but I don't think that's a great use of time and so I'll just list them. Philosophy is most often a fruitless exercise.
How does the real Ovarian Lottery work?
My site is just a computer program. It's interesting to think about how the real ovarian lottery works. Is there a place where everyone is hanging out, and then you spin a wheel and your "soul" is magically transported to a newborn somewhere in the world?
What if the multiverse theory is correct?
If the multiverse theory is correct, then my odds are almost certainly off. In other words, theOvarianLottery assumes there's only 1 universe and extrapolates the odds from that. If there are dozens or infinite universes, who knows what the real odds are.
What role has chaos played in the development of humanity?
If you go back to around 10,000 B.C., somewhere around 2-10 million people roamed the planet. Go back earlier and the number is even smaller. It's interesting to think of how small differences in events back then would have created radically different outcomes today. I've dabbled a bit into chaos theory and find it quite humbling.
What does the fact that we are alive today tell us about the future?
Depending on the estimate, between 4-20% of all humans that have ever lived are alive today. In other words, the odds of you being alive right now (according to my model) are higher than they've ever been. The odds of you being alive in 10,000 BC are over 1,000 times less. If humans indeed go on to live for another ten thousand years and the population grows another 1,000 times the odds of you being born today would be vastly smaller. In other words, if my model represented reality than we could conclude that odds are high that the human population does not continue growing like it has.
What's the future shape of the population curve?
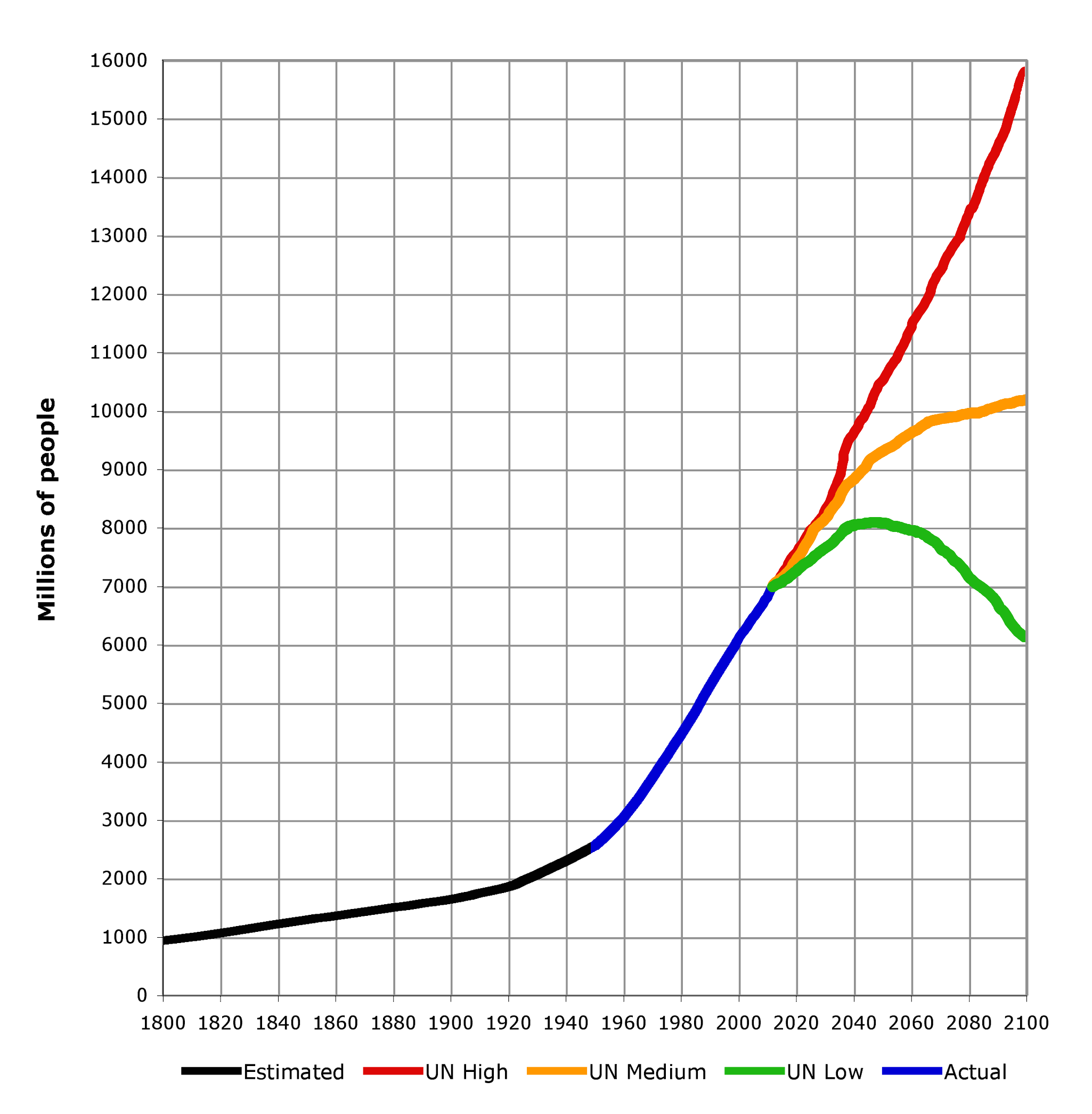
The growth of human population has followed an exponential curve. How long will it last? Will earth become overpopulated? Will we invent technology to leave earth? Will human population decline? Human population growth is hard to predict over any long term time period.
Complete Uselessness of This Model
I don't believe you can take the concept of the Ovarian Lottery any more seriously than you can take religion. It provides food for thought, but it doesn't provide any real answers to much. The stats though could certainly be used in debates.
Oh well. Ars gratia artis
Notes
I hope to finish up theOvarianLottery and slap a frontend on it sometime in the future.
Helpful Links for Population Statistics(beyond wikipedia):
August 6, 2010 — Figuring out what you want in life is very hard. No one tells you exactly what you want. You have to figure it out on your own.
When you're young, it doesn't really matter what you want because your parents choose what you do. This is a good thing, otherwise kids would grow up uneducated and malnourished from ice cream breakfasts. But when you grow up, you get to call the shots.
You Need Data to Figure Out What You Want
The big problem with calling the shots is that what your conscious, narrative mind thinks you want and what your subconscious mind really wants often differ quite a lot. For instance, growing up I said I wanted to be in politics, but in reality I always found myself tinkering with computers. Eventually you have the "aha" moment, and drop things you thought you wanted and focus on the things that you really want, the things you keep coming back to.
If you pay attention to what you keep drifting back to, you'll figure out what you want. You just have to pay attention.
Collect data on what makes you happy as you go. Run experiments with your life.
You don't have to log what you do each day and run statistics on your life. But you do have to get out there and create the data. Try different things. Try different jobs, try different activities, try living in different places. Then you'll have experiences--data--which you can use to figure out exactly what the hell it is you really want.
You Want More Than You Think
People like to simplify things as much as possible. It would be nice if you only wanted a few things, such as a good family, a good job, and food on the table. I think though that in reality we each want somewhere around 10 to 20 different things. On my list of things I want, I've got 15 or 16 different things. Family, money, and food are on there. But also some more specific things, like living in the San Francisco Bay area, and studying computer science and statistics.
Being Happy is About Balancing All of These Things
You don't get unlimited hours in the day so you've got to budget your time amongst all of these things that you want. If I were to spend all of my time programming, I'd have no time for friends and family, which are two things really important to me. So I've got to split my energies between these things. You'll always find yourself neglecting at least one area. Life is a juggling act. The important thing is to juggle with the right balls. It's fine to drop a ball for a bit, just pick it back up and keep going.
Limit the Bad Stuff
As you grow up you'll learn that there are things you want that aren't so good for you. Don't pretend you don't want that, just try to minimize it. For instance, part of me wants to eat ice cream almost everyday. But part of me wants to have healthy teeth, and part of me wants to not be obese. You've got to strike a balance.
Your Wants Change
First, you've got to figure out all the different things you want. Then, you've got to juggle these things as best as possible. Finally, when you think you've got it figured out, you'll realize that your wants have changed slightly. You might want one thing a bit less (say, partying), while wanting something else more (a career, a family, learning to sail, who knows). That's totally normal. Just add or drop the new discovery to your list and keep going.
Make a Mindmap
Almost 2 years ago I made a dead simple mindmap of what I wanted. I think a mindmap is better than a list in this case because A) it looks cooler and B) there's not really a particular ranking with what I want. My list has changed by just one or two things in 2 year's time.
I like to be mysterious and have something to talk about at parties, so I've gone ahead and erased most of the items, but you can get the idea:
If you don't know what it is you want, try making a mindmap.
August 6, 2010 — In February I celebrated my 26th Orbit. I am 26 orbits old. How many orbits are you?
I think we should use the word "orbit" instead of year. It's less abstract. The earth's 584 million mile journey around the sun is an amazing phenomena, and calling it merely "another year" doesn't do it justice.
Calling years orbits also makes life sound more like a carnival ride--you get a certain number of orbits and then you get off.
Enjoy the ride!
Notes
- Neat fact: The sun completes a revolution around the center of the Milky Way galaxy once every 250 million years. It is estimated to have completed 25 orbits during the lifetime of our Sun, and less than one orbit since the origin of humans.
- My roommate Andrew suggests the reason why we don't refer to a year as an orbit is perhaps because when we started calling things years, we didn't yet know that the earth revolved around the sun. Bad habits die hard.
- I think the orbit around the sun has more impact on our world than we even realize. In other words, seasonality's affects are underestimated. Perhaps when you give something a name it seems less threatening. We call the change from August to December "fall", and thus we underestimate the volatility and massive change that occurs all around us.
- We should also call days "revs". Okay I'm done.
August 6, 2010 — Three unexpected things have happened to me during my two years of entrepreneurial pursuits in California.
First, I have not gotten rich.
Second, I have met many people who have gotten rich. I've even had the pleasure to witness some of my friends get rich.
Third, I've yet to meet someone much happier than me.
I've met a large amount of people who are 6, 7, even 8 orders of magnitude richer than me and yet not a single one of them was even close to an order of magnitude happier than me.
The explanation, I finally realized, is simple.
Happiness is a physical quantity, like Height or Weight
Happiness, as NNT would say, resides in Mediocristan. Happiness is a physical condition and just as it is impossible to find someone 60 feet tall, it is impossible to find someone ten times happier than everyone else. I could sit next to you and drink 3 cups of coffee, and sure, I might be 20% happier than you for about 20 minutes, but 1,000% happier? Not even close.
Our happiness is a result of some physical processes going on in our brains. While we don't understand yet the details of what's happening, from observation you can see that people only differ in happiness about as much as they differ in weight.
Millionaire Entrepreneurs Do Not Leap Out of Bed Every Morning
This idea of happiness being distributed rather equally might not be surprising to people with common sense. There are a million adages that say the same thing. Thinking about it mathematically took me by surprise, however.
I was rereading the Black Swan at the same time I was reading Zappos founder Tony Hsieh's "Delivering Happiness". In his autobiography, Tony talks about how he wasn't much happier after selling his first company for a 9 figure sum. I thought about this for a bit and realized I wasn't suprised. I've read the same thing and even witnessed it happen over and over again amongst startup founders who strike it rich. The change in happiness doesn't reflect the change in the bank account. Not at all! The bank account undergoes a multi-order of magnitude shift, while the happiness level fluctuates a few percentage points at best. It dawned on me that happiness is in Mediocristan. Of course!
Don't, Don't Stress Over Getting Rich
I'm not warning you that you might not become an order of magnitude happier if you become rich, I'm telling you IT'S PHYSICALLY IMPOSSIBLE!!! There's no chance of it happening. You can be nearly as happy today as you will be the week after you make $1 billion. (In rare cases, you might even be less happy after you strike it rich.) Money is great, and having a ton of it would be pretty fun. By all means, try to make a lot of it. You will most likely be at least a few percentage points happier. Just remember to keep it in a realistic perspective. Aim to be 5 or 10% happier, not 500% happier.
It's funny, although our society doles out vastly different rewards, at the end of the day, in what matters the most, mother nature has created a pretty equal playing field.
August 3, 2010 — Last night over dinner we had an interesting conversation about why we care about celebrities. Here's my thinking on the matter.
Celebrities are not that special
If you look at some stats about the attributes of celebrities, you'll realize something interesting: they're not that special. By any physical measure--height, weight, facial symmetry, body shape, voice quality, personality, intelligence--celebrities are not much different from the people around you. Conan O'Brien might be a bit funnier than your funniest friend, but he wouldn't make you laugh 10x more; it'd be more like 5% more. Angelina Jolie might be 10% more attractive than your most attractive friend, but for some groups she could even be less attractive.
If these people aren't so special, why do they interest us so much? One explanation is that we see these people over and over again on television and as a result we are conditioned to care about them.
I concede this may be part of it, but I actually don't think celebrities are forced upon us. Instead, I think we need celebrities. We need them to function in a global society.
It's all because of the Do You Know Game.
The Do You Know Game
The Do You Know Game is a popular party game. People often play it every time they meet a stranger. It goes something like this:
That's the basic premise. You ask me where I am from. You think of everyone you know from that place and ask me one by one if I know that person. Then we switch roles and play again.
People play this game at work, at parties, at networking events, at college--especially at college. This game has a benefit.
The Do You Know Games Lets Strangers Build Trust
People play this game for many reasons, but certainly one incentive to play is that if two strangers can identify a mutual friend, they can instantly trust each other a bit more. If we have a mutual friend, I'm more likely to do you a favor, and less likely to screw you over, because word gets around. Back in the day when people carried swords, this was even more important.
A mutual friend also gives two strangers a shared interest. It's something that they can continually talk about.
And having a mutual friend can reveal a lot about a person:
As you can see, having mutual friends serves many purposes.
The Do You Know Game has gotten harder as the world has globalized
Throughout the 20th century, the proportion of people that have traveled far from their hometowns for school or career has steadily increased. The further you travel from your home, the less likely you are to have a successful round of "do you know" with a stranger. You might share common interests or values with the new people you meet, but you'll know none of the same people and thus it will be harder to build and grow relationships. This is a big problem for a globalized society that depends on strong ties between people from different places to keep the economy running smoothly.
Celebrities to the Rescue
Celebrities have naturally arisen to fill a need for strangers in a globalized world to have mutual friends. We all interact with strangers more frequently nowadays, and if we didn't have celebrities, there would be a gaping hole in our arsenal of shortcuts to establishing trust with new people. There are a thousand ways to build repoire with a stranger, but the technique of talking about a shared acquaintance is one of the easiest and most effective. We travel farther than we ever have, but thanks to celebrities, we still have dozens of "mutual friends" wherever we go.
Of course, just because two people know who Tom Hanks is doesn't mean they should trust each other more. Tom Hanks doesn't know them and so none of the "word gets around" stuff I mentioned earlier applies. I'm not arguing that celebrities are an equal substitute for a mutual friend by any means. A mutual friend is a much more powerful bond than knowing about the same celebrity.
But celebrities are better than nothing.
July 2, 2010 — A year ago I wrote a post titled The Truth about Web Design where I briefly argued that "design doesn't matter a whole lot."
My argument was: "you go to a website for the utility of it. Design is far secondary. There are plenty of prettier things to look at in the real world."
I do think the real world is a pretty place, but about design, I was completely wrong.
I now think design is incredibly important, and on par with engineering. I used to think a poorly designed product was a matter of a company setting the right priorities, now I think it reflects ignorance, laziness or mediocrity. If a company engineers a great product but fails to put forward a great design, it says:
- 1. The company doesn't feel that design is important.
- 2. The company was too lazy to put much effort into design.
- 3. The company's engineering team is incapable of working effectively with the design team.
Why Design is Important, In Princple
For nearly a decade I've always dreamed of my ideal computer as no computer at all. I wanted a computer smaller than the smallest smartphone, that would always be ready to take commands but would also be out of site. In other words, I've always thought of computers purely as problem solving tools--as a means to an end.
I want the computer to solve the problem and get out of my way. Computers are ugly. The world is beautiful. I like to look at other people, the sky, the ocean and not a menu or a screen. I didn't care about the style in which the computer solved my problem, because no matter how "great" it looked it couldn't compare to the natural beauty of the world.
I was wrong.
A computer, program, or product should always embody a good design, because the means to the end is nearly important as the end itself. True, when riding in a car I care about the end--getting to my destination. But why shouldn't we care about the style in which we ride? Why shouldn't we care about the means? After all, isn't living all about appreciating the means? We all know what the end of life is, the important thing is to live the means with style. I've realized that I want style--and I'm a little late to the party, most people want style.
Why Design is Important, In Practice
If that argument didn't make sense, there are a number of practical reasons why a great design is important.
A great design can unlock more value for the user. Dropbox overcomes herculean engineering challenges to work, but if it weren't for its simple, easy to use design it wouldn't be nearly as useful.
A great design can be the competitive edge in a competive market. Mint.com had a great design, and it bested a few other startups in that emerging market.
A great design can be the differentiator in a crowded market. Bing's design is better than Google's. The design of Bing differentiates the two search engines in my mind, and makes Bing more memorable to me. The results of Microsoft's search engine have always been decent, but it was the design of Bing that finally gave them a memorable place in consumers' minds.
A great design is easy to get people behind. People like to support sites and products that are designed well. People love to show off their Apple products. Airbnb's beautiful design had a large role in making it easy for people to support the fledgling site.
What to do if you aren't good at design
Personally, I'm a terrible designer. Like many hackers, I can program but I can't paint. What should we do?
First, learn to appreciate the importance of design.
Second, learn to work well with designers. Don't treat design as secondary to engineering. Instead, think of how you can be a better engineer to execute the vision of your design team.
Great engineering can't compensate for poor design just as great design can't compensate for poor engineering. To create great products, you need both. Don't be lazy when it comes to design. It could be the make or break difference between your product's success or failure.
Related Posts
Notes
- 1. Are Google, craigslist, and eBay exceptions to the rule that you need a great design to succeed? Yes. If you're the first mover in a market, you can get by with an ugly design. At least in the case of Google, they continually refine it.
June 28, 2010 — Competition and specialization are generally positive economics forces. What's interesting is that they are contradictory.
Competition. Company 1 and Company 2 both try to solve problem A. The competition will lead to a better outcome for the consumer.
Specialization. Company 1 focuses on problem A; Company 2 focuses on problem B. The specialization will lead to a better outcome for all because of phenomena like economies of scale and comparative advantage.
So which is better? Is it better to have everyone compete to solve a small number of problems or to have everyone specialize on a unique problem?
Well, you want both. If you have no competition, it's either because you've been able to create a nice monopolistic arrangement for yourself or it's because you're working on a problem no one cares about.
If you have tons of competition, you're probably working on a problem that people care about but that is hard to make a profit in.
Update 8/6/2010: Overspecialization can be bad as well when things don't go according to plan, as NNT points out, Mother Nature does not like overspecialization, as it limits evolution and weakens the animals. If Intel fell into a sinkhole, we'd be screwed if it weren't for having a backup in AMD.
June 17, 2010 — Doing a startup is surprisingly simple. You have to start by creating a product that people must have, then you scale it from there.
What percent of your customers or "users" would be disappointed if your product disappeared tomorrow? If it's less than 40%, you haven't built a must have yet.
As simple as this sounds, I've found it to be quite hard. It's not easy to build a must have.
Some Reasons Why Startups Fail to Build a Must Have
- Lack of ability. If you want to build a plane that people can't wait to fly on, you probably need to be an aerospace engineer. If you want to draw a comic that people can't wait to read, you probably need to be a talented artist and comedian to boot. You might have a great idea for a search engine, but if you don't have a PhD level understanding of math and computer science, your search engine is quite unlikely to become a must have when people have Google. You need a talented team in the product area to build a must have.
- Release too late. A lot of people take too long to release and get feedback. The odds of your first iteration being a must have are quite slim. People aren't going to get it like you get it. You'll need to iterate. If you burn up all your money and energy before releasing, you might not leave yourself with enough time to tweak your product until it's a must have. Give yourself ample time, release early.
- Lack of vision. It seems like successful entrepreneurs have a clear vision about what people will want ahead of time. There are endless directions in which you can take your product. Sometimes a product will get started in the right direction, but then will be tweaked into a dead end. I think you need a simple, clear, medium to long term vision for the product.
- Preoccupation with Unimportant Things. A lot of founders get bogged down with minor details like business plans or equity discussions or fundraising processes. If you don't put your focus almost entirely on creating a must have product, none of this stuff will matter. Your company needs a reason to exist, without a must have product, there isn't one. (Unless of course, you are trying to create a lifestyle business, in which your first priority is a good lifestyle, then by all means do things in which ever way you want).
- Too broad a focus. Every successful business starts with a small niche. You need to create a must have product for a few people before you can create one for a lot of people. If your business is a two sided marketplace, pick a very small market to start in, and grow it from there.
- Get tired of the space. This is a mistake I've made a lot. I've come up with a simple idea that I think is cool, I launch it, then when the going gets tough, I realize I'm not too interested in the space. No matter what the idea or space, there are going to be low moments when you don't have a growing, must have product, and if your passion isn't in that industry, you might not want to keep going. Pick a space that you think is cool; build a product that you want.
- Stubbornness. Sometimes people are too stubborn to realize that their product isn't something people want. If people don't care if it disappeared tomorrow, you need to improve it! Don't be stubborn. Listen to the numbers. Listen to feedback.
What are some other reasons people fail to build a must have product?
June 16, 2010 — Every Sunday night in college my fraternity would gather in the commons room for a "brother meeting". (Yes, I was in a fraternity, and yes I do regret that icing hadn't been invented yet). These meetings weren't really "productive", but we at least made a few decisions each week. The debates leading up to these decisions were quite fascinating. The questions would be retarded, like whether or not our next party should be "Pirate" themed or "Prisoner" themed(our fraternity was called Pike, so naturally(?) we were limited to themes that started with the letter P so we could call the party "Pike's of the Caribbean" or something). No matter what the issue, we would always have members make really passionate arguments for both sides.
The awesome thing was that these were very smart, persuasive guys. I'd change my mind a dozen times during these meetings. Without fail, whichever side spoke last would have convinced me that not only should we have a Pirate themed party, but that it was quite possibly one of the most important decisions we would ever make.
The thing I realized in these meetings is that flip flopping is quite easy to do. It can be really hard, if not impossible, to make the "right" decision. There are always at least two sides to every situation, and choosing a side is a lot more about the skills of the debaters, the mood you happen to be in, and the position of the moon(what I'm trying to say is there's a lot of variables at work).
I think humans are capable of believing almost anything. I think our convictions are largely arbitrary.
Try an experiment.
- Take an issue, a political issue--the war in Afghanistan, Global Warming, marijuana legalization--or a minor everyday issue--what to have for dinner tonight, whether it's better to drink coffee or not, whether Facebook is a good thing or bad thing.
- Take a stand on that issue. Think of all the reasons why your stand is right. Be prepared to support your stance in a debate.
- Completely change your position. Take the other side. Think of every reason why this new side is correct. Be prepared to support this side without feeling like you are lying.
- Keep flipping if you want.
I think it's fascinating to see how now matter what the issue, you can create a convincing case for any side. And it's hard not to hear an argument for the opposing side and not want to change your position. Our brains can be easily overloaded. The most recently presented information pushes out the old arguments.
But at some points, survival necessitates we take a side. The ability to become stubborn and closed-minded is definitely a beneficial trait. Survival causes us to become stubborn on issues and survival requires closed-mindedness to get anything done.
Three men set out to find a buried treasure. The first guy believes the treasure is to the north so heads in that direction. The second guy heads south. The third guy keeps changing his mind and zigzags between north and south. I don't know who finds the treasure first, but I do know it's certainly not the third guy.
Oftentimes the expected value of being stubborn is higher than the expected value of being thoughtful.
Is flip flopping a good thing? Is being open minded harder than being stubborn? Does it depend on the person? Does success require being certain?
I have no idea.
June 15, 2010 — I think it's interesting to ponder the value of information over it's lifetime.
Different types of data become outdated at different rates. A street map is probably mostly relevant 10 years later, while a 10 year old weather forecast is much less valuable.
Phone numbers probably last about 5 years nowadays. Email addresses could end up lasting decades. News is often largely irrelevant after a day. For a coupon site I worked on, the average life of a coupon seemed to be about 2 weeks.
If your data has a long half life, then you have time to build it up. Wikipedia articles are still valuable years later.
What information holds value the longest? What are the "twinkies" of the data world?
Books, it seems. We don't regularly read old weather forecasts, census rolls, or newspapers, but we definitely still read great books, from Aristotle to Shakespeare to Mill.
Facts and numbers have a high churn rate, but stories and knowledge last a lot longer.
June 14, 2010 — Have you heard of the Emperor Penguins? It's a species of penguins that journeys 30-75 miles across the frigid Antarctic to breed. Each year these penguins endure 8 months of brutally cold winters far from food. If you aren't familiar with them, check out either of the documentaries March of the Penguins or Planet Earth.
I think the culture of the emperor penguins is fascinating and clearly reveals some general traits from all cultures:
Culture is a set of habits that living things repeat because that's what they experienced in the past, and the past was favorable to them. Cultures have a mutually dependent relationship with their adherents.
The Emperor Penguins are born into this Culture. The Culture survives because the offspring keep repeating the process. The Emperor Penguins survive because the process seems to keep them safe from predators and close to mates. The culture and the species depend on each other.
Cultures are borne out of randomness.
At any moment, people or animals are doing things that may blossom into a new culture. Some of these penguins could branch off to Hawaii and start a new set of habits, which 500 years from now might be the dominant culture of the Emperor Penguins.
But predicting what will develop into a culture and what won't is impossible--there's too many variables, too much randomness involved. Would anyone have predicted that these crazy penguins who went to breed in the -40 degree weather for 8 months would survive this long? Probably not. Would anyone have predicted that people would still pray to this Jesus guy 2,000 years later? Probably not.
Cultures seem crazy to outsiders and are almost impossible to explain.
One widespread human culture is to always give an explanation for an event even when the true reason is just too complex or random to understand. The cultural habits are always easier to repeat and pass down then they are to explain.
I don't have any profound insights on culture, I just think it's fascinating and something not to read too much into---it helps us survive, but there's no greater meaning to it.
Notes
- Interesting factet: there are apparently 38 colonies of Emperor Penguins in Antarctica.
Or..We Think we have Free Will because we only Observe One Path.
March 24, 2010 — "Dad, I finished my homework. Why?"
The father thinks for a moment. He realizes the answer involves explaining the state of the world prior to the child doing the homework. It involves explaining the complex probabilities that combined would calculate the odds the child was going to do the homework. And it likely involved explaining quantum mechanics.
The father shrugs and says "Because you have free will, and chose to do it."
Free Will was Born
Thus was born the notion of free will, a concept to explain why we have gone down certain paths when alternatives seemed perfectly plausible. We attribute the past to free will, and we attribute the unpredictability of the future to free will as well (i.e. "we haven't decided yet").
One little problem
The problem is, this is wrong. You never choose just one path to go down. In fact, you go down all the paths. The catch is you only get to observe one.
In one world the child did their homework. In another world, they didn't.
The child who did their homework will never encounter the child who didn't, but they both exist, albeit in different universes or dimensions. Both of them are left wondering why they "chose" the way they did. The reality is that they chose nothing. They're both just along for the ride.
Even the smug boy who says free will doesn't exist, is just one branch of the smug boy.
Notes
- This all assumes, of course, that there are many worlds and not just one.
- Perhaps it is the case that many worlds and free will coexist, in that although we have no absolute control of the future, we can somehow affect the distribution of different paths?
March 22, 2010 — Google has a list of 10 principles that guide its actions. Number 2 on this list is:
It's best to do one thing really, really well.
This advice is so often repeated that I thought it would be worthwhile to think hard about why this might be the case.
Why is it best to do one thing really, really well?
For two reasons: economies of scale and network effects.
Economies of scale. The more you do something, the better you get at it. You can automate and innovate. You'll be able to solve the problem better than it's been solved in the past and please more people with your solutions. You'll discover tricks you'd never imagine that help you create and deliver a better "thing".
Network effects. If you work on a hard problem for a long time, you'll put a great deal of distance between yourself and the average competitor, and in our economy it doesn't take too big a lead to dominate a market. If your product and marketing is 90% as good as the competitor's, it will capture much less than 47% of the market. The press likes to write about the #1 company in an industry. The gold medalist doesn't get 1/3 of the glory, they get 95% of the glory. The network effects in our economy are very strong. If you only do something really well, the company that does it really, really well will eat your lunch.
A simpler analogy: You can make Italian food and Chinese food in the same restaurant, but the Italian restaurant down the street will probably have better Italian food and the Chinese restaurant will probably have better Chinese food, and you'll be out of business soon.
Why the "really, really"?
My English teacher would have told me that at least one of the "really"'s was unnecessary. But if you think about the statement in terms of math having the two "really"'s makes sense.
Let's define doing one thing well as being in the top 10% of companies that do that thing. Doing one thing really well means being in the top 1% of companies that do that thing. Doing one thing really, really well means being in the top 0.1% of companies that do that thing.
Thus, what Google is striving for is to be the #1 company that does search. They don't want to just be in the top 10% or even top 1% of search companies, they want to do it so well that they are at the very top. If you think about it like that, the 2 "really's" make perfect sense.
What's the most common mistake companies make when following this advice?
My guess is they don't choose the correct "thing" for their given team. They pick the wrong thing to focus on. For instance, if Ben and I started a jellyfish business, and decided to do jellyfish tanks really, really well, we would be making a huge mistake because we just don't have the right team for that business. It makes more sense when Al, a marine biology major and highly skilled builder, decides to do jellyfish tanks really, really well.
It makes perfect sense for the Google founders to start Google since they were getting their PhD's in search.
You need good team/market fit. The biggest mistake people make when following the "do one thing really, really well" advice is choosing the wrong product or market for their team.
What's the second most common mistake companies make when following this advice?
Picking a "thing" that's too easy. You should go after a problem that's hard with a big market. Instead of writing custom software for ten of your neighbors that helps them do their taxes, generalize the problem and write internet software that can help anyone do their taxes. It's good to start small of course, but be in a market with a lot of room to grow.
Can you change the one thing you do?
Yes. It's good to be flexible until you stumble upon the one thing your team can do really, really well that can address a large market. Don't be stubborn. If at first you thought it was going to be social gaming, and then you learn that you can actually do photo sharing really, really well and people really want that, do photo sharing.
How do you explain the fact that successful companies actually do a lot of different things?
Microsoft Windows brings in something like $15 billion per year. Google Adwords brings in something like $15 billion per year. When you make that kind of money, you can drop $100 million selling ice cream and it won't hurt you too much. But to get there, you've first got to do one hard thing really, really well, whether it be operating systems or search.
March 17, 2010 — If you automate a process which you repeat Y times, that takes X minutes, what would your payoff be?
Payoff = XY minutes saved, right?
Surprisingly I've found that is almost never the case. Instead, the benefits are almost always greater than XY. In some cases, much greater. The benefits of automating a process are greater than the sum of the process' parts.
Actual Payoff = XY minutes saved + E
What is E? It's the extra something you get from not having to waste time and energy on XY.
An Example
Last year I did a fair amount of consulting work I found via craigslist. I used to check the Computer Gigs page for a few different cities, multiple times per day. I would check about 5 cities, spending about 2 minutes on each page, about 3 times per day. Thus, I'd spend 30 minutes a day just checking and evaluating potential leads.
I then wrote a script that aggregated all of these listings onto one page(including the contents so I didn't have to click to a new page to read a listing). It also highlighted a gig if it met a certain criteria that I had found to be promising. The script even automated a lot of the email response I would write to each potential client.
It cut my "searching time" down to about 10 minutes per day. But then something happened: I suddenly had more time and energy to focus on the next aspect of the problem: getting hired. It wasn't long before I was landing more than half the gigs I applied to, even as I raised my rates.
I think this is where the unexpected benefits come from. The E is the extra energy you'll have to focus on other problems once you don't have to spend so much time doing rote work.
Automate. Automate. Automate
Try to automate as much as possible. The great thing about automation is that once you automate one task you'll have more time to automate the next task. Automation is a great investment with compounding effects. Try to get a process down to as few steps or keystrokes as possible(your ideal goal is zero keystrokes). Every step you eliminate will pay off more than you think.
March 16, 2010 — I wrote a simple php program called phpcodestat that computes some simple statistics for any given directory.
I think brevity in source code is almost always a good thing. I think as a rule your code base should grow logarithmically with your user base. It should not grow linearly and certainly not exponentially.
If your code base is growing faster than your user base, you're in trouble. You might be attacking the wrong problem. You might be letting feature creep get the past of you.
I thought it would be neat to compute some stats for popular open source PHP applications.
My results are below. I don't have any particular profound insights at the moment, but I thought I'd share my work as I'm doing it in the hopes that maybe someone else would find it useful.
| Name | Directories | Files | PHPFiles | PHPLOC | PHPClasses | PHPFunctions |
|---|---|---|---|---|---|---|
| ../cake-1.2.6 | 296 | 677 | 428 | 165183 | 746 | 3675 |
| ../wordpress-2.9.2 | 82 | 753 | 279 | 143907 | 149 | 3827 |
| ../phpMyAdmin-3.3.1-english | 63 | 810 | 398 | 175867 | 44 | 3635 |
| ../CodeIgniter_1.7.2 | 44 | 321 | 136 | 43157 | 74 | 1211 |
| ../Zend-1.10 | 360 | 2145 | 1692 | 336419 | 42 | 11123 |
| ../symfony-1.4.3 | 770 | 2905 | 2091 | 298700 | 362 | 12198 |
March 8, 2010 — If a post on HackerNews gets more points, it gets more visits.
But how much more? That's what Murkin wanted to know.
I've submitted over 10 articles from this site to HackerNews and I pulled the data from my top 5 posts (in terms of visits referred by HackerNews) from Google Analytics.
Here's how it looks if you plot visits by karma score:
The Pearson Correlation is high: 0.894. Here's the raw data:
| Karma | Visits | Page |
|---|---|---|
| 53 | 3389 | /twelve_tips_to_master_programming_faster |
| 54 | 2075 | /code/use_rsync_to_deploy_your_website |
| 54 | 1688 | /unfeatures |
| 34 | 1588 | /flee_the_bubble |
| 25 | 1462 | /make_something_40_of_your_customers_must_have |
| 14 | 1056 | /when_forced_to_wait_wait |
| 4 | 214 | /diversification_in_startups |
| 1 | 146 | /seo_made_easy_lumps |
| 1 | 36 | /dont_flip_the_bozo_bit |
February 19, 2010 — All the time I overhear people saying things like "I will start exercising everyday" or "We will ship this software by the end of the month" or "I will read that book" or "I will win this race." I'm guilty of talking like this too.
The problem is that often, you say you will do something and you don't end up doing it. Saying "I will do", might even be a synonym for "I won't do".
Why does this happen? I don't think it's because people are lazy. I think it's because we overestimate our ability to predict the future. We like to make specific predictions as opposed to predicting ranges.
I'll explain why we are bad at making predictions in a minute, but first, if you find yourself making predictions about what you will do that turn out to be wrong, you should fix that.
You can either tone down your predictions, giving ranges instead. For instance, instead of saying "I think I will win the race", say "I think I will finish the race in the top 10".
Or, even easier: stop talking about things you will do entirely, and only talk about things you have done.
So, in the race example, you might say something like "I ran 3 miles today to train for the race." (If you do win the race, don't talk about it a lot. No one likes a braggert).
Why we are bad at making predictions.
Pretend you are walking down a path:

Someone asks you whether you've been walking on grass or dirt. You can look down and see what it is:

Now, they ask you what you will be walking on. You can look ahead see what it is:

Easy right? But this is not a realistic model of time. Let's add some fog:
Again, someone asks you whether you've been walking on grass or dirt. Even with the fog, you can look down and see what it is:
Now, they ask you what you will be walking on. You look ahead, but now with the fog you can't see what it is:
What do you do? Do you say:
- Dirt
- Grass
- I don't know. It could be either dirt or grass, or maybe something else entirely.
- I don't know. I've been walking on grass. Not sure what I'll be walking on in the future.
In my opinion you should say something like 3 or 4.
This second example models real life better. The future is always foggy.
Why is the future foggy?
I don't know. Maybe a physicist could answer that question, but I don't know the answer. And I don't think I ever will.
Related Posts
Notes
- In other words, don't over-promise and under-deliver.
February 17, 2010 — If a book is worth reading, it's worth buying too.
If you're reading a book primarily to gain value from it(as opposed to reading it for pleasure) you should always buy it unless it's a bad book.
The amount of value you can get from a book varies wildly.
Most books are worthless.
Some can change your life.
For simplicity, let's say the value you can derive from any one book varies from 1 cent to $100,000(there are many, many more worthless books than there are of the really valuable kind).
The cost however, does not vary as much. Books rarely cost more than $100, and generally average to about $15.
You shouldn't read a book that you think will offer you less than $100 in value. Time could be better spent reading more important books.
So let's assume you never read a book that gives you less than $100 in value. Thus, the cost of a physical copy of the book **is at most 15% (using the $15 average price) of the value gained**.
Would owning the book help you extract 15% more from it?
It nearly always will.
When you own a book, you can take it anywhere.
You can mark it up.
You can flip quickly through the pages.
You can bookmark it.
You can easily share it with a friend and then dicuss it.
If these things don't help you get 15% more out of that book, I'd be very surprised.
Where it gets even more certain, is when you read a really valuable book--say a book offering $1,000 of value. Now you'd only need to get 1.5% more out of that book.
The investment in that case is a no brainer.
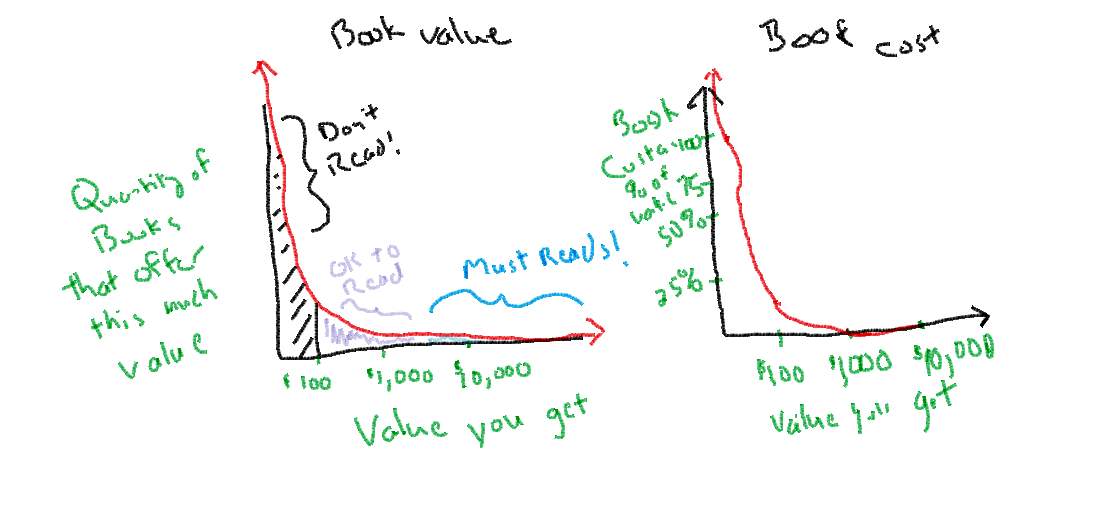
Related Posts
Notes
- Even if a book is more expensive, say $50, the numbers don't change too much.
- Pardon my scribbling. Got a new toy.
February 2, 2010 — My room was always messy. Usually because clothes were strewn everywhere On the floor, on the couch, anywhere there was a surface there was a pile of clothes. Dirty, clean, or mostly-clean scattered about.
I tried a dresser. I tried making a system where I had spaces for each type of clothing: shirts, pants, etc. Nothing worked.
A friend saw my room and quipped, "Duh. You have too many clothes. Let's get rid of most of them."
So we did. About 75% of my clothes were packed up in garbage bags and sent off to the Salvation Army that day.
Ever since, my room has been at least 5x cleaner on average.
Almost always, there is one simple change you can make that will have drastic effects. This change is called the least you can do.
I had a website that was struggling to earn money even with a lot of visitors. I added AdSense and almost nothing happened. Then I moved the AdSense to a different part of the page and it suddenly made 5x more money. A week later I changed the colors of the ad and it suddenly made 2x as much money. Now the site makes 10x as much money and I barely did anything.
That's a trivial example, but the technique works on real problems as well.
The key is to figure out what the "least you can do" is.
You can discover it by working harder or smarter:
- The hard way. You can try a ton of things, go through a to-do list dozens of items long, and hope you hit upon it.
- The smart way. You can invest time learning instead of doing. Reading books, learning new math or programming techniques, talking to other people, thinking critically, etc. You'll then have a much better hunch at what the "least you can do is".
In reality you need to do things both ways. But try to put extra effort into doing things the smart way, and see where it takes you.
Notes
- Thanks to Conor for providing feedback.
- I never shop for clothes. Once a year, maybe twice. The reason I had so many was because I never got rid of any clothes.
- This AdSense site doesn't make a ton of money, but it now makes enough to pay all my server bills, which is nice.
- Finding the least you can do is kind of like diff. You are trying to find the smallest change you can make to turn the status quo into an improved version.
- Another relevant computer science topics is the The longest common subsequence problem.
January 29, 2010 — Good communication is overcommunication. Very few people overcommmunicate. Undercommunication is much more common. Undercommunication is also the cause of countless problems in business.
Instead of striving for some subjective "good communication", simply strive to overcommunicate.
It's very unlikely you'll hit a point where people say "he communicates too much".
It's much more likely you'll come up a bit short, in which case you'll be left with good communication.
Here are 4 tips that will bring you closer to overcommunicating:
- Say the hard things. Often the hardest things to talk about are the most important things to talk about. If something is stressing you out, just say it. Getting it out there, even if not in the most eloquent way, is much better than not talking about it at all. A good strategy when approaching a hard subject is to bounce your approach off a neutral 3rd party to see if your angle is smart. Many times it's the other person who has something they're stressed about but isn't talking about. It's your job to be perceptive and ask them questions to get it out on the table.
- Repeat yourself. People have bad memories and even worse attention spans. Repeat yourself. If something is very important, repeat yourself multiple times. If someone hasn't gotten the message, it's more likely your fault for not repeating yourself enough than it is their fault for not getting it.
- Use tools. Email, Facebook, Google Wave, Basecamp, Skype, Gchat, Dropbox, Github, Sifter...these are just a sample of the modern tools you can use to communicate. Embrace them. Try different ones. Try pen and paper and whiteboards. Ideally you'll find two or three tools that cover all the bases, but don't be afraid to use multiple tools even if you have to repeat yourself across them a bit.
- Set a regular schedule. Set aside a recurring time for communication. It could be once a week or once a day. Even if there's nothing new to talk about, it will help to just go over the important topics again as you can rarely repeat yourself too much.
That's it. Good luck!
January 22, 2010 — Network effects are to entrepreneurs what compounding effects are to investors: a key to getting rich.
Sometimes a product becomes more valuable simply as more people use it. This means the product has a "network effect".
You're probably familiar with two famous examples of network effects:
- Windows. People started using Microsoft Windows. Therefore, developers started building more software for Windows. This made Windows more valuable, and more people started to use it.
- Facebook. People joined Facebook and invited their friends. Their friends joined which made the site more valuable to everyone. People invited more friends.
All businesses have network effects to some degree. Every time you buy a slice of pizza, you are giving that business some feedback and some revenue which they can use to improve their business.
Giant businesses took advantage of giant network effects. When you bought that pizza, you caused a very tiny network effect. But when you joined Facebook, you immediately made it a more valuable product for many other users(who could now share info with you), and you may even have invited a dozen more users. When a developer joins Facebook, they might make an application that improves the service for thousands or even millions of users, and brings in a similar number of new users.
The biggest businesses enabled user-to-user network effects. Only the pizza store can improve its own offering. But Facebook, Craiglist, Twitter, and Windows have enabled their customers and developers to all improve the product with extremely little involvement from the company.
Notes
- This is probably easier said than done.
January 15, 2010 — In computer programming, one of the most oft-repeated mottos is DRY: "Don't Repeat Yourself."
The downside of DRY's popularity is that programmers might start applying the principle to conversations with other humans.
This fails because computers and people are polar opposites.
With computers, you get zero benefit if you repeat yourself. With people, you get zero benefit if you don't repeat yourself!
Four Ways Computers and People are Different
- A computer's memory is perfect. A computer forgets nothing. Tell it something once, and it will remember it forever. A human remembers almost nothing. I forget what I had for breakfast 2 days ago. I don't remember which people I talked to last week, nevermind what was said. If memory were cheese, a computer's would be cheddar and a human's would be swiss. You've got to repeat yourself when communicating with people because people forget.
- A computer is always paying attention. Computers are perfect listeners. They are always listening to your input and storing it in memory. You, the operator, are the only thing they care about. Computers don't have needs. They don't daydream or have cellphones(yet). People on the other hand, rarely if ever pay full attention. They zone in and out. It's hard to even tell if they're zoned in, as we've all learned it's better to nod our heads. People have their own needs and concerns and opinions. You've got to repeat yourself when communicating with people because people don't pay attention.
- A computer understands your logic. When you write a program, a computer never misunderstands. It will execute the program exactly as you typed it. People, however, do not communicate so flawlessly. Until I was 22 I used to think "hors d'oeuvres" meant dress nice. I did not understand the pronunciation. One time a friend emailed me about an event and said "Our place. Hors d'oeuvres. 7pm" and I responded "Awesome. Will there be food?" You've got to repeat yourself when communicating with people because people don't understand.
- A computer doesn't need to know what's most important. Computers don't make decisions on their own and so don't need to know what's most important. A computer will remember everything equally. Then it will sit awaiting your commands. It won't make decisions without you. A person, however, will make decisions without you and so needs to know the order of importance of things. For example, if you're not a fan of peanuts, you might tell the waiter once that you'd prefer the salad without nuts. But if you're deathly allergic to peanuts, you should probably repeat yourself a few times so the waiter knows there better not be any nuts on your salad. You've got to repeat yourself when communicating with people because people need to know what's most important.
A Numeric Explanation
If you tell something to your computer once:
- The odds the computer remembers: 100%.
- The odds the computer was paying attention: 100%.
- The odds the computer understood you: 100%.
- The odds the computer gets the importance right: 100%.
If you tell something to a person once:
- The odds the person remembers: 30%?
- The odds the person was paying attention: 40%?
- The odds the person understood you: 50%?
- The odds the person gets the importance right: 30%?
In other words, the odds of communicating perfectly are very low: 1.8%! You are highly likely to run into at least one of those four problems.
Now, if you repeat yourself 1 time, and we assume independence, here's how the probabilities change:
- The odds the person remembers: 51%
- The odds the person was paying attention: 64%
- The odds the person understood you: 75%
- The odds the person gets the importance right: 51%
By repeating yourself just once you've increased the chances of perfect communication from 1.8% to 12.5%! Repeat yourself one more time and the probability of perfect communication increases to over 90%. Well, in this simplistic model anyway. But I hope you get the idea.
Repeat yourself until you overcommunicate
To communicate well you should try to overcommunicate. Overcommunicating is hard to do. It's much easier and more common to undercommunicate. If you're not repeating yourself a lot, you're not overcommunicating.
An example of how I repeat myself
On the various projects I'm involved with we use Gmail, Google Docs, Google Wave, Basecamp, Github, Sifter, gChat and Skype. Which one do I prefer?
None of them. I prefer pen, paper, whiteboards and face-to-face meetings. I write down my own todo list and schedule with pen and paper. Then I login to these sites and repeat what I've written down for the sake of repeating myself to other people. This isn't inefficiency, it's good communication.
Some people prefer Google Docs, some prefer Basecamp. I'll post things to both, to ensure everyone knows what I'm working on.
With every new project I repeat a lot of messages and questions to the team:
- "How many people love this product?"
- "How can we make this simpler?"
- "Which of the 7 deadly sins does this appeal to?"
I think these are important questions and so I'll repeat them over and over and add them to the todo lists for every project, multiple times.
Notes
- I've yet to be part of founding a big Internet company, so you don't have to agree with me that repeating yourself is critical to success.
January 14, 2010 — When a problem you are working on forces you to wait, do you wait or switch tasks?
For example, if you are uploading a bunch of new web pages and it's taking a minute, do you almost instinctively open a new website or instant message?
I used to, and it made me less productive. I would try to squeeze more tasks into these short little idle periods, and as a result I would get less done.
Multitasking during idle times seems smart
Doing other things during idle times seems like it would increase productivity. After all, while you're waiting for something to load you're not getting anything done. So doing something else in the interim couldn't hurt, right? Wrong.
Switching tasks during idle times is bad, very bad
While you're solving one problem, you likely are "holding that problem in your head". It takes a while to load that problem in your head. You can only hold one important problem in your head at a time. If you switch tasks, even for a brief moment, you're going to need to spend X minutes "reloading" that problem for what is often only a 30 second vacation to Gmail, Facebook, Gchat, Hackernews, Digg, etc. It's clearly a bad deal.
Don't multitask
If you're doing something worth doing, give it all of your attention until it's done. Don't work on anything else, even if you're given idle time.
Why you can't multitask well
Human intelligence is overrated. Even the smartest people I know still occasionally misplace their keys or burn toast. We are good at following simple tasks when we focus, most of the time. But we are not built for multitasking.
Can you rub your head clockwise? Can you rub your belly counterclockwise? Can you say your ABC's backwards?
Dead simple, right? But can you do all three at once? If you can, by all means ignore my advice and go multitask.
Wait out those idle times
If what you are doing is easy or mundane, multitasking is permissible because loading a simple problem like "laundry" into your head does not take much time. But if what you are doing is important and worth doing, you are obligated to give it your full attention and to wait out those "idle times".
If you switch tasks during your idle times, you're implying that the time to reload the problem is less than the time gained doing something else. In other words, you are implying what you are doing is not worth doing. If that's the case, why work on it at all?
Notes
- Influenced by Paul Graham's Holding a Program in One's Head
- Of course, if you're given a very long idle time, then feel free to switch tasks. Don't spend 4 hours staring at your screen waiting for a coworker to get back to you.
January 12, 2010 — Whether you're an entrepreneur, a venture capitalist, a casual investor or just a shopper looking for a deal, you should know how to buy low and sell high.
Buying low and selling high is not easy.
It's not easy because it requires too things humans are notoriously bad at: long term planning and emotional control. But if done over a long period of time, buying low and selling high is a surefire way to get rich.
Warren Buffett is perhaps the king of buying low and selling high. These tips are largely regurgitated from his speeches and biographies which I've been reading over the past two years.
Let the market serve you, not instruct you.
Everything has both a price and a value. Price is what you pay for something, value is what you get. The two rarely match. Both can fluctuate wildly depending on a lot of things. For instance, the price of gas can double or triple in a year based on events in the Middle East, but the value of a gallon of gas to you largely remains constant.
Don't let the market ever tell you the value of something--don't let it instruct you. Your job is to start figuring out the intrinsic value of things. Then you can take advantage when the price is far out of whack with the true value of something--you can make the market serve you.
Google's price today is $187 Billion. But what's its value? The average investor assumes the two are highly correlated. Assume the correlation is closer to 0. Make a guess about the true value of something. You may be way off the mark in you value estimating abilities, but honing that skill is imperative.
Be frugal.
You've got to be in a position to take advantage of the market, and if you spend your cash on unnecessary things, you won't be. Buy food in bulk at Costco. Cut your cell phone bill or cancel it altogether. Trim the fat wherever you can. You'd be surprised how little you can live off of and be happy. Read P.T. Barnum's "The Art of Moneygetting" for some good perspective on how being frugal has been a key to success for a long time.
Always be able to say "no".
The crazy market will constantly offer you "buy high, sell low" deals. You've got to be able to turn these down. If you don't have good cash flow or a cash cushion, it's very hard. That's why being frugal is so important.
Be Happy
If you're happy with what you have now it's easy to make good deals over the long run. Buying low and selling high requires long term emotional control. If you're unhappy or stressed, it's very hard to make clear headed decisions. Do what you have to do to get happy.
Make the Easy Deals
Out of the tens of thousands of potential deals you can make every month, which ones should you act on? The easy ones. Don't do deals in areas that you don't understand. Do deals where you know the area well. I wouldn't do a deal in commodities, but I'd certainly be willing to invest in early stage tech startups.
Margin of Safety
The easy deals have a wide margin of safety. An easy deal has a lot of upside. An easy deal with a wide margin of safety has little to no downside. Say a company has assets you determine are worth $1 Million and for some reason the company is selling for $950,000. Even if the company didn't grow, it has a good margin of safety because the price of its assets alone are worth more than the price you paid.
Read a lot
How do you find these easy deals? You've got to read a lot. You've got to keep your eyes open. Absorb and think mathematically about a lot of information you encounter in everyday life.
Buy a business
Businesses can be the ultimate thing to buy low and sell high because they have nearly unlimited upside. Real estate, gold, commodities, etc., can be good investments perhaps. But when's the last time you heard of someone's house going up 10,000%? Starting a business can be your best investment ever, as you are guaranteed to buy extremely low, and have the potential to sell extremely high.
January 5, 2010 — Possibly the biggest mistake a web startup can make is to develop in a bubble. This is based on my own experience launching 13 different websites over the past 4 years. The raw numbers:
| Type | Count | Successes | TimeToLaunch | CumulativeGrossRevenues | %ofTotalTraffic | CumulativeProfits | EmotionalToll |
|---|---|---|---|---|---|---|---|
| Bubble | 3 | 0 | Months | <$5,000 | <1% | -$10,000's | High |
| NonBubble | 10 | 5-8 | 1-14Days | $100,000's | >99% | Good | None-low |
What is "the bubble"?
The bubble is the early, early product development stage. When new people aren't constantly using and falling in love with your product, you're in the bubble. You want to get out of here as fast as possible.
If you haven't launched, you're probably in the bubble. If you're in "stealth mode", you're probably in the bubble. If you're not "launching early and often", you're probably in the bubble. If you're not regularly talking to users/customers, you're probably in the bubble. If there's not a steady uptick in the number of users in love with your product, you're probably in the bubble.
Why you secretly want to stay in the bubble
A part of you always wants to stay in the bubble because leaving is scary. Launching a product and having it flop hurts. You hesitate for the same reason you hesitate before jumping into a pool in New England: sure, sometimes they're heated, but most of the time they're frickin freezing. If the reception to your product is cold, if no one falls in love with it, it's going to hurt.
The danger of the bubble
You can stand at the edge of the pool for as long as you want, but you're just wasting time. Life is too short to waste time.
In addition to wasting time, money and energy in the bubble (which can seem like a huge waste if your product flops), two things happen the longer you stay in the bubble:
- The marginal return of each additional unit of effort decreases.
- Expectations increase.
This is a very bad combination that can lead to paralysis. The more you pour into your bubble product, the less impact your additional efforts will have yet at the same time the more you will expect your product to succeed.
Don't wait any longer: jump in the water, flee the bubble!
How to Flee the Bubble
Here are four easy strategies for leaving the bubble: launch, launch & drop, pick one & launch, or drop.
Launch. Post your product to your blog today. Email your mailing list. Submit it to Reddit or Hackernews or TechCrunch. Just get it out there and see what happens. Maybe it will be a success.
Launch & Drop. Maybe you'll launch it and the feedback will be bad. Look for promising use cases and tweak your product to better fit those. If the feedback is still bad, drop the product and be thankful for the experience you've gained. Move on to the next one.
Pick One & Launch. If you're product has been in the bubble too long, chances are it's bloated. Pick one simple feature and launch that. You might be able to code it from scratch in a day or two since you've spent so much time already working on the problem.
Drop. Ideas are for dating not marrying. Don't ever feel bad for dropping an idea when new data suggests it's not best to keep pursuing it. It's a sign of intelligence.
That's all I've got. But don't take it from me, read the writings of web entrepreneurs who have achieved more success. (And please share what you find or your own experiences on HackerNews).
December 28, 2009 — At our startup, we've practiced a diversification strategy.
We've basically run an idea lab, where we've built around 7 different products. Now we're getting ready to double down on one of these ideas.
The question is, which one?
Here's a 10 question form that you can fill out for each of your products.
Product Checklist
- How many users/customers does the product have?
- What percentage of these users/customers would be disappointed if this product disappeared tomorrow?
- Explain the product in one sentence:
- Is the product good/honest? Yes
- What is the predicted customer acquisition cost? $
- What is the predicted average lifetime value per customer? $
- Which of the 7 deadly sins does the product appeal to? Lust Greed Sloth Gluttony Pride Envy Wrath
- What's the go to market strategy in one sentence?
- What resources do you need to do this?
- What's the total addressable market size? people $
2021 Update: I think the model and advice presented here is weak and that this post is not worth reading. I keep it up for the log, and not for the advice and analysis provided.
December 24, 2009 — Over the past 6 months, our startup has taken two approaches to diversification. We initially tried no diversification and then we tried heavy diversification.
In brief, my advice is:
Diversify heavily early. Then focus.
In the early stages of your startup, put no more than 33% of your resources into any one idea. When you've hit upon an idea that you're excited about and that has product/market fit, then switch and put 80% or more of your resources into that idea.
How Startups Diversify
An investor diversifies when they put money into different investments. For example, an investor might put some money into stocks, some into bonds, and some into commodities. If one of these investments nosedives, you won't lose all your money. Also, you have better odds that you'll pick some investments that generate good returns. The downside is that although you reduce the odds of getting a terrible outcome, you also reduce the odds of getting a great outcome.
A startup diversifies when it puts resources into different products. For example, a web startup might develop a search engine and an email service at the same time and hope that one does very well.
The 4 Benefits of Diversification for Startups
There are 4 main benefits to diversify:
- Better odds. Creating multiple products increases the odds of finding a great idea in a great market. The Internet provides very fast feedback about whether you've found one. After building your team, the next big thing to decide is what product to focus on. You should not choose one until you're built a product you're excited about and found product/market fit. You've found product/market fit when about 40% of your customers think your product is a must have.
- Builds individual skills. Entrepreneurs need broad skillsets. Trying multiple products forces you to learn new skills. You may build a consumer video site and improve your technical scaling skills while at the same time be trying a B2B site and improving your sales skills.
- Builds team skills. Doing multiple products gives you plenty of opportunities to interact with your team in varied situations. You'll learn faster what your teammates' strengths and weaknesses are. You'll also be forced to improve your team communication, coordination, delegation and product management skills.
- It's fun. Let's be honest, the early stages of working on a new problem or idea are oftentimes the most stimulating and exciting. Instead of focusing on one product day in and day out that might or might not work, trying multiple ideas keeps your brain going and your enthusiasm high.
When to Focus
If diversifying has so many benefits, should you ever stop? Yes, you should.
Focus when you are ready to make money.
Coming up with new ideas and building new, simple products is the easy part of startups. Unfortunately, developing new solutions is not what creates a lot of value for other people. Bringing your solution to other people is when most value is created--and exchanged.
Imagine you're a telecom company and you build a fiber optic network on the streets of every city in America--but fail to connect people's homes to the new system. Although connecting each home can be hard and tedious, without this step no value is created and no money will come your way.
When you hear the phrase "execution is everything", this is what it refers to. If you want to make money, and you've got a great team and found product/market fit, you've then got to focus and execute. Drop your other products and hunker down. Fix all the bugs in your main product. Really get to know your customers. Identify your markets and the order in which you'll go after them. Hire great people that have skills you are going to need.
Benefits of Focusing
Let's recap the benefits of focusing.
- Money. Creating new products in the early days is fun, but making money is fun too. Once you start focusing on growing one product, the money incentive will keep you motivated and spirits high.
- Rewarding. Creating value for other people is perhaps the most rewarding feeling in life. Finding people with a problem, and getting your solution which solves their problem into their hands, is even better than the money you earn. You'll also create valuable jobs for your employees.
- Resources. If you execute well, you'll end up with resources that you can use to put diversification back into the picture. For instance, after bringing better search to almost the whole world, Google can now diversify and create better email systems, web browsers, maps, etc.
Benefits of the "Diversify Early, Then Focus" approach: A Roulette Analogy
When you first begin your startup it's very similar to playing roulette. You plunk down some resources on an idea and then the wheel spins and you win more money or lose the money that you bet.
In roulette, you can bet it all on one number(focusing) or bet a smaller amount on multiple numbers(diversifying). If you bet it all on one number and win, you get paid a lot more money. But you're also more likely to lose it all.
The "game of startups" though, has two very important differences:
- You get more information after the game starts "spinning".
- You can always move your bets around.
You get way more information about the odds of an idea "hitting the jackpot" after you plunked some time and money into it. You may find customers don't really have as big a problem as you thought. Or that the market that has this problem is much smaller than you thought. You may find one idea you thought was silly actually solves a big problem for people and is wildly popular.
You can then adjust your bets. If your new info leads you to believe that this idea has a much higher chance of hitting the jackpot, grab your resources from the other ideas and plunk them all down on this one. Or vice versa.
Don't Take My Word for It
Sadly I bet there are paperboys who's businesses have done better than all mine to date, so take my advice with a grain of salt.
But if you want to learn more, I suggest reading the early histories of companies such as eBay, Twitter, and Facebook and see what their founders were up to before they founded those sites and in the following early period.
And check back here, I'll hopefully be sharing how this approached worked for us.
Notes
- Fun tidbit: I wrote this on paper then typed it up and posted it all while flying on Virgin Air from SFO back to Boston. Thanks for the free wifi Google!
- Thanks to Ben for helping me form my ideas on this issue.
December 23, 2009 — It is better to set small, meaningful goals than to set wild, audacious goals.
Here's one way to set goals:
Make them good. Make them small.
Make them Good
Good goals create value. Some examples:
- Make a customer smile.
- Teach someone math.
- Learn how to cook.
- Organize weather information.
Make them Small
Start small. It is better to set one or two goals per time period than to set two dozen goals. Instead of a goal like "get 1,000,000 people to your website", start with a smaller goal like "get 10 people to your website."
If you exceed a goal and still think it's a good thing, raise the goal an order of magnitude. If you get those 10 visitors, aim for 100.
Why Small Goals Are Better
Setting smaller goals is better because:
- It feels good when you exceed a goal. Occasionally you'll wildly exceed a goal and that will feel great.
- It's better to do a few small good things, than to fail trying one audacious thing.
- It's easier to accomplish an audacious thing by going one step(order of magnitude) at a time.
- It's less stressful and makes you happier. Low expectations are good because in most cases you will exceed them and feel happy. High expectations, by definition, are bad because in most cases you will not meet them and feel bad.
- Goals are arbitrary anyway. All goals are simply arbitrary constraints that help you focus--often with a team--to get stuff done. So since they're arbitrary, and as long as they're good goals, might as well make them simpler and easier.
Setting Ranges
Another way to set goals is to use ranges. Set a low bar and a high bar. For example, your weekly goals might be:
| LowBar | HighBar | What |
|---|---|---|
| 2 | 7 | new customers |
| 2 | 4 | product improvements |
| 1 | 3 | blog posts |
If you exceed your low bar, you can be happy. If you exceed your high bar, you can be very happy.
December 20, 2009 — Programming, ultimately, is about solving problems. Often I make the mistake of judging a programmer's work by the elegance of the code. Although the solution is important, what's even more important is the problem being solved.
Problems are not all created equal, so while programming you should occasionally ask yourself, "is this problem worth solving?"
Here's one rubric you can use to test whether a problem is worth solving:
- Simplicity. Can you envision a simple solution to the problem? Can you create at least a partial, meaningful solution or prototype in a short period of time? Building a flying car would solve a lot of my transportation problems, but I don't see a simple path to getting there. Don't be too far ahead of your time. Focus on more immediate problems.
- Value. Would solving this problem create value? Sometimes it's hard to predict in advance whether or not your solution would create value for people. The easiest way to tell if you've succeeded is if anyone would be disappointed if your solution were to disappear. If you can get a first prototype into people's hands early, you'll find out quickly whether or not you are building a solution to a problem that creates value.
- Reach. Do a lot of people have this problem? Some problems, like searching for information, are shared by nearly everyone. Others, like online version control, are shared by a much smaller niche but still a significant amount of people. If a problem is shared by only a handful of people, it's probably not worth programming a solution.
Great Programmers Solve Important Problems
The best programmers aren't simply the ones that write the best solutions: they're the ones that solve the best problems. The best programmers write kernels that allow billions of people to run other software, write highly reliable code that puts astronauts into space, write crawlers and indexers that organize the world's information. They make the right choices not only about how to solve a problem, but what problem to solve.
Life is Short
Life is too short to solve unimportant problems. If you want to solve important problems, it's now or never. The greatest programmers only get to solve a relatively small amount of truly important problems. The sooner you get started working on those, the better.
Ignore Speed Limits
If you don't have the skills yet to solve important problems, reach out to those who do. To solve important problems, you need to develop a strong skill set. But you can do this much faster than you think. If you commit to solving important problems and then reach out to more committed programmers than you, I'm sure you'll find many of them willing to help speed you along your learning curve.
December 16, 2009 — If you combine Paul Graham's "make something people want" advice with Sean Ellis' product-market fit advice (you have product-market fit when you survey your users and at least 40% of them would be disappointed if your product disappeared tomorrow), you end up with a possibly even simpler, more specific piece of advice:
Make something 40% of your users must have
Your steps are then:
- 1. Make something people want.
- 2. Put it out there.
- 3. Survey your users. If less than 40% would be disappointed if your product disappeared, go back to step 1.
Only when you hit that 40% number(or something in that range) should you be comfortable that you've really made something people want.
Does this advice work? I think it would for 3 reasons.
#1 The Sources
PG and Sean Ellis know what they're talking about.
#2 Companies that make my "Must Haves" are successful
I made a list of my "must have" products and they are all largely successful. I suggest you try this too. It's a good exercise.
My List of Must Haves:
- Google Search
- Gmail
- Dropbox
- craigslist
- Windows
- Excel
- Twitter Search
- Firefox
- Chrome
- Wikipedia
- Amazon
- (More Technical Products)
- Git + Github
- LAMP Stack
- Ruby
- Notepad++
- Vim
- jQuery
- Firebug
- Web Developers Extension
- StackOverflow
- TechCrunch
- HackerNews
- Navicat
#3 The Only "Must Have" Product I Built was the Biggest Success
I've worked on a number of products over the past 3 years.
One of them I can tell you had a "I'd be disappointed if this disappeared" rate of over 40%. We sold that site.
All the others did not have that same "must-have" rate. We launched Jobpic this summer at Demo Day. People definitely wanted it. But we didn't get good product/market fit. If we had surveyed our users, I bet less than 10% of them would report being disappointed if Jobpic disappeared. Our options are to change the product to achieve better product/market fit, or go forward with an entirely new product that will be a must have.
Concluding thoughts
I don't know if this advice will work. But I'm going to try it.
Startup advice can be both exhilarating and demoralizing.
On the plus side, good advice can drastically help you. At the same time, if it's really good advice that means two things:
- 1. This is how you should be doing things.
- 2. You were not doing things this way.
That can frustrating. I've spent a few years now in the space and to realize you've been doing certain things wrong for a few years is...well...painful.
But you laugh it off and keep chugging along.
Notes
- Thanks Nivi for the great Venture Hacks interview!
- Users/Customers refer to people who use your site regularly or buy from you. This is not "visitors". Generally a much lower percentage than 40% of visitors become users or customers. The 40% refers to the people who have made it through your funnel and have become users or customers.
- I used customers and users interchangeably. For non-tech businesses, you can just use "customer" each time.
- Thanks to Ben, Alex Andon, and Andrew Kitchell for feedback.
- Another piece of startup advice that didn't "click" until recently: Roelof Botha's 7 deadly sins advice.
December 15, 2009 — The best Search Engine Optimization(SEO) system I've come across comes from Dennis Goedegebuure, SEO manager at eBay. Dennis' system is called LUMPS. It makes SEO dead simple.
Just remember LUMPS:
- Links
- Uurls
- Metadata
- Page Content
- Sitemaps
These are the things you need to focus on in order to improve your SEO. You should also, of course, first know what terms you want to rank highly for.
LUMPS is listed in order of importance to search engines. So links are most important, sitemaps are least important.
Let's break each one down a bit more.
Links
External links--links from domains other than your own--are most important. For external links, focus on 3 things, again listed in order of importance:
- Quality. A link from CNN.com is worth order(s) of magnitude more than a link from my blog. A link from a related source, like from ESPN.com to a sports blog, would likely be better than from an unrelated source.
- Quantity. Even though quality is most important, a lot of inbound links help.
- Anchor Text. You want links with relevant anchor text. Jellyfish tanks is better than click here.
Your internal link structure is also important. Make sure your site repeatedly links to the pages you are optimizing for.
External links are the most important thing you need for SEO. Internal links you can easily control, but it takes time to accumulate a lot of quality external links. Focus on creating quality content(or even better, build a User Generated Content site). People will link to interesting content.
URL Structure
The terms you are optimizing for should be in your urls. It's even better if they are in your domain. For instance, if I'm optimizing for "breck yunits", I've done a good job by having the domain name breckyunits.com. If I'm optimizing for the term "seo made easy", ideally I'd have that domain. But I don't, so having breckyunits.com/seomadeeasy is the next best thing.
Luckily, URL Structure is not just important, it's also relatively easy to do well and you can generally set up friendly URLs in an hour or so. I could explain how to do it with .htaccess and so forth, but there are plenty of articles out there with more details on that.
Metadata Content
Your TITLE tags and META DESCRIPTIONS tags are important for 2 reasons. First, search engines will use the content in them to rank your pages. Second, when a user sees a search results page, the title and description tags are what the user sees. You need good copy that will increase the Click Through Rate. Think of your title and description tags as the Link Text and Description in an AdWords ad. Just as you'd optimize the AdWords ad, you need to optimize this "seo ad". Make the copy compelling and clear.
Like URL structure, you can generally set up a system that generates good meta and description tags relatively easily.
Page Content
Content is king. If you've got the other 3 things taken care of and you have great content, you're golden. Not only will great content please your visitors, but it will likely be keyword rich which helps with SEO. Most importantly, it is much easier to get links to valuable, interesting content than to bad content. Figure out a way to get great content and the whole SEO process will work a lot better.
Sitemaps
Sitemaps are not the most crucial thing you can do, but they help and are an easy thing to check off your list. Use Google Webmaster tools and follow all recommendations and submit links to your sitemaps.
Summary
There you have it, SEO made easy! Just remember LUMPS.
Links
- Google WebmasterTools
- SEOBook - one of the best SEO sites out there.
December 13, 2009 — Do you "flip the bit" on people?
If you don't know what that means, you probably do it unknowingly!
What it means
When you "flip the bit" on someone you ignore everything they say or do. You flip the bit on a person when they are wrong or make a mistake over and over again. Usually you flip the bit unconsciously.
An example
You are writing a program with Bob. Bob constantly writes buggy code. You get frustrated by Bob's bugs and slowly start ignoring all the code he submits and start writing everything yourself. You've flipped the bit!
This is bad for everyone. Now you are doing more work, and Bob is becoming resentful because you are ignoring his ideas and work.
Alternatives to Flipping the Bit
Instead of flipping the bit, perhaps you could work with another person. If that's not possible, take a more constructive approach:
- Teach. Talk to Bob and figure out why he is making repeated mistakes. We all have large gaps in our education. If you've never been exposed to a concept, there's no reason why you should understand it. Try and find what it is Bob hasn't been exposed to yet, and help him learn it.
- Change Roles. Maybe Bob should be working in another area. Find an area where you're the and Bob's the expert. Let him work in that area, while you work in your area. He can even explain a thing or two to you.
Why We Flip the Bit
It seems like a simple evolutionary trick to save time. If someone is right only 10% of the time, would it be faster to ignore every statement they made, or faster to analyze each statement carefully in case it's the 1 out of 10 statements that might be true? Seems like it would be faster to just ignore everything by flipping the bit.
But this is a bad solution. The two presented above are better.
Notes
- Thanks to Tom Price for telling me about this.
Links
- Bozo bit on Wikipedia.
- Origin of the term?
December 11, 2009 — Jason Fried from 37signals gave a great talk at startup school last month. At one point he said "software has no edges." He took a normal, everyday bottle of water and pointed out 3 features:
- 1. The bottle held the water.
- 2. The lightweight plastic made it easy to carry, and you can tell how full it was by picking it up.
- 3. The clear bottle let you see how much was left and what was in it.
If you added a funnel to help pour the water, that might be useful in 5% of cases, but it would look a little funny. Then imagine you attach a paper towel to each funnel for when you spill. Your simple water bottle is now a monstrosity.
The clear edges of physical products make it much harder for feature creep to happen. But in software feature creep happens, and happens a lot.
A proposal to fight feature creep
How do you fight feature creep in software? Here's an idea: do not put each new feature request or idea on a to-do list. Instead, put them on an (un)features list.
An (un)features list is a list of features you've consciously decided not to implement. It's a well maintained list of things that might seem cool, but would detract from the core product. You thought about implementing each one, but after careful consideration decided it should be an (un)feature and not a feature. Your (un)features list will also include features you built, but were only used by 1% of your customers. You can "deadpool" these features to the (un)features list. Your (un)features list should get as much thought, if not more, than your features list. It should almost certainly be bigger.
When you have an idea or receive a feature request, there's a physical, OCD-like urge to do something with it. Now, instead of building it or putting it on a todo list, you can simply write it down on your (un)features list, and be done with it. Then maybe your water bottles will look more like water bottles.
This blog is powered by software with an (un)features list.
Notes
- Feel free to move an (un)feature to your features list if you change your mind about it.
Links
- More great quotes from this year's Startup School
- 37signals and their great blog
Edit: 01/05/2010. Features are a great way to make money.
December 10, 2009 — Employees and students receive deadlines, due dates, goals, guidelines, instructions and milestones from their bosses and teachers. I call these "arbitrary constraints".
Does it really matter if you learn about the American Revolution by Friday? No. Is there a good reason why you must increase your sales this month by 10%, versus say 5% or 15%? No. Does it really matter if you get a 4.0 GPA? No.
But these constraints are valuable, despite the fact that they are arbitrary. They help you get things done.
Constraints Help You Focus
Constraints, whether meaningful or not, simplify things and help you focus. We are simple creatures. Even the smartest amongst us need simple directions: green means go, red means stop, yellow means step on it. Even if April 15th is an arbitrary day to have your tax return filed, it is a simple constraint that gets people acting.
Successful People Constantly Set Constraints
Successful people are good at getting things done. They focus well. Oftentimes they focus on relatively meaningless constraints. But they meet those constraints, however arbitrary. By meeting a lot of constraints, in the long run they hit enough of those non-arbitrary constraints to achieve success. Google is known for it's "OKR's"--objectives and key results--basically a set of arbitrary constraints that each employee sets and tries to hit.
Entrepreneurs Must Set Their Own Constraints
If you start a company, there are no teachers or bosses to set these constraints for you. This is a blessing and a curse. It's a blessing because you get to choose constraints that are more meaningful to you and your interests. It's a curse because if you don't set these constraints, you can get fuddled. Being unfocused, at times, can be very beneficial. Having unfocused time is a great way to learn new things and come up with new ideas. However, to get things done you need to be focused. And the first step to get focused is to set some arbitrary constraints.
A Specific Example
Here are some specific constraints I set in the past week:
- Write 1 blog post per day.
- Create blogging software in under 100 lines of code.
- Have version 0.2 of blogging software done by 5pm yesterday.
All of these are mostly arbitrary. And I have not met all of them. But setting them has helped me focus.
When You Don't Meet Your Constraints
If you don't meet your constraints, it's no big deal. They're largely arbitrary anyway. Even by just trying to meet your constraints, you learn a lot more. You are forced to think critically about what you are doing.
When you don't meet some constraints, set new ones. Because you now have more experience, the new ones might be less arbitrary.
But the important thing is just having constraints in the first place.
December 9, 2009 — A lot of people have the idea that maybe one day they'll become rich and famous and then write a book about it. That's probably because it seems like the first thing people do after becoming rich and famous is write a book about it.
But you don't have to wait until you're rich and famous to write a book about your experiences and ideas.
A few months ago I was talking to another MBA student, a very talented man, about 30 years old from a great school with a great resume. I asked him what he wanted to do for his career, and he replied that he wanted to go into a particular field, but thought he should work for McKinsey for a few years first to add to his resume. To me that's like saving sex for your old age. It makes no sense.Warren Buffet
Likewise, saving blogging for your old age makes no sense. There are two selfless reasons why you should start blogging now:
- You may enlighten someone.
- Sharing your experiences adds another data point to our collective knowledge and makes us all better off.
It used to take a lot of work to publish something. Now it is simpler than brushing your teeth. So publish, write, blog!
If you need some selfish reasons, here are 5:
- Writing is good exercise for the brain and gives you "writer's high".
- Blogging makes you a better writer.
- When your blog gets traffic, it stokes your ego.
- You may spark interesting conversations with interesting people.
- In rare circumstances, you may make money.
Blogging. Don't save it for your old age.
December 8, 2009 — Finding experienced mentors and peers might be the most important thing you can do if you want to become a great programmer. They will tell you what books to read, explain the pros and cons of different languages, demystify anything that seems to you like "magic", help you when you get in a jam, work alongside you to produce great things people want, and challenge you to reach new heights.
Great coders travel in packs, just like great authors.
If you want to reach the skills of a Linus, Blake, Joe, Paul, David, etc., you have to build yourself a group of peers and mentors that will instruct, inspire, and challenge.
Here are 6 specific tips to do that.
- Get a programming job. This is probably the best thing you can do. You'll get paid to "practice". You'll work on things that will challenge you and help you grow. And you'll have peers who will provide instruction and motivation constantly. There are tens of thousands of open programming jobs right now. Even if you feel you are not qualified for one, apply anyway, and stress how you are smart, passionate, and the experience will come with time. If you don't get a programming job today, you can reapply in 6 months or 1 year when you have better skills. Here are six job sites to check out: Craigslist (Computer Gigs, Internet Engineers, Software, Systems, Web Design) StackOverflow, CrunchBoard, HackerNews, Reddit, Startuply.
- Take a programming class. My best tutors are my peers. People who I took a class or two with in college. We knew each other when computers were a big mystery to us, so we don't feel embarassed when we ask questions that may sound dumb. If you're currently in college, enroll in a programming class. Otherwise, look at local colleges' continuing education programs, community colleges, or professional classes. If you're in San Francisco, maybe look at AcademyX. Give unclasses.com a try. If you think classes cost too much, don't use that as an excuse until you've tried to negogiate a deal. Often someone will give you a class for free or greatly reduced price simply by explaining your situation. Other times maybe you can offer a service in return.
- Attend a Meetup. I go to PHP and MySQL meetups frequently. Meetup.com has thousands of programming meetups throughout the country. Go to one. Every month. You'll learn from the speaker, you'll meet other programmers, and you'll meet recruiters who will try to hire you if you still haven't gotten that job.
- Join Github. Github is the first user friendly collaborative development site for programmers. Once you get comfortable with it, you could be working alongside other programmers on open source projects in no time. I'll write a better tutorial on how to get started soon, but for now, just join and explore around. It may take you a month or two to "get it", so don't feel overwhelmed if you don't understand what's going on at first. You will eventually. And you'll start to find some great programmers to talk to.
- Email Someone Directly. Email has been around for 35 years and it's still the favorite mode of communication for programmers. If you like someone's work, send them an email and ask for 1 or 2 tips. I've found when I email great programmers, their responses are usually short and to the point. That's not because they don't want to help, it's just that they're busy and use time effectively. Keep your emails brief and specific and they can be of great aid.
- Enlist a Friend. If you excercise with someone else, you burn 50% more calories on average. Likewise, if you learn programming with a friend, you'll learn 50% faster. That's a significant time savings. It's also more fun. You must have a friend who has a similar interest as you in programming. Why not suggest that you get serious about learning it together?
Hopefully you'll find some of these tips useful. Feel free to email me if you need a first mentor (breck7 at google's email service). I'm not very good yet, but I may be able to help.
Notes
- That exercise percentage is a guess, but sounds right to me.
Related Posts
December 7, 2009 — Do you think in Orders of Magnitude? You should.
If you think in orders of magnitude you can quickly visualize how big a number is and how much effort it would take to reach it.
Orders of magnitude is a way of grouping numbers. The numbers 5, 8 and 11 are all in the same order of magnitude. The numbers 95, 98 and 109 are in the same order of magnitude as well, but their order of magnitude is one order of magnitude greater than 5, 8, 11.
Basically, if you multiple a number by 10, you raise it one order of magnitude. If you've ever seen the scary looking notation 5x10^2, just take the number five and raise it 2 orders of magnitude (to 500).
Think of orders of magnitude as rough approximations. If you want the number 50 to be in the same order of magnitude as the number 10, you can say that "it's roughly in the same order of magnitude" or that "it's about half an order of magnitude bigger". Don't worry about being exact.
Orders of magnitude is a great system because generally there's a huge difference between 2 numbers in different orders of magnitude. Thus to cross from one order of magnitude to the next, a different type of effort is required than to simply increment a number. For example, if you run 2 miles each day and then decide to run one more, 3 total, it should be easy. But if you decided to run one more order of magnitude, 20 miles, it would take a totally new kind of effort. You'd have to train longer, eat differently, and so forth. To go from 2 to 3 requires a simple approach, just increase what you're doing a bit. To go from 2 to 20, to increase by an order of magnitude, requires a totally different kind of effort.
A Business Example
Let's do a business example.
Pretend you started a business delivering pizza. Today you have five customers, make 5 pizzas a week, and earn $50 revenue per week.
You can keep doing what you're doing and slowly raise that to 6 customers, then 7 and so on. Or you can ask yourself, "How can I increase my business an order of magnitude?"
Going from 5 to 50 will take a different type of effort than just going from 5 to 6. You may start advertising or you might create a "Refer a Customer, get a free pizza" promotion. You might have to hire a cook. Maybe lower your price by $2.
Imagine you do all those things and now have 50 customers. How do you get to 500?
Now you might need a few employees, television advertisements, etc.
Growing a business is the process of focusing like a laser on the steps needed to reach the next order of magnitude.
Here are some more examples of orders of magnitude if it's still not clear:
Bill Gates has approximately $50,000,000,000. Warren Buffett has $40,000,000,000. For Warren to match Bill, he merely has to make a few more great investments and hope Microsoft's stock price doesn't go up. He does not have to increase his wealth an order of magnitude. I on the other hand, have $5 (it was a good month). For me to become as rich as BillG, I have to increase my wealth 10 orders of magnitude. That means that I'd have 10 different types of hard challenges to overcome to match BillG's wealth.
- Going from $5 to $50 may mean just working a bit and could be accomplished in a day.
- Going from $50 to $500 would mean working a few days.
- Going from $500 to $5,000 might mean getting a job that pays more.
- Going from $5,000 to $50,000 would mean getting a job that pays more, saving more, and doing that for a longer period.
- Going from $50,000 to $500,000 might mean doing all that, plus making some good investments.
- ... and so forth.
More examples
- If your room is 200 square feet, the world is 13 orders of magnitude greater than your room.
- Google indexes 10,000,000,000 pages. This site is 10 pages. There are 9 orders of magnitude more pages in the Google Index.
- Facebook has 350 million users. Dropbox has 3 million. Facebook has 2 orders of magnitude more users.
- The population of California is about 35 million. The population of the US is one order of magnitude bigger, about 300 million. The population of China is about 4 times that of the U.S. at 1,300,000, which is less than an order of magnitude difference.
- Shaq is about 1 order of magnitude taller than a newborn, but besides that height is much more narrowly distributed. Everyone is within the same order of magnitude tall.
Related Posts
Notes
- WolframAlpha
- Thanks to Mairi and Andrew Kitchell for providing feedback.
December 6, 2009 — Imagine you are eating dinner with 9 friends and you all agree to play Credit Card Roulette. Credit Card Roulette is a game where everyone puts their credit card in a pile and the server randomly chooses one and charges the whole meal to it.
Imagine you are playing this game with your own friends. Pause for a second and picture it happening.
...
What did you see?
I bet you saw one person's card get picked and that person was sad and everyone else laughed.
Wrong!
This is not what really happened! In reality, despite the fact that you observed only one's person card getting picked, in reality everyone's card got chosen.
In reality, when you played the game, the world split into 10 paths, and every person's card got picked in one of those paths. You only observed one path, but trust me, there were 9 others.
This is a simple example of the many worlds law. You probably were not taught the many worlds law in school, which is a shame. It's one of the most important laws in the world.
Notes
- I love this game because I don't have a credit card
- You can benefit greatly from understanding the many worlds law. Take solace in the fact that somewhere out there you won the lottery and are drinking a pina colada on your private island right now.
- The many worlds law could very well be wrong. There could be just 1 world. There could be 42. I don't think about that much. There may be no god, but betting there is one has benefits.
- I called it the many worlds "law" because I don't want to use the word theory or hypothesis. Theory and hypothesis are too linked in people's minds with uncertainty, and some ideas, like evolution and many worlds, have way too much supporting evidence to leave any room for uncertainty, in as much as we can be uncertain about something.
- One of the most important laws in most worlds, anyway.
December 4, 2009 — Do you want to become a great coder? Do you have a passion for computers but not a thorough understanding of them? If so, this post is for you.
Saying #1: 10,000 Hours
There is a saying that it takes 10,000 hours of doing something to master it.
So, to master programming, it might take you 10,000 hours of being actively coding or thinking about coding. That translates to a consistent effort spread out over a number of years.
Saying #2: No Speed Limit
There is another saying that I just read which inspired me to write this, that says "there is no speed limit".
In that post, Derek Sivers claims that a talented and generous guy named Kimo Williams taught him 2 years worth of music theory in five lessons. I have been learning to program for 2 years, and despite the fact that I've made great progress, my process has been slow and inefficient.
I did not have a Kimo Williams. But now that I know a bit, I'll try and emulate him and help you learn faster by sharing my top 12 lessons.
I'll provide the tips first, then if you're curious, a little bit more history about my own process.
The 12 Tips
- Get started. Do not feel bad that you are not an expert programmer yet. In 10,000 hours, you will be. All you need to do is start. Dedicate some time each day or week to checking things off this list. You can take as long as you want or move as fast as you want. If you've decided to become a great programmer, youve already accomplished the hardest part: planting the seed. Now you just have to add time and your skills will blossom. If you need any help with any of these steps, feel free to email me and Ill do my best to help.
- Dont worry. Do not be intimated by how much you dont understand. Computers are still largely magic even to me. We all know that computers are fundamentally about 1s and 0s, but what the hell does that really mean? It took me a long time to figure it out--it has something to do with voltages and transistors. There are endless topics in computer science and endless terms that you won't understand. But if you stick with it, eventually almost everything will be demystified. So don't waste time or get stressed worrying about what you don't know. It will come, trust me. Remember, every great programmer at one time had NO IDEA what assembly was, or a compiler, or a pointer, or a class, or a closure, or a transistor. Many of them still dont! That's part of the fun of this subject--you'll always be learning.
- Silicon Valley. Simply by moving to Silicon Valley, you have at least: 10x as many programmers to talk to, 10x as many programming job opportunities, 10x as many programming meetups, and so on. You don't have to do this, but it will make you move much faster. The first year of my programming career was in Boston. The second year was in San Francisco. I have learned at a much faster pace my second year.
- Read books. In December of 2007 I spent a few hundred dollars on programming books. I bought like 20 of them because I had no idea where to begin. I felt guilty spending so much money on books back then. Looking back, it was worth it hundreds of times over. You will read and learn more from a good $30 paperback book than dozens of free blogs. I could probably explain why, but its not even worth it. The data is so very clear from my experience that trying to explain why it is that way is like trying to explain why pizza tastes better than broccoli: Im sure there are reasons but just try pizza and you'll agree with me.
- Get mentors. I used to create websites for small businesses. Sometimes my clients would want something I didnt know how to do, simple things back then like forms. I used to search Google for the answers, and if I couldnt find them, I'd panic! Dont do that. When you get in over your head, ping mentors. They dont mind, trust me. Something that youll spend 5 hours panicking to learn will take them 2 minutes to explain to you. If you dont know any good coders, feel free to use me as your first mentor.
- Object Oriented. This is the "language" the world codes in. Just as businessmen communicate primarily in English, coders communicate primarily in Object Oriented terms. Terms like classes and instances and inheritance. They were completely, completely, completely foreign and scary to me. Theyd make me sick to my stomach. Then I read a good book(Object Oriented PHP, Peter Lavin), and slowly practiced the techniques, and now I totally get it. Now I can communicate and work with other programmers.
- Publish code. If you keep a private journal and write the sentence The car green is, you may keep writing that hundreds of times without realizing its bad grammar, until you happen to come upon the correct way of doing things. If you write that in an email, someone will instantly correctly you and you probably won't make the mistake again. You can speed up your learning 1-2 orders of magnitude by sharing your work with others. Its embarrassing to make mistakes, but the only way to become great is to trudge through foul smelling swamp of embarrassment.
- Use github. The term version control used to scare the hell out of me. Heck, it still can be pretty cryptic. But version control is crucial to becoming a great programmer. Every other developer uses it, and you can't become a great programmer by coding alone, so you'll have to start using it. Luckily, you're learning during an ideal time. Github has made learning and using version control much easier. Also, Dropbox is a great tool that your mom could use and yet that has some of the powerful sharing and version control features of something like git.
- Treat yourself. Build things you think are cool. Build stuff you want to use. Its more fun to work on something you are interested in. Programming is like cooking, you don't know if what you make is good until you taste it. If something you cook tastes like dog food, how will you know unless you taste it? Build things you are going to consume yourself and you'll be more interested in making it taste not like dog food.
- Write English. Code is surprisingly more like English than like math. Great code is easy to read. In great code functions, files, classes and variables are named well. Comments, when needed, are concise and helpful. In great code the language and vocabulary is not elitist: it is easy for the layman to understand.
- Be prolific. You dont paint the Mona Lisa by spending 5 years working on 1 piece. You create the Mona Lisa by painting 1000 different works, one of them eventually happens to be the Mona Lisa. Write web apps, iPhone apps, Javascript apps, desktop apps, command line tools: as many things as you want. Start a small new project every week or even every day. You eventually have to strike a balance between quantity and quality, but when you are young the goal should be quantity. Quality will come in time.
- Learn Linux. The command line is not user friendly. It will take time and lots of repetition to learn it. But again, its what the world uses, you'll need at least a basic grasp of the command line to become a great programmer. When you get good at the command line, its actually pretty damn cool. Youll appreciate how much of what we depend on today was written over the course of a few decades. And youll be amazed at how much you can do from the command line. If you use Windows, get CYGWIN! I just found it a few months ago, and it is much easier and faster than running virtualized Linux instances.
That's it, go get started!
Actually, I'll give you one bonus tip:
- Contact me. My email address is breck7 at Google's mail service. Feel free to ping me for personal help along your journey, and I'll do my best to lend a hand.
My Story, briefly
Two years ago, in December 2007, I decided to become a great programmer. Before then, I had probably spent under 1,000 hours "coding". From 1996 to 2007, age 12 to age 23, I spent around 1,000 hours "coding" simple things like websites, MSDOS bat scripts, simple php functions, and "hello world" type programs for an Introduction to Computer Science class. Despite the fact that I have always had an enormous fascination with computers, and spent a ton of time using them, I was completely clueless about how they worked and how to really program.
(If you're wondering why didn't I start coding seriously until I was 23 and out of college there's a simple and probably common reason: the whole time I was in school my goal was to be cool, and programming does not make you cool. Had I known I would never be cool anyway, I probably would have started coding sooner.)
Finally in December 2007 I decided to make programming my career and #1 hobby. Since then I estimate I've spent 20-50 hours per week either coding or practicing. By practicing I mean reading books about computers and code, thinking about coding, talking to others, and all other related activities that are not actually writing code.
That means I've spent between 2,000-5,000 hours developing my skills. Hopefully, by reading these tips, you can move much faster than I have over the past 2 years.
Links
- Github
- Dropbox
- StackOverflow - when you need help, and eventually where you can give help
- Cygwin
Notes
- The saying that it takes 10,000 hours to master something may or may not be true but is indisputably popular (which is often an attribute of true ideas).
- I added the quotes around "coding" when describing my past experience because it was simple stuff, and it felt funny funny calling it coding just as it would sound funny calling a 5 year old's work "writing".
- I still have a long way to go to become a "great programmer", 2-4 more years I'd say.
Related Posts
December 3, 2009 — What would happen if instead of writing about subjects you understood, you wrote about subjects you didn't understand? Let's find out!
Today's topic is linear algebra. I know almost nothing about vectors, matrices, and linear algebra.
I did not take a Linear Algebra course in college. Multivariable calculus may have done a chapter on vectors, but I only remember the very basics: it's a size with a direction, or something like that.
I went to a Borders once specifically to find a good book to teach myself linear algebra with. I even bought one that I thought was the most entertaining of the bunch. Trust me, it's far from entertaining. Haven't made it much further than page 10.
I bet vectors, matrices, and linear algebra are important. In fact, I'm positive they are. But I don't know why. I don't know how to apply linear algebra in everyday life, or if that's something you even do with linear algebra.
I use lots of math throughout the day such as:
- Addition/subtraction when paying for things
- Multiplication when cooking for 6 roommates
- Probability when deciding whether to buy cell phone insurance
- Calculus when thinking about the distance needed to break fast while biking
- Exponents and logs when analyzing traffic graphs and programming
But I have no idea when I should be using vectors, matrices, and other linear algebra concepts throughout the day.
There are lots of books that teach how to do linear algebra. But are there any that explain why?
Would everyone benefit from linear algebra just as everyone would benefit from knowing probability theory? Would I benefit?
I don't know the answer to these questions. Fooled by Randomness revealed to me why probability is so incredibly important and inspired me to master it. Is there a similar book like that for linear algebra?
I guess when you write about what you don't know, you write mostly questions.
December 2, 2009 — What books have changed your life? Seriously, pause for a few minutes and think about the question. I'll share my list in a moment, but first come up with yours.
Do you have your list yet? Writing it down may help. Try to write down 10 books that you think have most impacted your life.
Take all the time you need before moving on.
Are you done yet? Don't cheat. Write it down then continue reading.
Okay, at this point I'm assuming you've followed instructions and wrote down your list of 10 books.
Now you have one more step. To the right of each book title, write "fiction" or "nonfiction". You can use the abbreviations "F" and "NF" if you wish.
You should now have a list that looks something like mine:
- How to Read a Book - NF
- Never Eat Alone - NF
- Fooled by Randomness - NF
- How to Win Friends and Influence People - NF
- Snowball - NF
- Influence - NF
- Object Oriented PHP - NF
- Life of Pi - F
- Lord of the Flies - F
- The Illiad - F
Now, count the NF's. How many do you have? I have 7. So 7 out of the 10 books that I think have most impacted my life are non-fiction. Therefore, if I have to guess whether the next book I read that greatly impacts my life will be fiction or nonfiction, my guess is it will be nonfiction.
What's your list? Do you think the next book that will greatly impact your life will be fiction or non-fiction?
Share your results here.
Notes
- I read about equal amounts fiction and nonfiction. So on average, I get greater return from nonfiction reading.
- Reading fiction is a more enjoyable form of entertainment.
- This essay is in response to a comment I read a while back on HackerNews that got me thinking about the subject.
Experience is what you get when you don't get what you want.
December 2, 2009 — How many times have you struggled towards a goal only to come up short? How many times have bad things happened to you that you wish hadn't happened? If you're like me, the answer to both of those is: a lot.
But luckily you always get something when you don't get what you want. You get experience. Experience is data. When accumulated and analyzed, it can be incredibly valuable.
To be successful in life you need to have good things happen to you. Some people call this "good luck". Luck is a confusing term. It was created by people who don't think clearly. Forget about the term "luck". There is not "good luck" and "bad luck". Instead, "good things happen", and "bad things happen". Your life is a constant bombardment of things happening, good and bad. Occasionally, despite making bad decisions steadily, some people have good things happen to them. But in most cases to have good things happen to you, you've got to make a steady stream of good decisions.
You've got to see patterns in the world and recognize cause and effect. You've got to think through your actions and foresee how each action you take will affect the chances of "good things happening" versus "bad things happening" down the line.
When you're fresh out of the gate, it's hard to make those predictions. You just don't have any data so you can't analyze cause and effect appropriately. But once you're out there attempting things, even if you screw up or don't get what you want, you get experience. You get data to use to make better decisions in the future.
December 2, 2009 — Decided to blog again. I missed it. Writing publicly, even when you only get 3 readers, two of which are bots and the other is your relative, is to the mind what exercise is to the body. It's fun and feels good; especially when you haven't done it in a while.
Also decided to go old school. No Wordpress or Tumblr, Blogger or Posterous. Instead, I'm writing this on pen and paper. Later I'll type it into HTML using Notepad++, vim, or equivalent(EDIT: after writing this I coded my own, simple blogging software called brecksblog). It will just be text and links. Commenting works better on hackernews, digg, or reddit anyway.
Hopefully these steps will result in better content. Pen and paper make writing easier and more enjoyable, so hopefully I'll produce more. And the process of typing should serve as a filter. If something sucks, I won't take the time to type it.
I'm writing to get better at communicating, thinking, and just for fun. If anyone finds value in these posts, that's an added bonus.
Written 11/30/2009
May 6, 2009 — There’s a discussion on a mailing list I belong to about piracy and the iPhone. One of the responders I thought was really insightful. The basic premise is “what you focus on, increases”–at least in your mind–so it’s better not to focus on negative things. In this example, by focusing on the small problem of pirated iPhone apps, bigger opportunities are missed. I’ve reprinted the part below:
There are a variety of sayings along the lines of “what you focus on, increases”. I’m not saying that more people will pirate your software just because you’re paying attention to the pirates, but at least the problem increases in your mind! The more you think about it and worry about it and try to fight it, the bigger it becomes (subjectively speaking). I try to look at it another way entirely. The time and effort I’ve put into my software is a “sunk cost”, and the revenues I receive from sales cannot really offset that cost in a direct way; unlike consulting, where revenues are tied directly to expended effort, in this case it’s basically a different category on the balance sheet. Any person who buys a copy increases my revenue. Anybody who doesn’t buy it, *including*pirates*, has no effect on my revenue. Of course I’d like to increase the number of buyers, but singling out the pirates as the market segment I’d like to expand into seems like a lost cause. A lot of people installing pirated apps are people who just can’t or won’t buy software (since we’re talking about iPhone apps that go for a few dollars, I guess that “can’t” doesn’t even apply, it’s almost exclusively “won’t”). Even in a perfect world of indefeatable piracy protection, those people probably *still* wouldn’t buy apps. They’d just stick to the thousands of free apps that are out there.
Note: I imported this post from my original Wordpress blog.
April 14, 2009 — Here’s what I’m going to assume: craigslist, Google, and eBay do not have very pretty designs. How can a website be so successful if the design isn’t pretty? My position is that because design doesn’t matter a whole lot.
Utility and function matter a whole lot more. Why doesn’t design matter a whole lot? What would you rather look at:
Computer Screen versus View. Image source.
Imagine trying to compete with nature. My premise is that you go to a website for the utility of it. Design is far secondary. There are plenty of prettier things to look at in the real world. Of course, you can make a website that is pretty to look at, that people will love spending time on. The way to do that is to make it look like the real world: Facebook photos, YouTube videos, etc. People will spend a lot of time on those sites because pictures and videos look pretty. But if you make a website with a whole lot of utility, design is secondary. (And if your goal is to make a website that sells something instead of providing a service–then sometimes ugly designs win–in that case the trick is to try a lot of variation to see what works).
Related Posts
Note: I imported this post from my original Wordpress blog.
April 6, 2009 — Twitter Search is starting to replace a ton of websites that I used to visit.
I used to check ESPN.com for sports scores. Now I use Twitter Search. It’s significantly faster. Just checked the UNC/Michigan State score and saw it’s a blowout early. No need to load up the slow espn.com homepage.
I used to check NBC.com, Hulu and other websites to see if the shows I want to watch are new this week. Now I use Twitter Search. Seriously, every Thursday I search “the office” nbc, to see if it’s new.
I’m even using CNN less now. I wanted to learn more about the earthquake in Italy. I used Twitter search and found a link to a page with photos and a lot more.
When I experienced my first earthquake in San Francisco last week, within 1 minute I used Twitter search to confirm that it was actually an earthquake.
Twitter Search is trending up in my own life. I think the odds are high that it will be huge. I think the odds are high it will become THE source for news.
Note: I imported this post from my original Wordpress blog.
March 31, 2009 — There’s a post currently on Hacker News that discusses irrational numbers. A long time ago irrational numbers really bothered me. I remember I had a teacher in high school who gave us extra credit for reading books about math that dealt with specific topics like pi or irrational numbers. These books gave me nightmares :). I still don’t really understand irrational numbers but haven’t thought about them in a long time. According to Wikipedia:
In mathematics, an irrational number is any real number that is not a rational number—that is, it is a number which cannot be expressed as a fraction m/n, where m and n are integers, with n non-zero. Informally, this means numbers that cannot be represented as simple fractions. It can be deduced that they also cannot be represented as terminating or repeating decimals, but the idea is more profound than that. As a consequence of Cantor’s proof that the real numbers are uncountable (and the rationals countable) it follows that almost all real numbers are irrational.[1] Perhaps the best-known irrational numbers are π, e and √2.
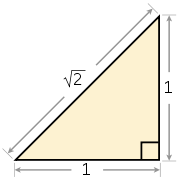
Here’s what I think now that I didn’t understand back in the day. Say someone showed me the picture of the triangle above and said “write down the exact length of the hypotenuse in decimal form”, I might try and use Pythagorean’s Theorem and say C^2 = A^2+B^2 so c = 2^.5…Then if I tried to write the 2^.5 in decimal form of course I’d go on forever.
But what I don’t understand is why I would assume the sides = 1. I don’t understand why 1 is a rational number. How do we know that the side is precisely 1? I would say it looks more like 1.0000001 to me, but I could be wrong. But I’ll settle that the probability that the side is 1 is pretty good so I’ll use that. And since I can’t be sure the side was exactly 1 but I rounded it to 1 anyway then I might as well just round 2^.5 to 1.4. So there, now 2^.5 (or 7/5) is a rational number. Probability and statistics is the best!
My point is growing up math was probably my favorite subject. Calculus amazed me. I really thought math was eventually going to explain everything to me about the world. But then it started getting much more specific and I stopped seeing math in everyday life. With calculus I saw derivatives in everything from the acceleration of a car to the temperature drop at night. But a few years of multivariable calculus and linear algebra and stuff later and I stopped getting a sense that math could really answer the big questions about the world.
Then I finally took probstat(relatively late in life) and years later I still can’t get enough. I think probability and statistics should be taught early and often. It can do amazing things, like pricing insurance, increasing sales, curing diseases, and turning irrational numbers rational.
P.S. I know this is probably a naive look at complex math topics, but I’m 1% sure that I’m totally correct and all those smart mathematicians are wrong.
Note: I imported this post from my original Wordpress blog.
January 5, 2009 — I’m reading a fascinating biography of Warren Buffett right now(Snowball).
So Warren Buffett, Bill Gates, and a few other gazillionaires are sitting around at a resort in British Columbia drinking some cokes and shooting the shit. It is 1990, George Bush is president and the Internet revolution is still a few years away.
The trillionaires are having a discussion about what companies will have a banner decade in the 90’s. Someone mentions Kodak. Bill says Kodak is dead. His nutshell description of why Kodak is dead has to do with photography shifting from film to digital storage. Bill is simplyfying to say that all Kodak does is make film. Even though they are the best at it, that doesn’t matter because more and more pictures are being stored on digital media, not film. Bill tells his friends: “you get rid of film so knowing how to make film becomes absolutely irrelevant.”
Maybe I’m overplaying this, but I thought it was a very sharp insight, concisely said. You can apply the pattern to a number of different industries:
Cars: “you get rid of horses so knowing how to make horseshoes becomes absolutely irrelevant.”
Cell phones: “you get rid of landlines so knowing how to make landlines becomes absolutely irrelevant.”
Music: “you get rid of CDs so knowing how to make cds becomes absolutely irrelevant.”
Yet to happen(and may or may not happen, just trying to illustrate the thought process):
“you get rid of Facebook/Twitter/Myspace so knowing how to make Facebook/Twitter/Myspace apps becomes absolutely irrelevant.”
You could probably even apply it to Microsoft itself:
“you get rid of desktop apps so knowing how to make desktop apps becomes absolutely irrelevant.”
This is a simplification certainly. Things take time to disappear and if you’re the market leader there is still good money to be made. But if you want to stick around you certainly have to adopt to big swings like this. Microsoft is obviously trying hard to replace get better at “internet apps” while still cashing in on its dominance of “desktop apps”. Time will tell how well they do(I’d personally likely bet on them succeeding).
I think it would be a good excercise for startup founders to try and apply this pattern to their own business. Are you making something that will become absolutely irrelevant? When you’re just starting out, you don’t have a whole lot of room for error.
Comment from Jeremy: i just finished reading through the book, and thoroughly enjoyed it as well. My second favorite tidbit was when Buffett and Gates were with Gates parents and a group of other biz people, and Gates father asked everyone what was the single biggest factor to each person's success. Bill Gates and Buffett's responses were the same: "Focus"
Note: I imported this post from my original Wordpress blog.
November 23, 2008 — A bright meteorite was caught on film in Canada this week.
I think with the recent exponential growth in video cameras we’ll all become a lot more familiar with meteorites in the years ahead.
Note: I imported this post from my original Wordpress blog.
October 12, 2008 — I just want to share the most valuable piece of Internet startup advice I possess.
The startup advice out there is filled with pyschology mumbo jumbo, but ALL THAT REALLY MATTERS IS THE NUMBERS.
- How many pageviews/users/sales/conversions do you have?
- Are you growing, shrinking, or stagnate?
- What’s your revenue? What are your expenses?
From day one, you should be following the numbers. This means you have to put up a website in week one. Without a product out in the marketplace, you can’t get numbers. All that matters is the numbers. Without them, you’ve got nothing.
You absolutely cannot force an Internet startup to success. The market dictates your success plain and simple. You have a great idea and great team but the numbers haven’t picked up yet? Sorry, the market said no. Time to move on.
You have to listen to the market, and the market speaks with numbers, not words(ignore praise from family and friends and early users, numbers are the only praise that matter in the startup world). That’s really the only thing you should pay attention to.
A month into my startup last year, SeeMeWin, one of the co-founders said to me and the other partner:
Him: “Guys, I’ve discovered a pattern in our traffic.”
Me: “Well, what is it?”
Him: “Every week it decreases.”
Me: (Proceed to ignore the importance of this simple statement and pursue the idea for 5 more months, believing that because we had a good team and we thought the idea was good we could succeed, which was too bad because from month 1 the market was giving us PRICELESS advice–we should have been working on a different idea)
Every other mistake was irrelevant because the only thing that matters is the numbers.
From month one, you have to be tracking the numbers. Do not pour effort into anything unless the numbers have shown it to be worthwhile. If you’re not tracking the numbers yet, then you’re not really trying. If you are tracking the numbers and they don’t look good, don’t put a whole lot of effort into it until you get permission from the market–improved numbers.
That’s my advice for the day.
Note: I imported this post from my original Wordpress blog.
September 19, 2008 — Got in to San Fran last night. Moved in to the Mission District with college buddies. I expect to be a multibillionaire in a month, tops.
Note: I imported this post from my original Wordpress blog.
August 20, 2008 — This evening JustHackIt.com launched. Before you co-found a company, you need to find good co-founders. The best way to do that is to just work on projects with people. The idea for JustHackIt is to connect hackers in one place and encourage them to just start projects together, without even knowing the person. Hopefully you’ll find some people who are smart, talented, and will make a great co-founder in the future.
The idea stemmed from the YC meetup last week. PG said that the YC interviews aren’t like interviews at all, they just “Do YC”. If the team and YC seem to click, then they get accepted. I think the same thing applies for finding good cofounders–you just start something and see if the chemistry among the team clicks. I’ve started projects with friends and complete strangers before, and whether or not I knew them before the project isn’t correlated with how well we worked together. There are a few people I met the day of starting a joint project who I’d love to start another company with.
That’s what I hope this site could do: not just bring hackers together to discuss startups, but bring them together to launch things and find new cofounders.
Already, the site’s getting pretty good traffic–400 visitors in the last hour. I don’t know if it will go anywhere, but it took only a few minutes to put together(thanks to slinkset) and hopefully will connect at least 1 co-founder team.
BTW, the signup rate is pretty good–users are already in the double digits!
Note: I imported this post from my original Wordpress blog.
July 28, 2008 — The hiccups have been cured. Want to know what the secret is?
It’s simple, whenever you get the hiccups, all you have to do is think to yourself “I am not a fish. I am not a fish. I am not a fish…”
Laugh it up. Everyone I have told this since February has laughed and called me crazy. But they shut up when their hiccups suddenly stop. It has now worked 100% of the time, instantly, every time I have shared it.
The inventor of the cure is Neil Shubin, who looked at brain patterns in fish and humans with the hiccups. Electrical signals in the brain trigger hiccups. In fish, these signals run automatically to keep the gills working and the fish breathing. We descended from fish, and at some point these automatic electronic signals to hiccup became unneccessary. But every now and again they turn on. All you have to do to turn them off is remind yourself you are not a fish, and can breathe just find without an automatic hiccuping signal.
Here’s the article that gave me the secret back in February.
Should work anytime, all the time. I’ve seen 100% instant success rates. Let me know if it doesn’t work for you.
Note: I imported this post from my original Wordpress blog.
July 28, 2008 — On August 31, 1854, a Londoner living on Broad Street fell ill with cholera and died. In three days, 127 other Londoners would also contract and die of cholera. By September 10th, over 500 people had died and panic was setting in on the London streets. Doctors studied the dead but could not solve the epidemic.
Then John Snow, a British Physician, gathered a huge sample of data and determined that people who drank from a certain water pump on Broad Street died, and those that didn’t, lived. The well was boarded up. Problem solved.
Because John Snow studied a large sample size of patients, he was able to determine the relatively simple cause and cure.
If we’re going to solve the global warming problem we need data like John Snow’s. If Dr. Snow had spent all his time studying just one patient, whatever “cause” and “solution” he would come up with would likely have been incorrect. It was only after looking at a large sample size of hundreds of patients that he was able to come up with a cause and solution much more substantiated than a guess.Right now, nearly every global warming article I read about the cause, consequence, and solution, is guessing. In the global warming problem, the patient is the earth. Everyone is overanalyzing the heck out of one patient and as a result all the conclusions have as much bearing as random guesses.
If we want to take this problem seriously, we need to be like John Snow: we need to collect data on dozens, if not hundreds of patients. Only then will we be able to make rational decisions about the problem.
So, we need to start looking outward to other planets. We have some nearby data in the form of Mars and Venus. Mars is damn cold and there’s no life there, so likely a hotter planet is a positive thing to a certain extent. Venus is damn hot and there’s also no life there, so likely if earth heads in that direction we’re screwed. But that doesn’t leave us with a whole lot to go on. We really need to find patients more similar to us, and hundreds of them.
I know very little about astronomy or telescopes. But I’m pretty sure that those are going to be our best tools to fight global warming. All the doctors in the world couldn’t have stopped the cholera outbreak if they studied one patient. But one doctor, studying hundreds of patients, was able to solve the problem.
Likewise, if we can give one astronomer a big enough telescope, he could probably solve global warming for us. Maybe he’ll find out that the chances of turning into Venus are extremely slim and the problem isn’t a problem at all. Or maybe it is a problem, but other earth like planets have solved it somehow. It could be just as simple as boarding up a well.
Note: I imported this post from my original Wordpress blog.
July 27, 2008 — Decided to try out one of these book social networks to see if I can find some important books I should be reading. The idea is you enter the books you’ve read and rate them, as well as the books you want to read. Then the site will show you people who like similar books and you can hopefully stumble upon some books that they’ve read that you will like.
The three main sites I found were Shelfari, GoodReads, and LibraryThing. The idea is pretty cool, because a good book recommendation, unlike a movie recommendation, can possibly change your life. So the chance of getting a huge payoff from these services is relatively very high. Not bad for spending no money and just a couple minutes or even an hour or two entering your book list and exploring the shelves of others.
My primary goal is to find business and technical books. Finding good fiction or literature to read is not a problem for me–there’s plenty of it out there. Really what I’m looking for is books that have been read by people I respect in a business/technical role. That’s why I think a service like this could be more valuable than Amazon’s recommendation engine. I’m looking for quality books read by quality people. Amazon generally recommends popular books. The books I want to read don’t necessarily have to be popular among the masses, just popular among the people who I want to learn from.
I started with Shelfari, then checked out Goodreads, and then on to LibraryThing.
They are all pretty good. I will update this post later with more detailed reviews, but I have to say if you sign up for one you might as well sign up for them all. You will increase your chances of finding “diamond in the rough” books that way. Of course, it takes time to input your books into all 3 of them, but there could be a quicker way to do that(I’m gonna look into existing sites, otherwise might roll one myself).
The traffic stats:
Compete.com shows goodreads pulling away from the comptetion.
shelfari(red), goodreads(blue), librarything(orange)
Google Trends for Websites also shows goodreads in the lead and growing fastest.
Note: I imported this post from my original Wordpress blog.
July 9, 2008 — It’s nice to know that more than 50% of the people alive today have been around for longer than I have(at least for a few more years).
According to the World Factbook:
| Median | Age |
|---|---|
| male | 27.4 years |
| female | 28.7 years (2008 est.) |
World’s per capita income: $10,000 (2007 est.)...Although this distribution is a lot different than the distribution of ages, so you can’t draw the same conclusions.
Note: I imported this post from my original Wordpress blog.
July 7, 2008 — After months of deliberation, I’ve decided to quit my day job and work on my blog full time.
I am joking.
But these bloggers were not:
MacRumors.com (2008)
“Yesterday was my last day at my full time job as a physician. I plan to work on MacRumors.com and other web projects full time.” [source]
kottke.org (2005)
“I recently quit my web design gig and — as of today — will be working on kottke.org as my full-time job. And I need your help. ” [source]
zenhabits.net (2008)
“I’m officially a ProBlogger now. Yesterday morning, I turned in my resignation from my day job” [source]
getrichslowly.org (2007)
“After months of deliberation, I’ve decided to quit my job at the family business…. GRS currently has 35,000 subscribers and generates $5,000 in monthly revenue.” [source]
TechCrunch.com (2006)
“I started writing TechCrunch one year ago, on June 11, 2005. Looking back, it’s been the best year of my life…TechCrunch serves 1-2 million page views per month. TechCrunch is now my full time job, and then some.” [source]
readwriteweb.com (2006)
“it took 3 whole years for Read/WriteWeb to go from ‘hobby’ to full-time job.” [source]
GreatDay.com (2000)
“Although it didn’t start out that way, The Daily Motivator is now my full-time job. Back in 1995 I started writing the messages as part of another website. Within a few months, the response was so positive that The Daily Motivator took on a life of its own. After five years or so, subscription sales and book sales were providing a modest income, and since that time the website has grown to the point where I am able to devote all my working hours to it.” [source]
PlentyofFish.com (2006)
“I was making around 4k a month off the site and i quit my job to do it full time.” [source]
Craftster.com (2006)
“When I was working a regular full-time day job I constantly dreamed of working for myself at something craft-related. And Craftster, much to my surprise, made this possible.” [source]
PopSugar.com (2007)
Though a propensity for gossip typically motivates gossip bloggers, many are learning to cash in on their hobby. That’s what Lisa Sugar, 28, wants to do with her new blog, popsugar, which has grown from 200 to 13,000 unique visitors a week since it appeared in March, according to the site. The self-described “media junkie” and Maryland native spends at least 40 hours a week researching and writing the blog on top of her full-time job as a media planner in San Francisco. [source]
Related Posts
- Ford (2025)
- Pretext (2025)
- Download this Blog (2024)
- Breck's Lab (2024)
- A Higher Language (2024)
- Blog Posts, Sorted by Sleep (2024)
- Blogging as Therapy (2024)
- Words are Worse than Weights (2024)
- Writing in 2024 (2024)
- Many Narratives. All true. (2023)
- Walking and other invisible tools of thought (2023)
- Aftertext (2021)
- Write Thin to Write Fast (2021)
- Some old blogs (2021)
- Strong Advice (2021)
- Scroll Beta (2021)
- Dataset Needed (2020)
- If stories are lies why do they work? (2020)
- Dreaming of a Logic Checked Language (2020)
- English cannot encode Real News (2019)
- Narratives Misrepresent Complex Systems (2012)
- Publishing More (2012)
- Naming Things (2012)
- If you can explain something logically, you can explain it simply (2010)
- Why You Shouldn't Save Blogging for Old Age (2009)
- Fiction or Nonfiction? (2009)
- I'm Back (2009)
- I guess the time has come (2007)
Note: I imported this post from my original Wordpress blog.
May 14, 2008 — The other day I wrote a post on How much Gas Americans use per day. The answer is 400 Million Gallons. A reader wanted to know how much gas the whole world consumes in a day. The answer is about 83 millon bbl’s. One bbl = 42 gallons, so the world consumes about 3.5 billion gallons of gas per day. That means the United States consumes 11% of the total gas consumed per day.
400 million gallons is equal to:
1.5 million cubic meters. 2.56 billion 20oz bottled waters. 400 million gallons of milk.
There are 1.3 quadrillion gallons of water in Lake Michigan. One quadrillion equals 1,300 trillion. Or 1,300,000,000,000,000. If America had an oil supply of 1.3 quadrillion gallons, and consumed 400 million gallons per day, it would take 8,904 years for us to run out. If the world had an oil supply as big as lake Michigan it would last for 890 years.
Americans use a lot of gas. The world uses a lot of gas. But the world is a big place and there’s a lot to go around.
Note: I imported this post from my original Wordpress blog.
May 8, 2008 — xirium posted a tarball of all the individual profile pages for HackerNews readers(minus lurkers and those who joined after 05/07/2008). I was curious what insights, if any, could be gleamed from analyzing the data. My findings are below. I could have figured out more interesting things if I also included posts in my data, but I was looking for something simple to work on. BTW, to get the data into a table I wrote a simple python script to parse the html files. The source code is at the bottom. Or you can download the resulting dataset as an excel file.
General Composition of the Dataset
There are 7,159 users in this dataset.
The newest user joined 1 day ago and the oldest user(pg) joined 563 days ago(about 19 months ago, appx. 11/2006).
It was 4 days before the second user joined.
Between days 563 and 441, there were only 34 users. I am guessing this was the beta period. You can easily see the beta period on the right in the picture below.
[Missing chart] Karma by Join Date
You can also see some large outliers who have a ton of karma. The largest outliers are:
Registration Trends
193 days(8 months) is the average elapsed time since joining. The median is 191 days.
While signups aren’t particularly skewed to one side, there are definitely periods of higher growth.
There are 3 major periods of growth centered around approximately 390 days ago, 220 days ago, and in the past 30 days. The YC deadline for Summer 2007 was 4/2/07 (~390 days ago). The deadline for Winter 2008 was October 11,2007 (~220 days ago). The deadline for Summer 2008 was 4/2/2008(~ 30 days ago). I think it’s fair to conclude that when YC is gearing up to fund a new batch of startups HN signups go up significantly.
BTW, the deadline for Winter 2007 was 10/18/2006 (over 500 days ago and thus before HN was public).
[Missing chart] Hacker News Date Joined Distribution
OOPS! Missing Data
I wanted to see the effects of the first mention of Hacker News in Techcrunch. The results were surprising–I realized this dataset is far from complete. The Techcrunch article was about 60 days ago and you can see a slight jump in registrations below. But only 32 new members from a Techcrunch article? I couldn’t believe it. So I used Search Y Combinator to see if there was any mention of the traffic bump from TC. There was, and pg reported that there were 258 new accounts within 24 hours of the TC article. So this dataset is missing about 88% of new members from that period. So obviously xirium’s dataset is not the complete user list(unless there are thousands of lurkers). He may have mentioned that, I’m not sure.
[Missing chart] Busted Data
Karma/Joined Correlation
Their is a slight positive correlation between karma and joined. In other words, the longer you’ve been a member, the higher your karma will be on average. However, a low R2 value indicates that the date joined isn’t a significant predictor of karma. See the image below(extreme outliers removed).
[Missing chart] Karma by Joined
Average Karma Per Day
The rookies have a pretty good batting average in terms of average karma per day. But just like in the major leagues, it’s hard to maintain that and there is a negative correlation between membership duration and karma per day average. But even here, length of time isn’t a good predictor of karma per day average.
[Missing chart] Average Karma Per Day
About field filled out?
1303 have an about page; 5856 don’t. This works out to 18.2% versus 81.8%. The longer someone has been a member, the more likely they are to have filled out the about section. Although the correlation is positive, the length of time someone has joined is not a great predictor of whether or not they have an about page.
[Missing chart] About Page by Join Date
A better predictor of the about page binary is their karma level. Once again, however, not a great predictor.
[Missing chart] Fit about by karma
Conclusions
What did I learn? Honestly I did this mainly to refamiliarize myself with JMP. I didn’t really expect to find a whole lot of interesting things, and found what I expected. Seeing the beta period was cool, as well as the outliers. I also liked discovering that this was an incomplete dataset. The most interesting thing was definitely how memberships shot up during YC app periods.
Python Script to parse xirium’s original tarball into a CSV file:
import os
files = os.listdir(os.getcwd())
csv = open(”csv2.csv”,’w')
sep = “;”
term = “\n”
for i in files :
if i[-4:] != ‘html’ :
continue
f=open(i, ‘r’)
contents = f.read()
start = contents.find(”user:”)+14
if start < 100 : ## a couple files are messed up
print i
print start
continue
end = contents.find(”</td>”,start)
user = contents[start:end]
start = contents.find(”created:”)+17
end = contents.find(”</td>”,start)
created = contents[start:end]
start = contents.find(”karma:”)+15
end = contents.find(”</td>”,start)
karma = contents[start:end]
start = contents.find(”about:”)+15
end = contents.find(”</td>”,start)
about = contents[start:end]
about = about.replace(”\n”,”<br>”)
about = about.replace(”\r”,”<br>”)
about = about.replace(”;”,”")
csv.write(user + sep + created + sep + karma + sep + about + term)
f.close()
csv.close()
Updates:
I didn’t realize xirium collected the profile pages on different days. Skews things a bit.
[Missing chart] log(karma) by joined
Note: I imported this post from my original Wordpress blog.
September 28, 2007 — So after 1 year, my Fantasy Stock Portfolio returned a little over 150%, which was enough to capture 1st place. We used the MarketWatch game. At first I had no competition among our friends in our private game, although Conor(and his risky day trading in the subprime market) spiked at one point and finished around 80%. I lucked out thanks to a hot tech market and picking some of the best companies in that. Not a single pick lost money(though this is lucky).
My primary investments that I held for the duration of the game were RIMM and AAPL. I also held MSFT and HPQ for the duration, though in smaller quantities. I dabbled with maybe 2 or3 other stocks. I made a bit on GOOG but thought the volatility was too much and while I can clearly see the untapped markets for RIMM and AAPL products, I think AdSense is nearing saturation. HPQ has impressed me the past few years with their well designed products(which I own a few of) and I think they can be the AAPL of the PC world. MSFT makes so much money, has brilliant people, and the new Office 2007 rocks(even if I’m not too impressed with Vista). 360 is also a great product. MSFT is not gonna fall anytime soon.
Besides those, I had some boring non tech investments. My strategy with investing is simple. I know tech well, so if I’m going to invest in something that is riskier than Indexes or CD’s, it’s going to be what I know best: tech. And I buy and hold for the long run. Partly because it makes sense, partly because I like doing things that don’t take much time. And trading is a hassle.
I’m mostly proud of the fact that my returns were high while I maintained a good Sharpe Ratio and I didn’t carry a whole lot of risk.
How did my real portfolio do? Pretty much mirrored my virtual portfolio. Except the commas and trailing zeros were very, very much different. :(
If someone had given me $1,000,000 a year ago, I would be writing this from a tropical resort right now. Instead, I’ve earned enough to maybe splurge on the fries when I order my next hamburger. But it’s all good because I don’t need much money to do what I love. And because I’m totally going to win the lottery soon.
Note: I imported this post from my original Wordpress blog.
September 13, 2007 — Every successful person in the startup world will tell you that the most important part of any startup is the team. From my own experiences, I wholeheartedly agree. But everyday I talk to people who think the most important thing is the idea. For instance, I just met a nice young woman at Logan Airport. She was wearing a well-pressed white blouse and grey skirt, dressed to impressed for her job at a prominent Boston-based health care consulting firm. We started talking about Facebook, and she repeated something I’ve heard at least a dozen times “[Zuckerberg] is going to make so much money. Facebook was such a simple idea. I wish I had thought of that.” I smiled and agreed pleasantly while trying hard not to roll my eyes.
Facebook is amazing, don’t get me wrong. But it is so much more than one idea. By this point I would say that millions of ideas have gone into Facebook. Thousands have been executed and are part of the site and company; many more have been considered, iterated, and shed. And most importantly, the Facebook team(now at over 300) has spent countless hours engaged in hard at sometimes grueling work. To say that Zuckerberg is going to make a lot of money because of one idea is to ignore 99.9% of the reasons behind Facebook’s success.
I am very skeptical that any one idea–no matter how great–is worth much. Even the “simple, big ideas”, are worth squat on their own.
My philosophy on ideas is this:
- Some ideas are more important than others. These are the simple, general, big ideas. These ideas don’t bring in any money, and are worth very little by themselves.
- The simple, general, big ideas each require dozens of more medium-sized ideas. These ideas put together are worth more than the big ideas, but still not much.
- The medium sized ideas each require hundreds of smaller ideas. These ideas are the ones that finally allow a startup to actually make money. These ideas put together are worth more than the big and medium ideas combined.
- Coming up with all of these ideas takes creativity and intelligence. Some people are better at it than others.
- Finally, coming up with and executing every single one of these ideas requires something that not many people like to admit: work. Without work all of these things are worthless.
So, while most people can identify and easily understand the simple, general, big ideas that are behind successful companies, very few of them see the 99.9% or ideas and hard work that actually lead to these big ideas making money. And very few people have the ability to do more than simply come up with simple, general, big ideas, which I believe are worthless because they are always unrealistic until that 99.9% of the work is done to make them real.
While any one person can come up with a simple, general, big idea, it takes a team of smart, cooperative, hard-working people to do the 99.9% of the idea creation and work that turns that big idea into a money making reality. That’s why the team is so much more important than any idea.
I think the best entrepreneurs are the ones who can build and lead a team to ensure that the 99.9% gets done so that the .1% of the company that is the big idea becomes reality.
Note: I imported this post from my original Wordpress blog.
while ($brecks_programming_skills < ‘great’) { write_learning_how_to_program_series(); }
August 28, 2007 — I thought today I’d write my first post on programming. I have always been very passionate about computers, but to be honest my programming skills are embarrassingly weak. Mainly it’s because I haven’t spent any time developing them. Although I wrote my first webpage in 1996, it wasn’t until 2002 at Duke that I wrote my first computer program.
Until I took Computer Science 6 that fall semester in 2002, computers were still pretty much a mystery to me. Luckily that class was a complete eye-opener and advanced me light-years ahead to where I wanted to be. Well, almost advanced me light years ahead. Unfortunately for my programming skills, I spent the next four years enjoying life and learning about non-digital things.
Then during a trip to San Francisco in November of 2006, a number of friends, after discussing my career goals, strongly encouraged me to learn the technical stuff(thanks for the solid advice ya’ll, particularly Mareza). So I heeded their advice, and rather than enjoy my Friday afternoons during my Senior Spring Semester I learned how to count in binary, construct logic gates, and draw circuit diagrams in my first electrical engineering class. It wasn’t anything advanced, but it reignited my deep passion for the digital world.
It’s funny, now that I’m out of school, I finally have time to learn. I couldn’t be more excited to have graduated college and to have stumbled into such a great opportunity with SeeMeWin. Now I have all day to program and learn new things with a terrific team of smart engineers.
Besides learning on the job, I’m trying to spend time in new areas that normally I wouldn’t approach. Today for instance, I needed a break from the daily PHP grind today so I downloaded Eclipse(hadn’t used that since CompSci6) and started reacquainting myself with C++ and the whole “not-interpretted-at-run-time & statically typed” thing. Not a huge fan of C++ I must say. I know programs in C++ would execute faster, would probably be necessary in order to scale a high traffic site(unless servers could just be added), and there are a whole ton of cool libraries that can be used, but can someone tell me if there’s a good reason to spend much time learning something like C++? It seems between PHP, Python, JavaScript, and Flash, I can pretty much create everything I would need to create. And with the price of equipment falling, and the interpreters of these languages getting more optimized themselves, is there a good reason to learn C++ well? I know I’m probably wrong, so I’d like to defer to some people with more knowledge than I.
So after brashly deciding C++ was outdated, I opted instead to fiddle with Ruby. So far, I’m pretty impressed. Stay tuned as I expect to write my first side project with Rails sometime within the next month or two.
–Breck
Note: I imported this post from my original Wordpress blog.
August 24, 2007 — For a few years, GoDaddy kept alerting me that BreckYunits.com was available and I should buy fast before someone else does! Lucky for me, all the other Breck Yunits’ out there weren’t getting the same alerts. Enjoy BreckYunits.info, suckers!!!
Anyway, I finally realized that I had close to four billion email addresses and changing the forwarding for them all would get really time consuming if I ever had to change my main Gmail address. I hope I don’t have to change my Gmail address ever, but with the recent GrandCentral fiasco, I realized hoping is not the best strategy. So what I decided to do was setup breck@breckyunits.com and have all my mail forwarded to that address, and then on to my Gmail. I don’t ever plan on changing my name, so I think I should be set for life. Nice.
But since now I’ll be giving out an email address with BreckYunits.com, it’s pretty much required I put something up here. So welcome to my blog. I plan to post excerpts from that big novel I’ve been working on, you know, the one with the protagonist and antagonist, friends become enemies, enemies become friends, everyone’s better for the experience book? Or maybe just random thoughts on startups, hacking, and life that I think are interesting.
-Breck
PS, Be the first to email me at my new address: breck@breckyunits.com . See if you can do it before my first botnet spam email arrives!
Related Posts
Note: I imported this post from my original Wordpress blog.